
mysql索引為什麼快

- 青灯夜游原創
- 2023-04-12 15:24:402364瀏覽
索引就是透過事先排好序,以便在尋找時可以應用二分查找等高效率的演算法。一般的順序查找,複雜度為O(n),而二分查找複雜度為O(log2n);當n很大時,二者的效率相差及其懸殊。

本教學操作環境:windows7系統、mysql8版本、Dell G3電腦。
Mysql 作為互聯網中非常熱門的資料庫,其底層的儲存引擎和資料檢索引擎的設計非常重要,尤其是 Mysql 資料的儲存形式以及索引的設計,決定了 Mysql 整體的資料檢索效能。
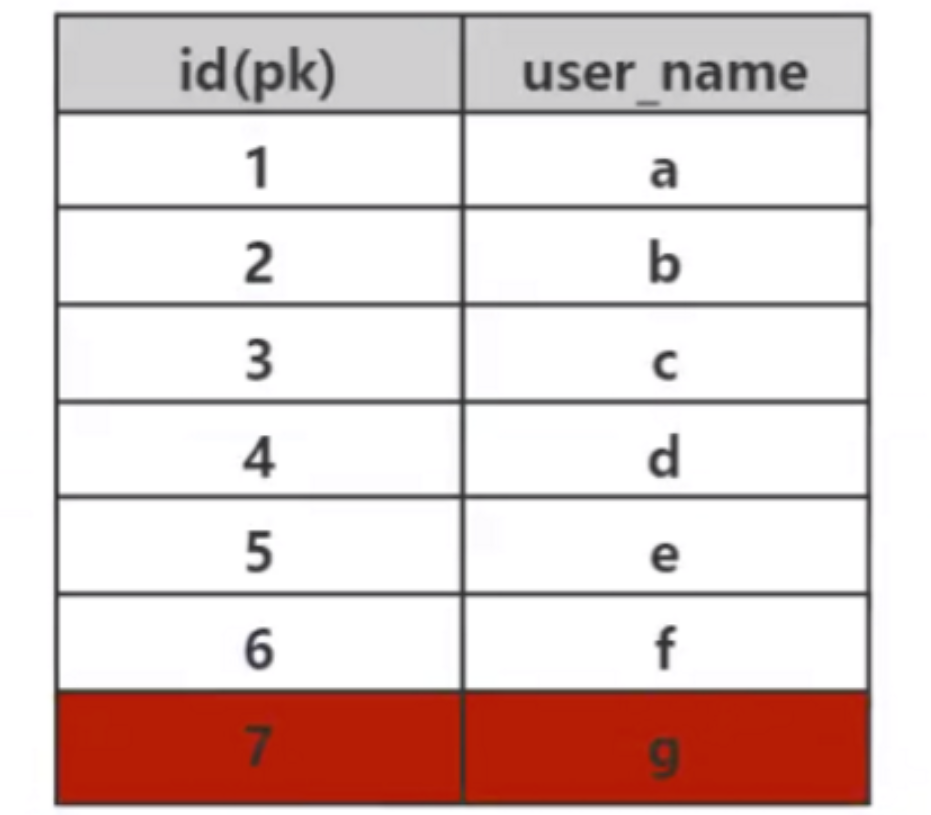
我們知道,索引的作用是做資料的快速檢索,而快速檢索的實作的本質是資料結構。透過不同資料結構的選擇,實現各種資料快速檢索。在資料庫中,高效的查找演算法是非常重要的,因為資料庫中儲存了大量數據,一個高效的索引可以節省巨大的時間。例如下面這個數據表,如果Mysql 沒有實作索引演算法,那麼查找id=7 這個數據,那就只能採取暴力順序遍歷查找,找到id=7 這個數據需要比較7 次,如果這個表儲存的是1000W 個數據,查找id=1000W 這個數據那就要比較1000W 次,這種速度是不能接受的。
一、Mysql 索引底層資料結構選型
雜湊表(Hash)
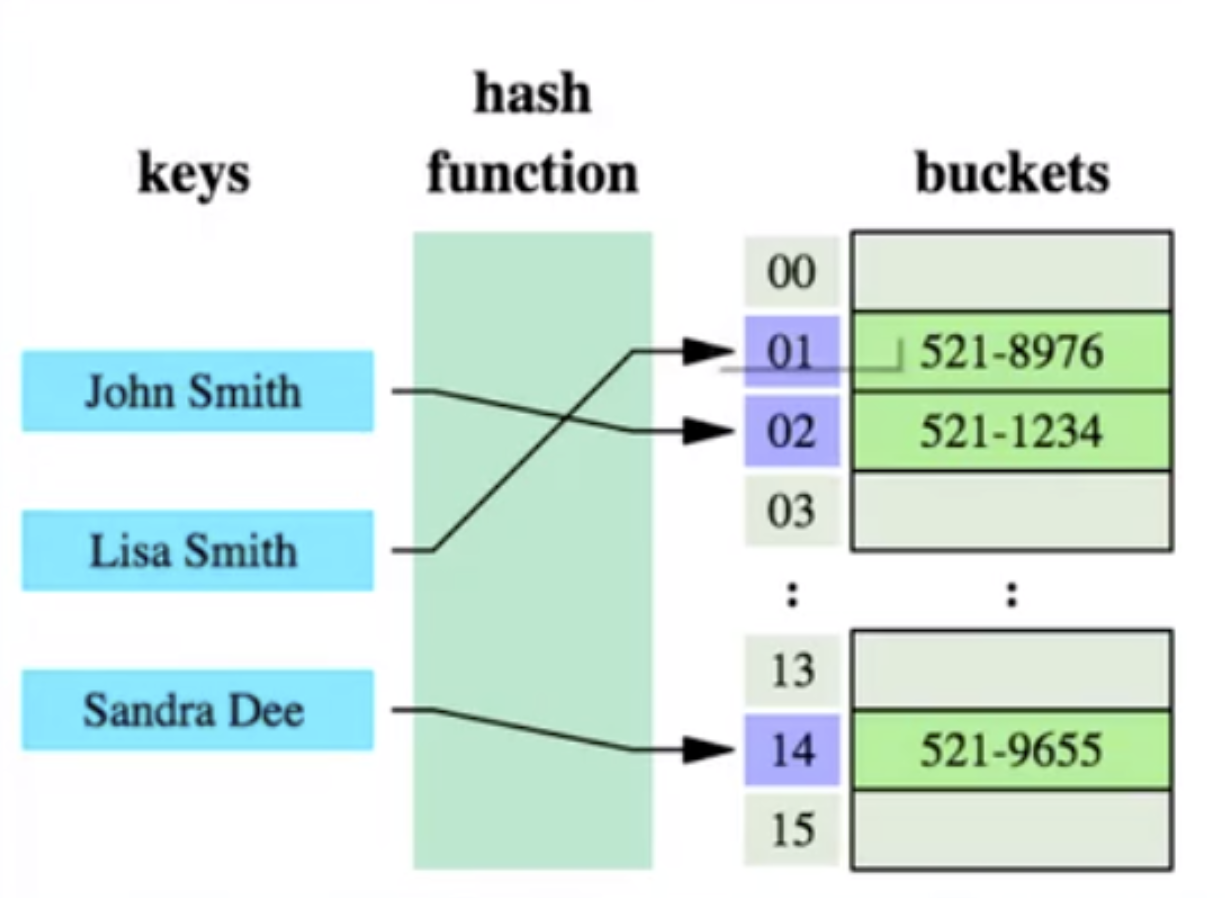
雜湊表是做資料快速檢索的有效利器。
雜湊演算法:也叫雜湊演算法,就是把任意值(key)透過雜湊函數轉換為固定長度的 key 位址,透過這個位址進行具體資料的資料結構。
考慮這個資料庫表user,表中一共有7 個數據,我們需要檢索id=7 的數據, SQL 語法是:
select * from user where id=7;
哈希演算法首先計算儲存id=7 的資料的物理位址addr=hash(7)=4231,而4231 映射的物理位址是0x77,0x77 是id=7 儲存的額資料的實體位址,透過該獨立位址可以找到對應user_name='g'這個資料。這就是哈希演算法快速檢索資料的計算過程。
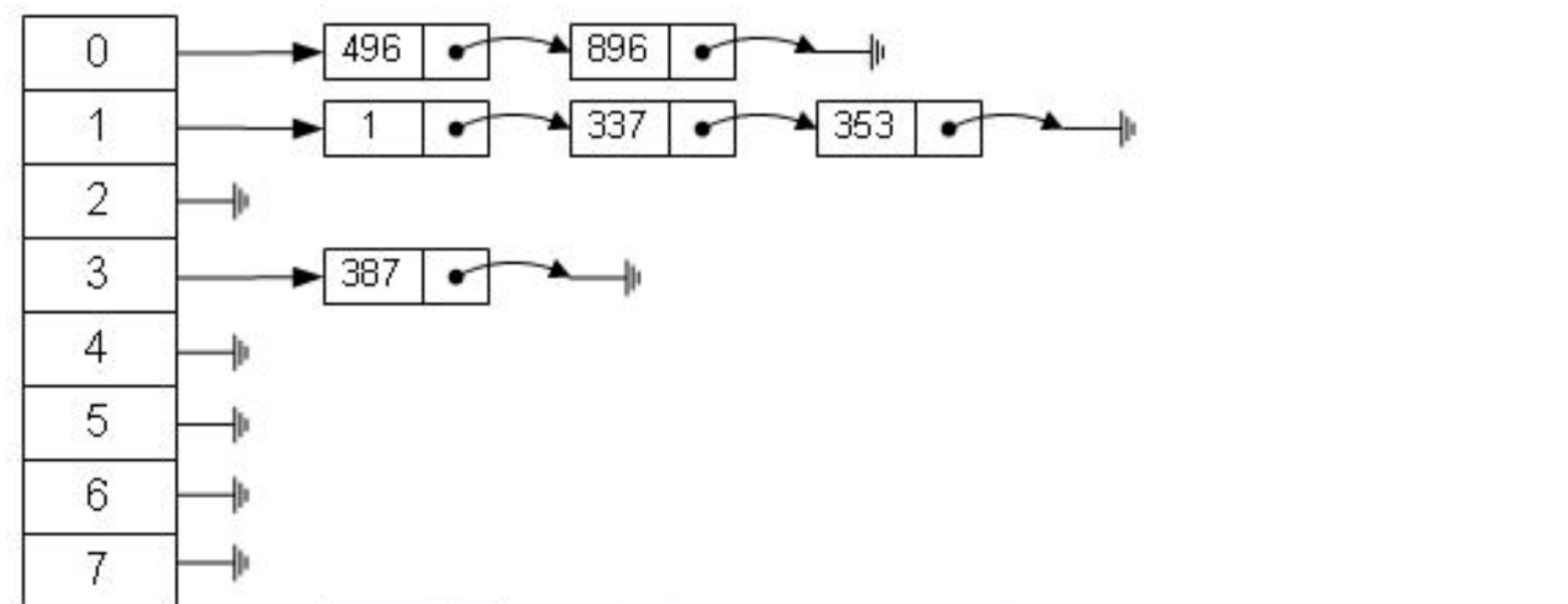
但是雜湊演算法有個資料碰撞的問題,也就是雜湊函數可能會對不同的key 會計算出同一個結果,例如hash(7)可能跟hash(199)計算出來的結果一樣,也就是不同的key 映射到同一個結果了,這就是碰撞問題。解決碰撞問題的一個常見處理方式就是鏈結位址法,也就是用鍊錶把碰撞的資料接連起來。計算雜湊值之後,還需要檢查該雜湊值是否存在碰撞資料鍊錶,有則一直遍歷到鍊錶尾,直達找到真正的 key 對應的資料為止。
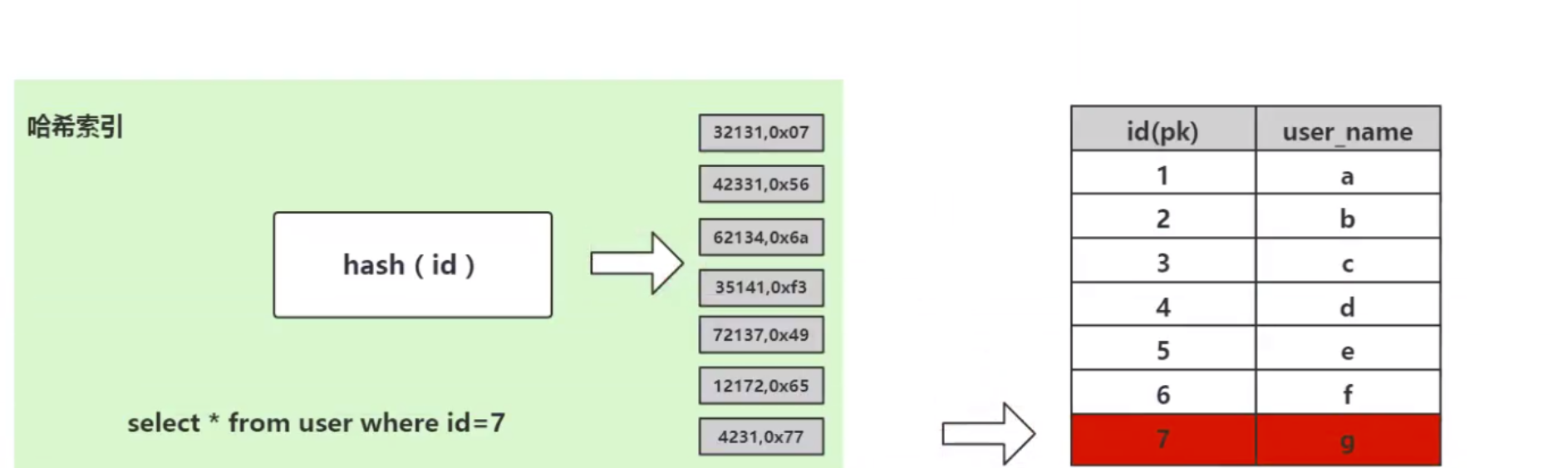
从算法时间复杂度分析来看,哈希算法时间复杂度为 O(1),检索速度非常快。比如查找 id=7 的数据,哈希索引只需要计算一次就可以获取到对应的数据,检索速度非常快。但是 Mysql 并没有采取哈希作为其底层算法,这是为什么呢?
因为考虑到数据检索有一个常用手段就是范围查找,比如以下这个 SQL 语句:
select * from user where id \>3;
针对以上这个语句,我们希望做的是找出 id>3 的数据,这是很典型的范围查找。如果使用哈希算法实现的索引,范围查找怎么做呢?一个简单的思路就是一次把所有数据找出来加载到内存,然后再在内存里筛选筛选目标范围内的数据。但是这个范围查找的方法也太笨重了,没有一点效率而言。
所以,使用哈希算法实现的索引虽然可以做到快速检索数据,但是没办法做数据高效范围查找,因此哈希索引是不适合作为 Mysql 的底层索引的数据结构。
二叉查找树(BST)
二叉查找树是一种支持数据快速查找的数据结构,如图下所示:
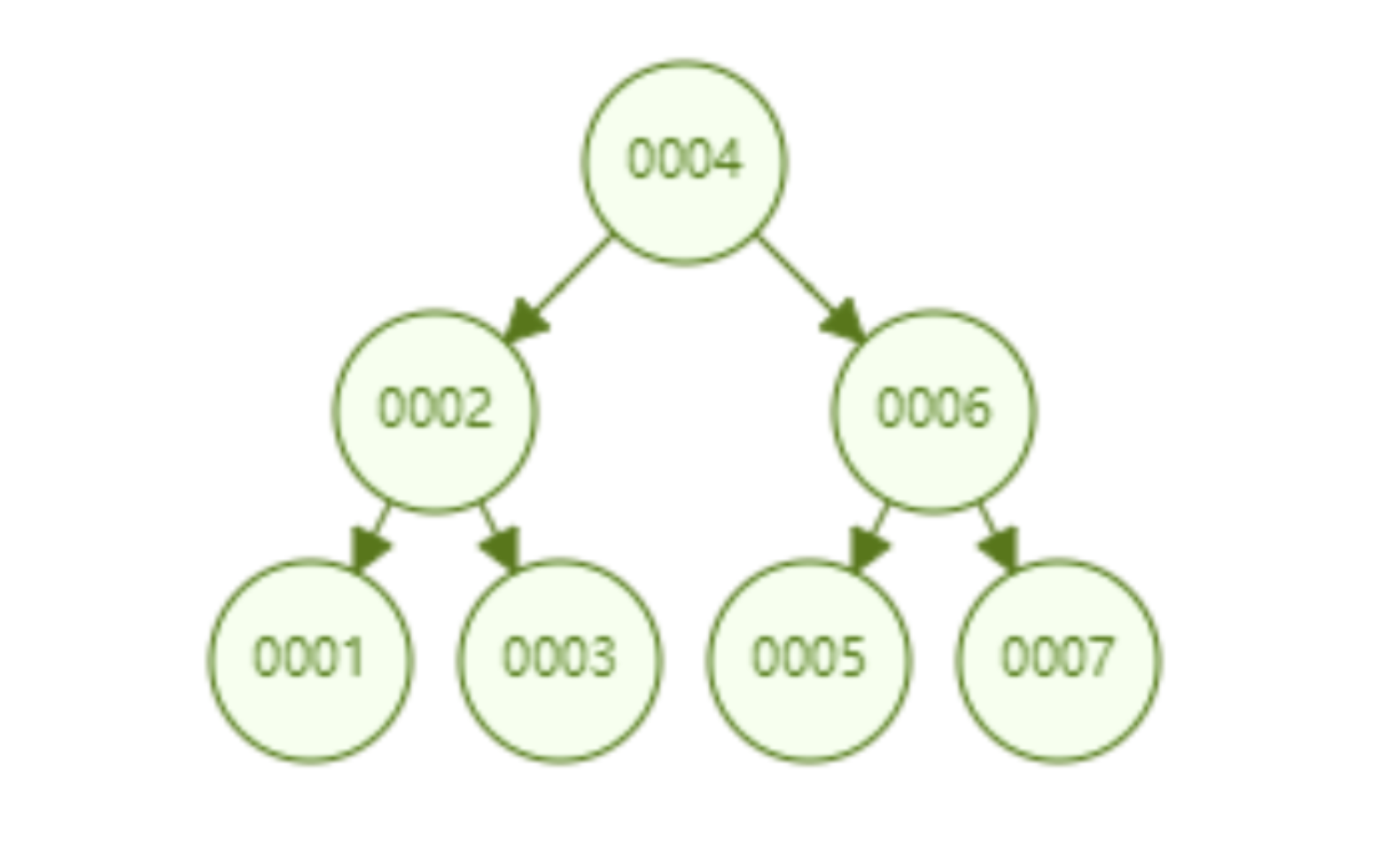
二叉查找树的时间复杂度是 O(lgn),比如针对上面这个二叉树结构,我们需要计算比较 3 次就可以检索到 id=7 的数据,相对于直接遍历查询省了一半的时间,从检索效率上看来是能做到高速检索的。此外二叉树的结构能不能解决哈希索引不能提供的范围查找功能呢?
答案是可以的。观察上面的图,二叉树的叶子节点都是按序排列的,从左到右依次升序排列,如果我们需要找 id>5 的数据,那我们取出节点为 6 的节点以及其右子树就可以了,范围查找也算是比较容易实现。
但是普通的二叉查找树有个致命缺点:极端情况下会退化为线性链表,二分查找也会退化为遍历查找,时间复杂退化为 O(N),检索性能急剧下降。比如以下这个情况,二叉树已经极度不平衡了,已经退化为链表了,检索速度大大降低。此时检索 id=7 的数据的所需要计算的次数已经变为 7 了。
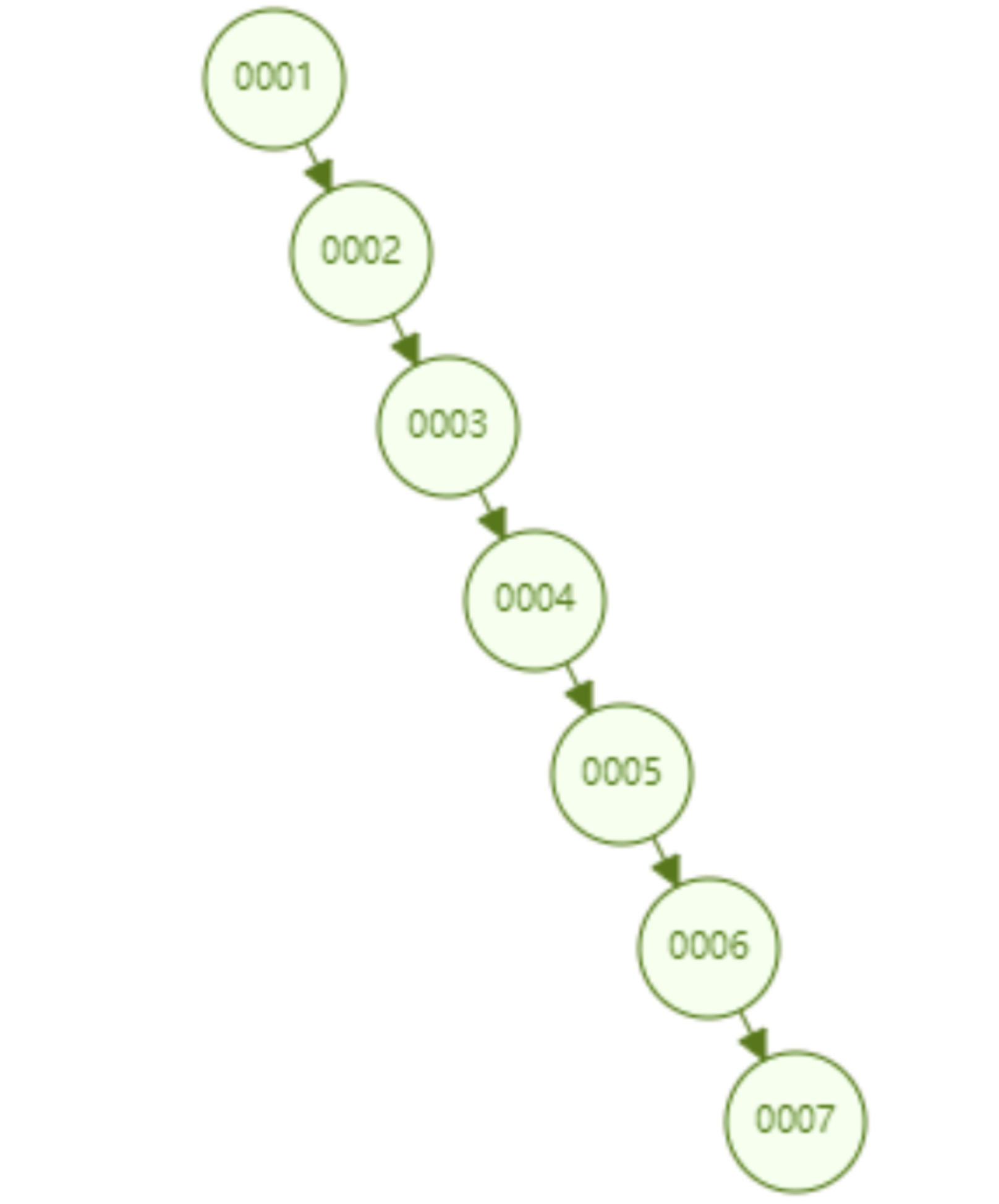
在資料庫中,資料的自增是一個很常見的形式,例如一個表的主鍵是id,而主鍵一般預設都是自增的,如果採取二元樹這種資料結構作為索引,那上面介紹到的不平衡狀態所導致的線性查找的問題必然出現。因此,簡單的二元查找樹有不平衡導致的檢索效能降低的問題,是無法直接用於實作 Mysql 底層索引的。
AVL 樹和紅黑樹
#二元查找樹有不平衡問題,因此學者提出透過樹節點的自動旋轉調整,讓二元樹始終保持基本平衡的狀態,就能保持二元查找樹的最佳查找效能了。基於這種想法的自調整平衡狀態的二元樹有 AVL 樹和紅黑樹。
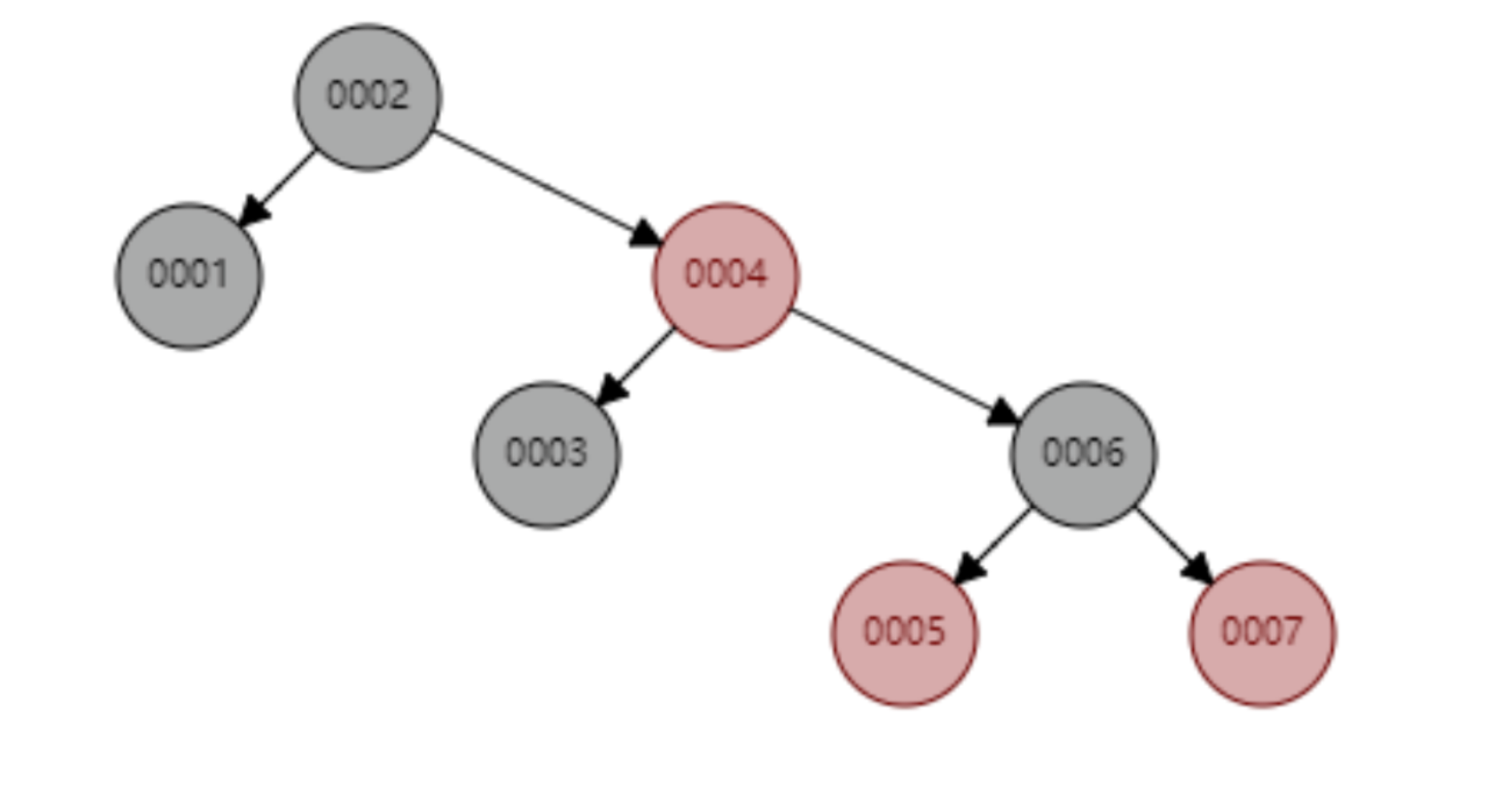
首先簡單介紹紅黑樹,這是一顆會自動調整樹形態的樹狀結構,例如當二元樹處於一個不平衡狀態時,紅黑樹就會自動左旋右旋節點以及節點變色,調整樹的形態,使其保持基本的平衡狀態(時間複雜度為O(logn)),也確保了查找效率不會明顯減低。例如從 1 到 7 升序插入資料節點,如果是普通的二元查找樹則會退化成鍊錶,但是紅黑樹則會不斷調整樹的形態,使其保持基本平衡狀態,如下圖所示。下面這個紅黑樹下查找 id=7 的要比較的節點數為 4,依然保持二元樹不錯的查找效率。
紅黑樹擁有不錯的平均查找效率,也不存在極端的 O(n)情況,那紅黑樹作為 Mysql 底層索引實現是否可以呢?其實紅黑樹也存在一些問題,觀察下面這個例子。
紅黑樹順序插入 1~7 個節點,找出 id=7 時需要計算的節點數為 4。
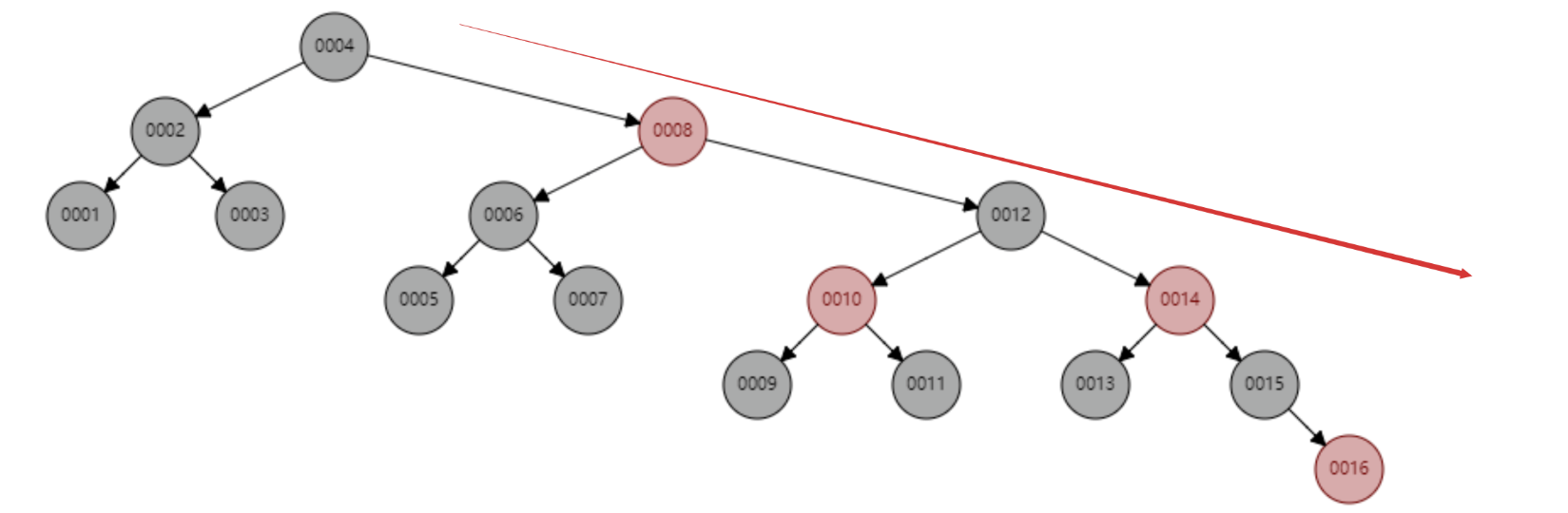
紅黑樹順序插入1~16 個節點,找出id=16 需要比較的節點數為6 次。觀察這個樹的形態,是不是當資料是順序插入時,樹的形態一直處於「右傾」的趨勢?從根本上看,紅黑樹並沒有完全解決二元查找樹雖然這個「右傾」趨勢遠沒有二元查找樹退化為線性鍊錶那麼誇張,但是資料庫中的基本主鍵自增操作,主鍵一般都是數百萬數千萬的,如果紅黑樹存在這種問題,對於查找性能而言也是巨大的消耗,我們資料庫不可能忍受這種無意義的等待的。
現在考慮另一個更嚴格的自平衡二元樹 AVL 樹。因為 AVL 樹是個絕對平衡的二元樹,因此他在調整二元樹的形態上消耗的表現會更多。
AVL 樹順序插入 1~7 個節點,找出 id=7 要比較節點的次數為 3。
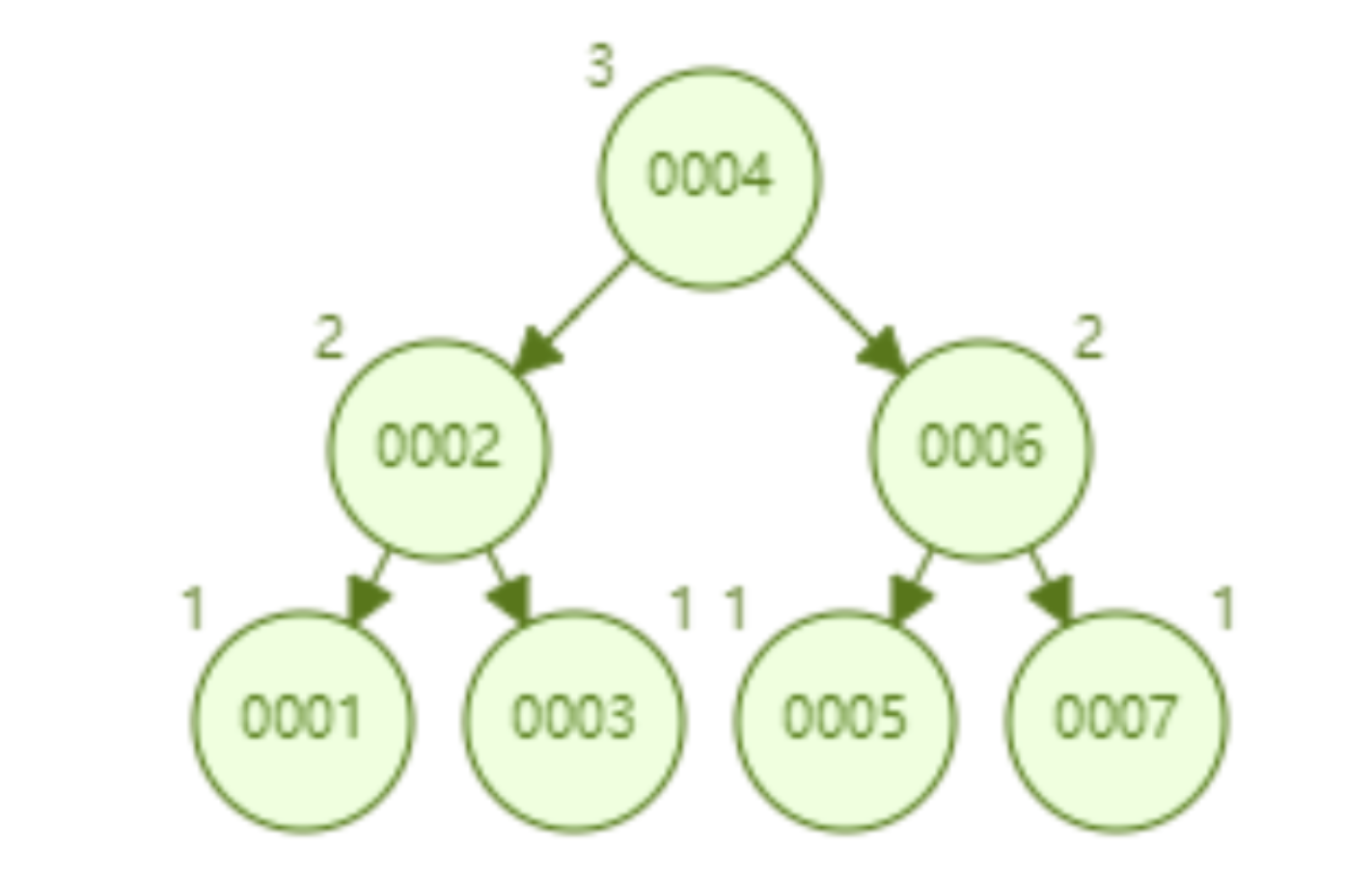
AVL 樹順序插入 1~16 個節點,找出 id=16 需要比較的節點數為 4。從尋找效率而言,AVL 樹查找的速度高於紅黑樹的尋找效率(AVL 樹是 4 次比較,紅黑樹是 6 次比較)。從樹的形態看來,AVL 樹不存在紅黑樹的「右傾」問題。也就是說,大量的順序插入不會導致查詢效能的降低,這從根本上解決了紅黑樹的問題。
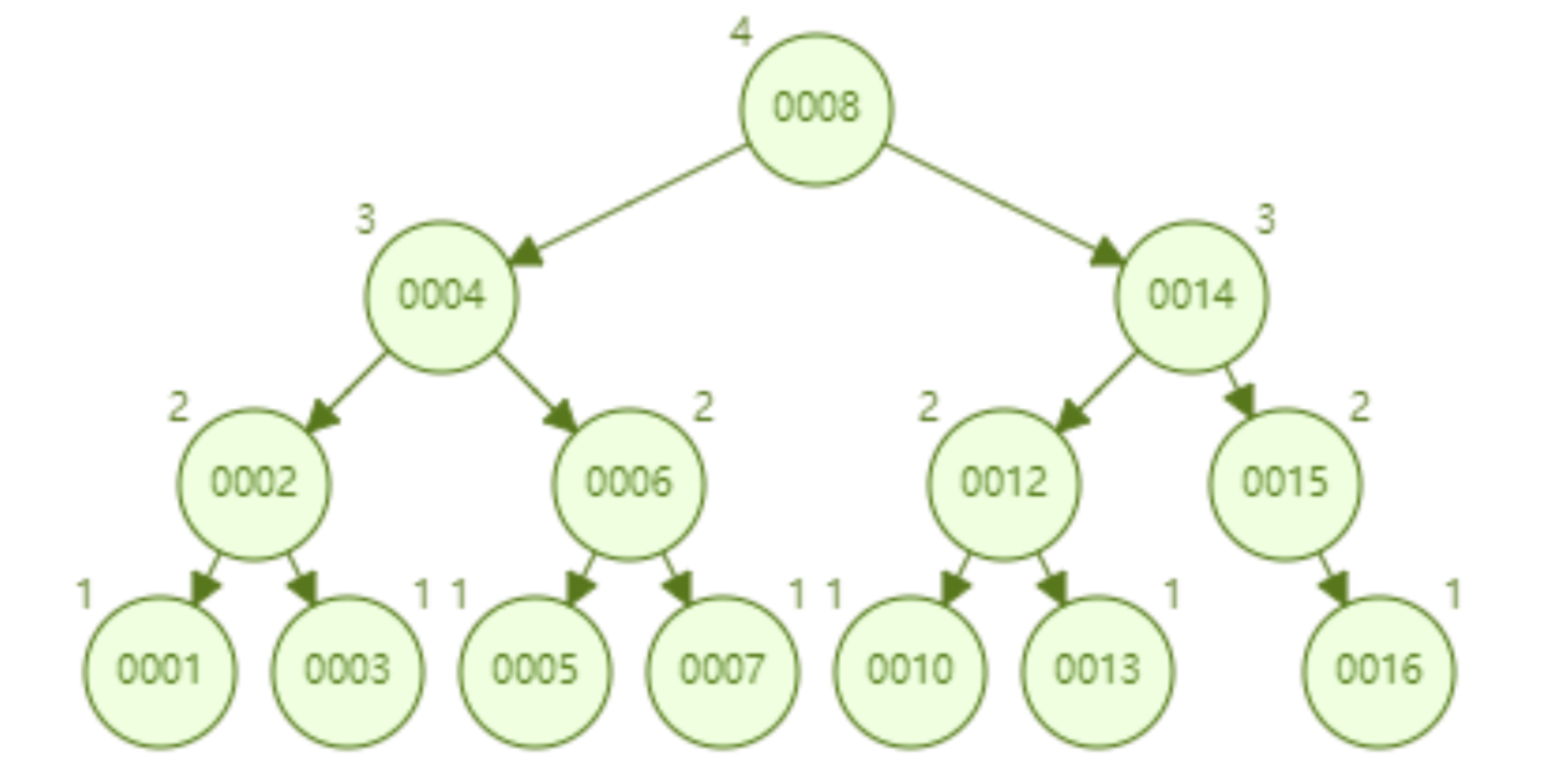
總結AVL 樹的優點:
- ##不錯的查找效能(O(logn)),不存在極端的低效率查找的情況。
B 樹
下面這個B 樹,每個節點限制最多儲存兩個key,一個節點如果超過兩個key 就會自動分裂。例如下面這個儲存了 7 個資料 B 樹,只需要查詢兩個節點就可以知道 id=7 這資料的具體位置,也就是兩次磁碟 IO 就可以查詢到指定數據,優於 AVL 樹。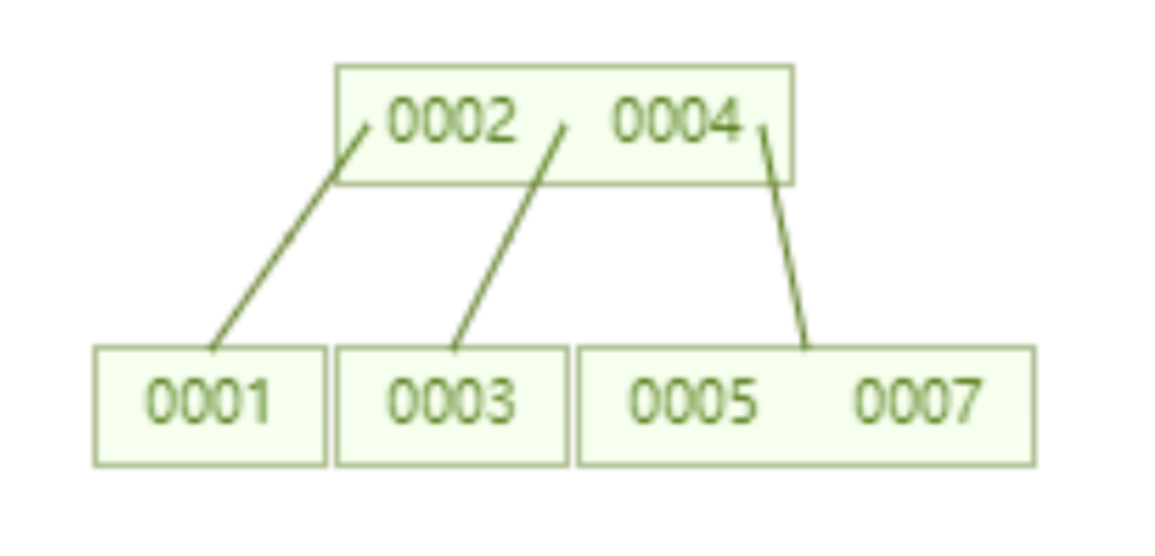
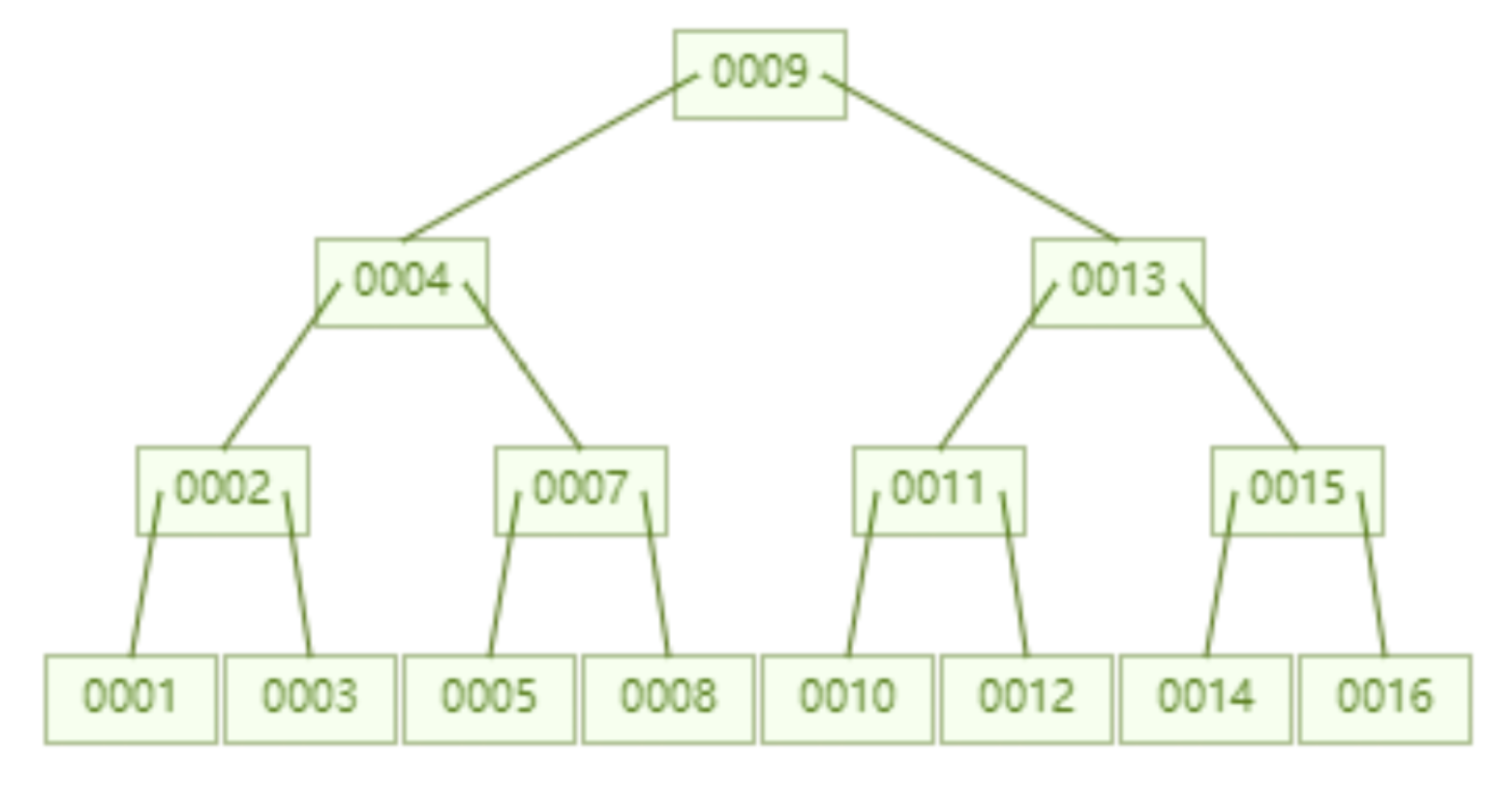
當我們把單一節點限制的 key 個數設定為 6 之後,一個儲存了 7 個資料的 B 樹,查詢 id=7 這個資料所要進行的磁碟 IO 為 2 次。
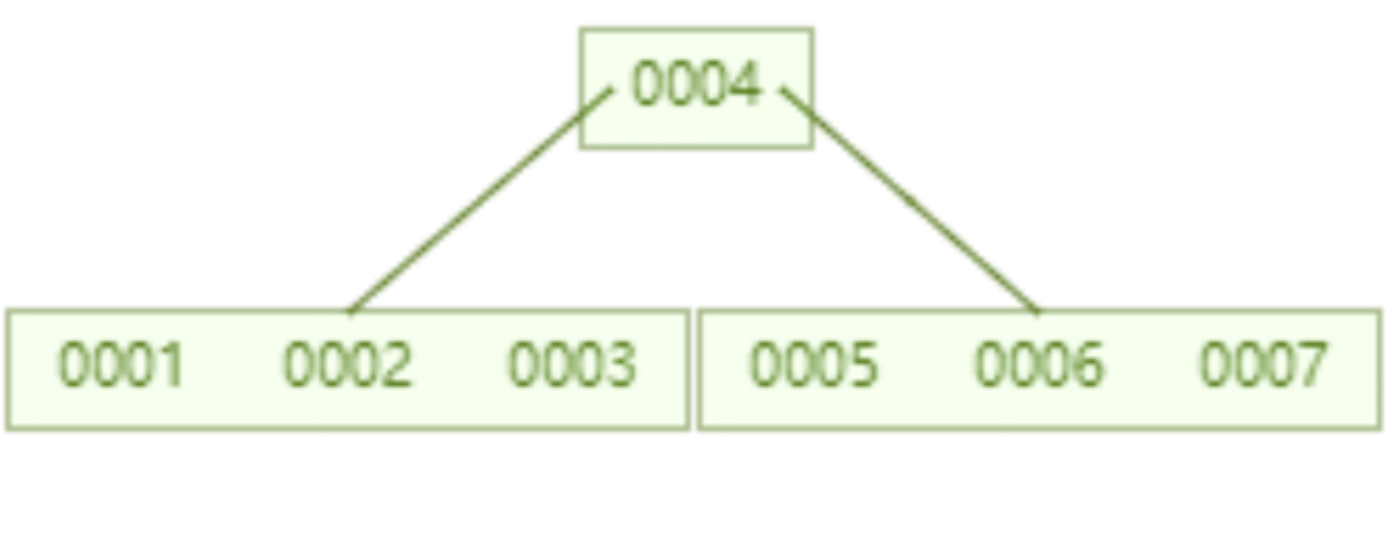
一個儲存了16 個資料的B 樹,查詢id=7 這個資料所要進行的磁碟IO 為2次。相對於 AVL 樹而言磁碟 IO 次數降至一半。

所以資料庫索引資料結構的選型而言,B 樹是一個很不錯的選擇。總結來說,B 樹用作資料庫索引有以下優點:
- 優秀檢索速度,時間複雜度:B 樹的尋找效能等於O(h*logn),其中h 為樹高,n 為每個節點關鍵字的數量;
- 盡可能少的磁碟IO,加快了檢索速度;
##可以支援範圍查找。
B 樹和 B 樹有什麼不同呢?
第一,B 樹一個節點裡存的是數據,而B 樹儲存的是索引(位址),所以B 樹裡一個節點存不了很多個數據,但是B 樹一個節點能存很多索引,B 樹葉子節點存所有的資料。
第二,B 樹的葉子節點是資料階段用了一個鍊錶串聯起來,方便範圍查找。

二、Innodb 引擎和Myisam 引擎的實作
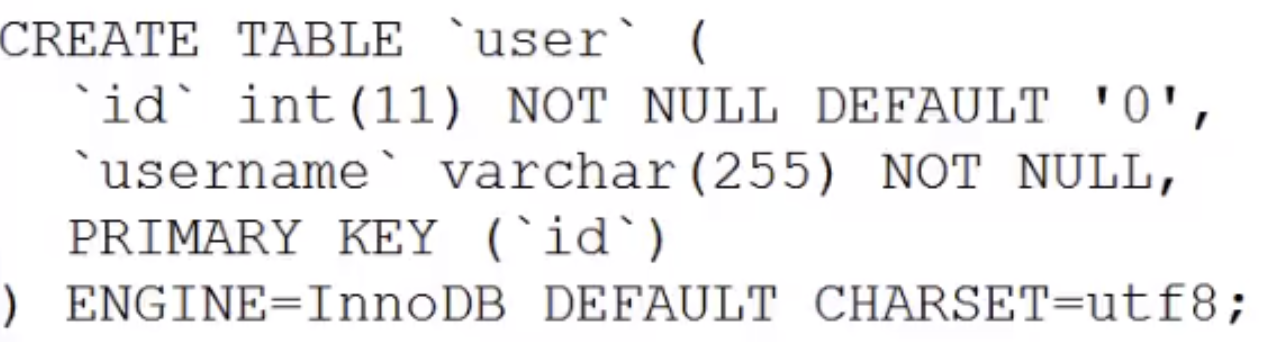
Mysql 底層資料引擎以外掛形式設計,最常見的是Innodb 引擎和Myisam 引擎,使用者可以根據個人需求選擇不同的引擎作為Mysql 資料表的底層引擎。我們剛剛分析了,B 樹作為 Mysql 的索引的資料結構非常合適,但是資料和索引到底怎麼組織起來也是需要一番設計,設計理念的不同也導致了 Innodb 和 Myisam 的出現,各自呈現獨特的效能。 MyISAM 雖然資料查找效能極佳,但不支援事務處理。 Innodb 最大的特色就是支援了 ACID 相容的事務功能,而且他支援行級鎖定。 Mysql 建立表格的時候就可以指定引擎,例如下面的例子,就是分別指定了 Myisam 和 Innodb 作為 user 表和 user2 表的資料引擎。
#執行這兩個指令後,系統出現了以下的文件,說明這兩個引擎資料和索引的組織方式是不一樣的。
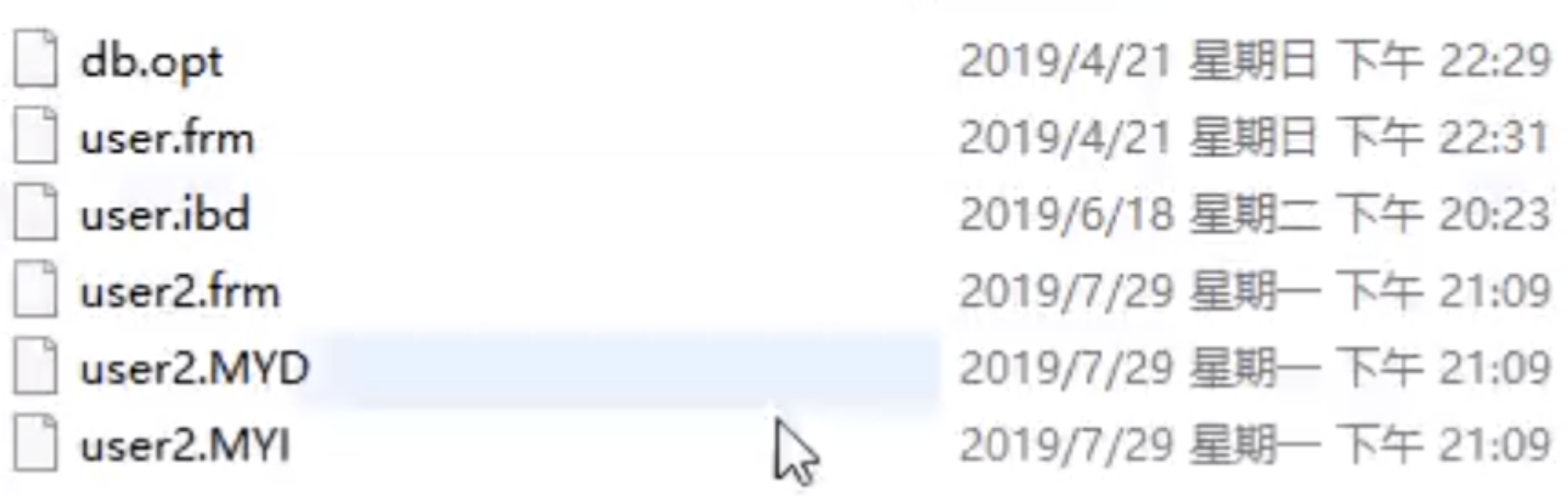
Innodb 建立表格後產生的檔案有:
- frm:建立表格的語句
- idb:表裡面的資料索引檔案
#Myisam 建立表格後產生的檔案有
- frm:建立表格的語句
- MYD:表格裡面的資料檔案(myisam data)
- MYI:表格裡面的索引檔案(myisam index)
從產生的文件看來,這兩個引擎底層資料和索引的組織方式並不一樣,MyISAM 引擎把資料和索引分開了,一人一個文件,這叫做非聚集索引方式;Innodb 引擎把資料和索引放在同一個檔案裡了,這叫做聚集索引方式。下面將從底層實作角度分析這兩個引擎是怎麼依靠 B 樹這個資料結構來組織引擎實現的。
MyISAM 引擎的底層實作(非聚集索引方式)
MyISAM 用的是非聚集索引方式,即資料和索引落在不同的兩個文件上。 MyISAM 在建表時以主鍵作為 KEY 來建立主索引 B 樹,樹的葉子節點存的是對應資料的實體位址。我們拿到這個實體位址後,就可以到 MyISAM 資料檔直接定位到具體的資料記錄了。
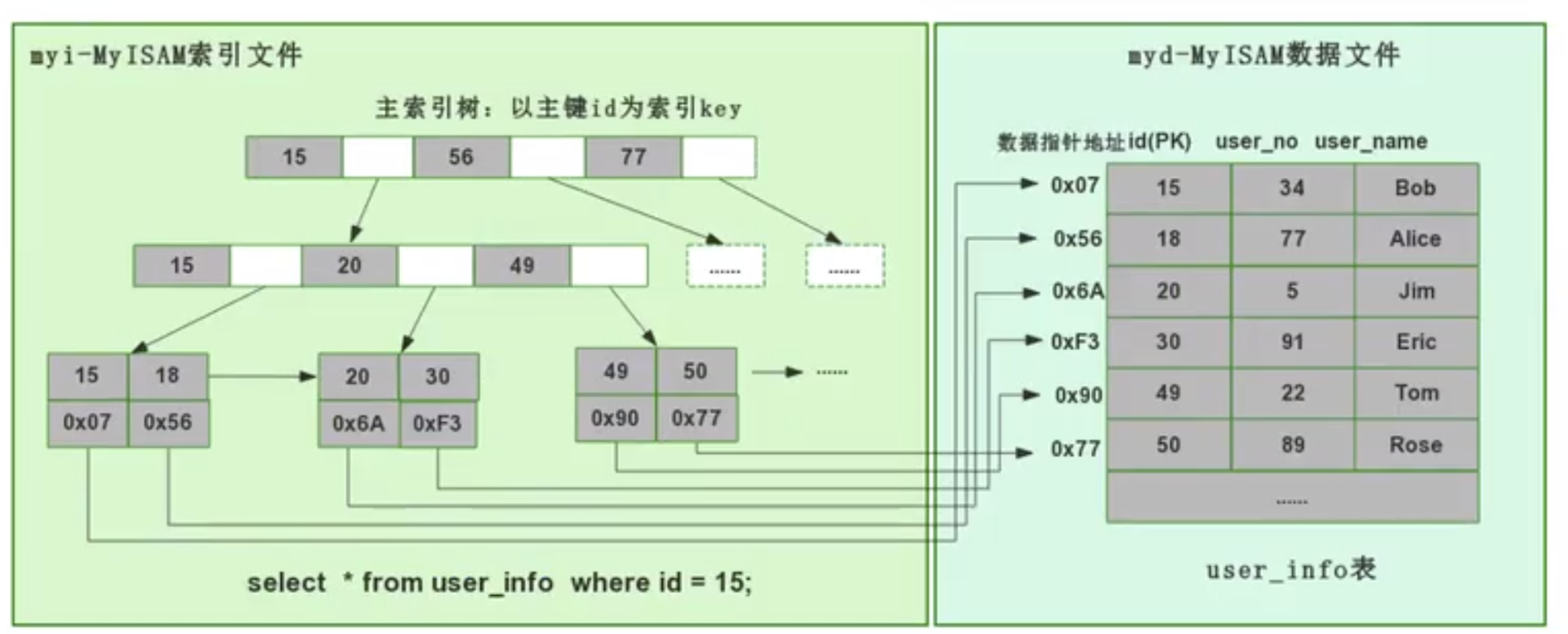
當我們為某個欄位新增索引時,我們同樣會產生對應欄位的索引樹,該欄位的索引樹的葉子節點同樣是記錄了對應資料的實體位址,然後也是拿著這個實體位址去資料檔案定位到具體的資料記錄。
Innodb 引擎的底層實作(聚集索引方式)
InnoDB 是聚集索引方式,因此資料和索引都儲存在同一個檔案裡。首先InnoDB 會根據主鍵ID 作為KEY 建立索引B 樹,如左下圖所示,而B 樹的葉子節點儲存的是主鍵ID 對應的數據,例如在執行select * from user_info where id=15 這個語句時,InnoDB就會查詢這顆主鍵ID 索引B 樹,找出對應的user_name='Bob'。
這是建表的時候 InnoDB 就會自動建立好主鍵 ID 索引樹,這也是為什麼 Mysql 在建表時要求必須指定主鍵的原因。當我們為表裡某個欄位加索引時 InnoDB 會怎麼建立索引樹呢?例如我們要為 user_name 這個欄位加索引,那麼 InnoDB 就會建立 user_name 索引 B 樹,節點裡存的是 user_name 這個 KEY,葉子節點儲存的資料的就是主鍵 KEY。注意,葉子儲存的是主鍵 KEY!拿到主鍵 KEY 後,InnoDB 才會去主鍵索引樹裡根據剛在 user_name 索引樹找到的主鍵 KEY 查找到對應的資料。
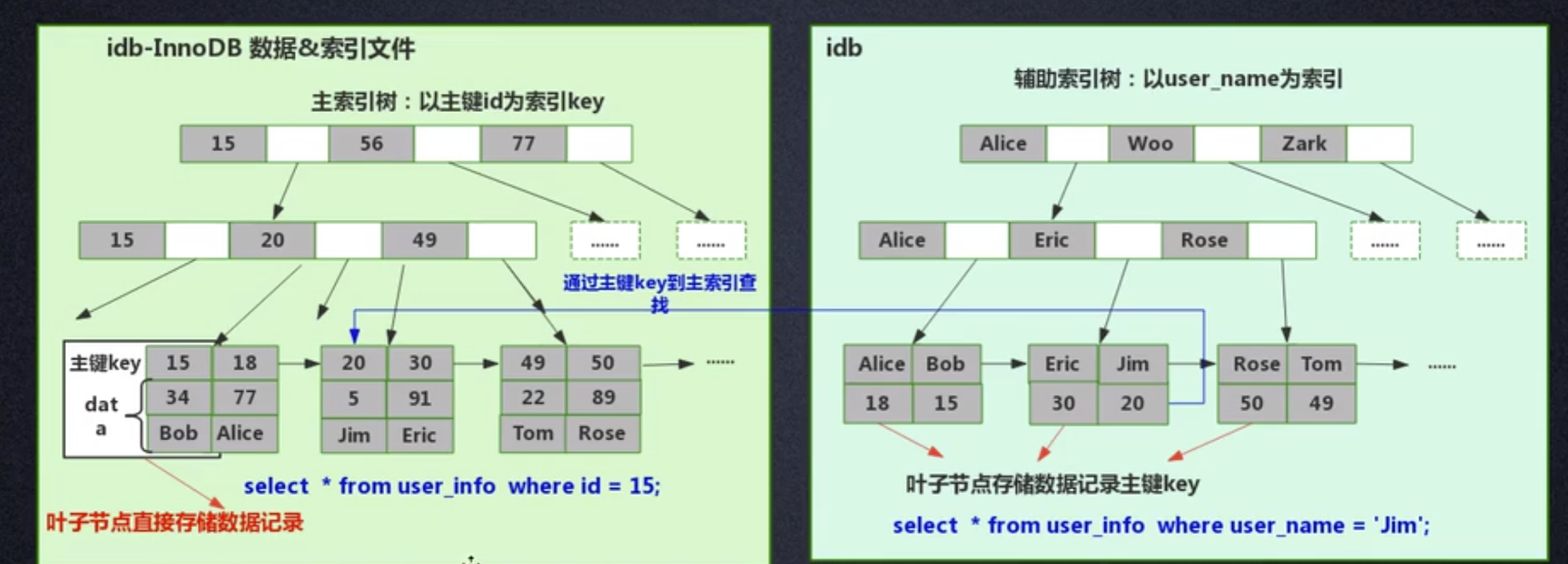
#問題來了,為什麼InnoDB 只在主鍵索引樹的葉子節點儲存了具體數據,但是其他索引樹卻不存具體資料呢,而要多此一舉先找到主鍵,再在主鍵索引樹找到對應的資料呢?
#其實很簡單,因為InnoDB 需要節省儲存空間。一個表裡可能有很多個索引,InnoDB 都會為每個加了索引的字段生成索引樹,如果每個字段的索引樹都存儲了具體數據,那麼這個表的索引數據文件就變得非常巨大(數據極度冗餘了)。從節約磁碟空間的角度來說,真的沒有必要每個字段索引樹都存具體數據,通過這種看似“多此一舉”的步驟,在犧牲較少查詢的性能下節省了巨大的磁碟空間,這是非常有值得的。
在進行InnoDB 和MyISAM 特點比較時談到,MyISAM 查詢效能更好,從上面索引檔案資料檔案的設計來看也可以看出原因:MyISAM 直接找到實體位址後就可以直接定位到資料記錄,但InnoDB 查詢到葉子節點後,還需要再查詢一次主鍵索引樹,才可以定位到特定資料。等於 MyISAM 一步就查到了數據,但是 InnoDB 要兩步,那當然 MyISAM 查詢效能更高。
本文首先探討了哪種資料結構更適合作為 Mysql 底層索引的實現,然後再介紹了 Mysql 兩種經典資料引擎 MyISAM 和 InnoDB 的底層實作。最後再總結一下什麼時候需要為你的表裡的字段加索引吧:
- 較頻繁的作為查詢條件的字段應該創建索引;
- #唯一性太差的欄位不適合單獨建立索引,即使該欄位經常作為查詢條件;
- 更新非常頻繁的欄位不適合建立索引。
【相關推薦:mysql影片教學】
以上是mysql索引為什麼快的詳細內容。更多資訊請關注PHP中文網其他相關文章!