



科學家正利用一種稱為深度強化學習(DRL:Deep Reinforcement Learning)的人工智慧技術來保護電腦網絡,並邁出了關鍵一步。

當在嚴格的模擬環境中面對複雜的網路攻擊時,深度強化學習在95%的時間內有效阻止對手達到目標。測試結果為自主人工智慧在主動網路防禦中發揮作用提供了希望。
美國能源部太平洋西北國家實驗室(PNNL)的科學家在一份研究論文中記錄了他們的發現,並於2月14日在華盛頓特區人工智慧促進協會年會期間,在網路安全人工智慧研討會上介紹了他們的工作。
專案起點是開發一個模擬環境,以測試涉及不同類型對手的多階段攻擊場景。為實驗創造這樣一個動態攻防模擬環境本身就是一個成果。該環境為研究人員提供了一種在受控測試環境下比較不同基於AI防禦有效性的方法。
這些工具對於評估深度強化學習演算法的表現至關重要。這種方法正在成為網路安全專家的強大決策支援工具,DRL是一個具有學習能力、適應快速變化的環境和自主決策能力的防禦模式。以往其他形式的人工智慧是偵測入侵或過濾垃圾郵件的標準,但深度強化學習擴展了防禦者在與對手的日常對峙中協調順序決策計畫的能力。
深度強化學習提供了更聰明的網路安全、更早發現網路環境變化的能力,以及採取先發制人措施挫敗網路攻擊的機會。
介紹團隊工作的資料科學家Samrat Chatterjee表示:「一個有效的網路安全人工智慧代理需要根據它所能收集的資訊以及它所做出的決策結果來感知、分析、行動和適應。」「深度強化學習在這個領域具有巨大的潛力,因為系統狀態和可選擇行動的數量可能很大。」
DRL結合了強化學習(RL)和深度學習(DL),特別適用於需要在複雜環境中做出一系列決策的情況。就像剛開始走路的孩子從磕磕碰碰和擦傷中學習一樣,基於深度強化學習(DRL)的演算法是透過對好決策的獎勵和對壞決策的懲罰來訓練的:導致理想結果的良好決策得到積極獎勵(以數值表示)的支持;透過扣除獎勵來阻止導致不良結果的不良選擇。
該團隊使用開源軟體工具包OpenAI Gym作為基礎,創建了一個自訂的受控模擬環境,以評估四種深度強化學習演算法的優缺點。
同時使用了MITRE公司開發的MITRE ATT&CK框架,並結合了三個不同對手部署的7種戰術和15種技術。防禦者配備了23個緩解措施,試圖阻止或阻擋攻擊的進展。
攻擊的階段包括偵察、執行、持久性、防禦規避、指揮和控制、收集和過濾(當資料從系統中傳輸出去)等戰術。如果對手成功進入最後的過濾階段,則攻擊被記錄為獲勝。
Chatterjee表示:「我們的演算法在競爭環境中運行,這是一場與意圖破壞系統的對手的競爭。是一種多階段攻擊,在這種攻擊中,對手可以追求多種攻擊路徑,這些路徑可能會隨著時間的推移而改變,因為他們試圖從偵察轉向利用。我們的挑戰是展示基於深度強化學習的防禦如何阻止這種攻擊。”
DQN優於其他方法
該團隊基於四種深度強化學習演算法:DQN(深度Q-Network)和其他三種變體來訓練防禦性代理,接受了有關網路攻擊的模擬資料訓練,然後測試了他們在訓練中沒有觀察到的攻擊。
DQN表現最好:
#低複雜的攻擊:DQN在攻擊階段中途阻止了79%的攻擊,在最後階段阻止停止了93%的攻擊。
中等複雜的攻擊:DQN在中途阻止了82%的攻擊,在最後階段阻止了95%的攻擊。
最複雜的攻擊:DQN在中途阻止了57%的攻擊,在最後階段阻止了84%的攻擊,遠高於其他三種演算法.
Chatterjee說:「我們的目標是創建一個自主的防禦代理,它可以了解對手最有可能的下一步行動,並對其進行規劃,然後以最佳方式做出反應,以保護系統。」
儘管取得了進展,但沒有人願意將網路防禦完全交給人工智慧系統。相反,基於DRL的網路安全系統需要與人類協同工作,前PNNL的合著者Arnab Bhattacharya說。 「人工智慧可以很好地防禦特定的戰略,但不能很好地理解對手可能採取的所有方法。我們離人工智慧取代人類網路分析師的階段還很遠。人類的反饋和指導很重要。」
除了Chatterjee和Bhattacharya,研討會論文的作者還包括PNNL的Mahantesh Halappanavar和前PNNL科學家Ashutosh Dutta。這項工作由能源部科學辦公室資助,推動這項具體研究的一些早期工作是由PNNL的“科學中的人工推理數學”計劃通過實驗室指導研究與開發計劃資助的。
#以上是網路安全保衛者正在擴展他們的AI工具箱的詳細內容。更多資訊請關注PHP中文網其他相關文章!

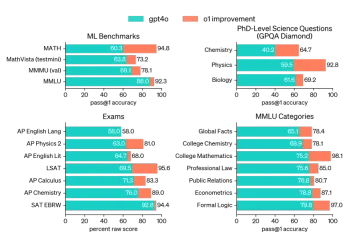 AV字節:Openai' apple apple and visual ai等 - 分析vidhyaApr 12, 2025 am 09:38 AM
AV字節:Openai' apple apple and visual ai等 - 分析vidhyaApr 12, 2025 am 09:38 AM介紹 本週,人工智能(AI)世界上充滿了重大更新。從OpenAI的O1模型展示高級推理到蘋果的開創性視覺智能技術,Tech
 如何監視生產級代理抹布管道?Apr 12, 2025 am 09:34 AM
如何監視生產級代理抹布管道?Apr 12, 2025 am 09:34 AM介紹 2022年,Chatgpt的推出徹底改變了技術和非技術行業,從而使個人和組織具有生成性AI的能力。在2023年,努力集中在利用大語言模式
 如何使用Star模式優化數據倉庫?Apr 12, 2025 am 09:33 AM
如何使用Star模式優化數據倉庫?Apr 12, 2025 am 09:33 AMStar模式是用於數據倉庫和商業智能的高效數據庫設計。它將數據組織到鏈接到周圍尺寸表的中心事實表中。這種類似恆星的結構簡化了複雜Q
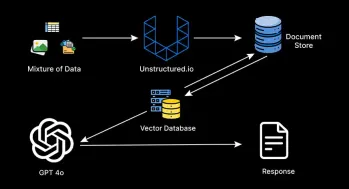
 代理抹布系統如何改變技術?Apr 12, 2025 am 09:21 AM
代理抹布系統如何改變技術?Apr 12, 2025 am 09:21 AM介紹 人工智能進入了一個新時代。模型將基於預定義的規則輸出信息的日子已經一去不復返了。當今AI中的尖端方法圍繞抹布(檢索-Aigmente)
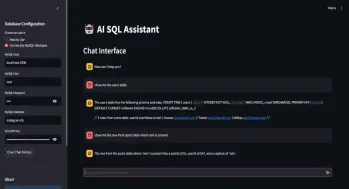 SQL自動生成查詢助手Apr 12, 2025 am 09:13 AM
SQL自動生成查詢助手Apr 12, 2025 am 09:13 AM您是否希望您可以簡單地與數據庫交談,用簡單的語言提出問題,並在不編寫複雜的SQL查詢或通過電子表格進行分類的情況下獲得即時答案?使用Langchain的SQL工具包,Groq A
 閱讀AI索引2025:AI是您的朋友,敵人還是副駕駛?Apr 11, 2025 pm 12:13 PM
閱讀AI索引2025:AI是您的朋友,敵人還是副駕駛?Apr 11, 2025 pm 12:13 PM斯坦福大學以人為本人工智能研究所發布的《2025年人工智能指數報告》對正在進行的人工智能革命進行了很好的概述。讓我們用四個簡單的概念來解讀它:認知(了解正在發生的事情)、欣賞(看到好處)、接納(面對挑戰)和責任(弄清我們的責任)。 認知:人工智能無處不在,並且發展迅速 我們需要敏銳地意識到人工智能發展和傳播的速度有多快。人工智能係統正在不斷改進,在數學和復雜思維測試中取得了優異的成績,而就在一年前,它們還在這些測試中慘敗。想像一下,人工智能解決複雜的編碼問題或研究生水平的科學問題——自2023年
 開始使用Meta Llama 3.2 -Analytics VidhyaApr 11, 2025 pm 12:04 PM
開始使用Meta Llama 3.2 -Analytics VidhyaApr 11, 2025 pm 12:04 PMMeta的Llama 3.2:多模式和移動AI的飛躍 Meta最近公佈了Llama 3.2,這是AI的重大進步,具有強大的視覺功能和針對移動設備優化的輕量級文本模型。 以成功為基礎


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

Atom編輯器mac版下載
最受歡迎的的開源編輯器

MantisBT
Mantis是一個易於部署的基於Web的缺陷追蹤工具,用於幫助產品缺陷追蹤。它需要PHP、MySQL和一個Web伺服器。請查看我們的演示和託管服務。

ZendStudio 13.5.1 Mac
強大的PHP整合開發環境

EditPlus 中文破解版
體積小,語法高亮,不支援程式碼提示功能

SecLists
SecLists是最終安全測試人員的伙伴。它是一個包含各種類型清單的集合,這些清單在安全評估過程中經常使用,而且都在一個地方。 SecLists透過方便地提供安全測試人員可能需要的所有列表,幫助提高安全測試的效率和生產力。清單類型包括使用者名稱、密碼、URL、模糊測試有效載荷、敏感資料模式、Web shell等等。測試人員只需將此儲存庫拉到新的測試機上,他就可以存取所需的每種類型的清單。

