
從視訊到音訊:使用VIT進行音訊分類

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-04-12 11:43:051047瀏覽
就機器學習而言,音訊本身是一個有廣泛應用的完整的領域,包括語音辨識、音樂分類和聲音事件偵測等等。傳統上音訊分類一直使用譜圖分析和隱藏馬可夫模型等方法,這些方法已被證明是有效的,但也有其限制。近期VIT已經成為音訊任務的一個有前途的替代品,OpenAI的Whisper就是一個很好的例子。

資料集介紹
GTZAN 資料集是在音樂流派識別 (MGR) 研究中最常用的公共資料集。這些文件是在 2000-2001 年從各種來源收集的,包括個人 CD、收音機、麥克風錄音,代表各種錄音條件下的聲音。
這個資料集由子資料夾組成,每個子資料夾是一種型別。
載入資料集
我們將載入每個.wav文件,並透過librosa庫產生對應的Mel譜圖。
mel譜圖是聲音訊號的頻譜內容的一種視覺化表示,它的垂直軸表示mel尺度上的頻率,水平軸表示時間。它是音訊訊號處理中常用的一種表示形式,特別是在音樂資訊檢索領域。
梅爾音階(Mel scale,英文:mel scale)是一個考慮到人類音高感知的音階。因為人類不會感知線性範圍的頻率,也就是說我們在偵測低頻差異方面要勝於高頻。例如,我們可以輕鬆分辨出500 Hz和1000 Hz之間的差異,但即使之間的距離相同,我們也很難分辨出10,000 Hz和10,500 Hz之間的差異。所以梅爾音階解決了這個問題,如果梅爾音階的差異相同,則意指人類感覺到的音高差異將會相同。
def wav2melspec(fp):
y, sr = librosa.load(fp)
S = librosa.feature.melspectrogram(y=y, sr=sr, n_mels=128)
log_S = librosa.amplitude_to_db(S, ref=np.max)
img = librosa.display.specshow(log_S, sr=sr, x_axis='time', y_axis='mel')
# get current figure without white border
img = plt.gcf()
img.gca().xaxis.set_major_locator(plt.NullLocator())
img.gca().yaxis.set_major_locator(plt.NullLocator())
img.subplots_adjust(top = 1, bottom = 0, right = 1, left = 0,
hspace = 0, wspace = 0)
img.gca().xaxis.set_major_locator(plt.NullLocator())
img.gca().yaxis.set_major_locator(plt.NullLocator())
# to pil image
img.canvas.draw()
img = Image.frombytes('RGB', img.canvas.get_width_height(), img.canvas.tostring_rgb())
return img上述函數將產生一個簡單的mel譜圖:

#現在我們從資料夾載入資料集,並對映像套用轉換。
class AudioDataset(Dataset):
def __init__(self, root, transform=None):
self.root = root
self.transform = transform
self.classes = sorted(os.listdir(root))
self.class_to_idx = {c: i for i, c in enumerate(self.classes)}
self.samples = []
for c in self.classes:
for fp in os.listdir(os.path.join(root, c)):
self.samples.append((os.path.join(root, c, fp), self.class_to_idx[c]))
def __len__(self):
return len(self.samples)
def __getitem__(self, idx):
fp, target = self.samples[idx]
img = Image.open(fp)
if self.transform:
img = self.transform(img)
return img, target
train_dataset = AudioDataset(root, transform=transforms.Compose([
transforms.Resize((480, 480)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
]))ViT模型
我們將利用ViT來作為我們的模型:Vision Transformer在論文中首次介紹了一幅圖像等於16x16個單詞,並成功地展示了這種方式不依賴任何的cnn,直接應用於影像Patches序列的純Transformer可以很好地執行影像分類任務。
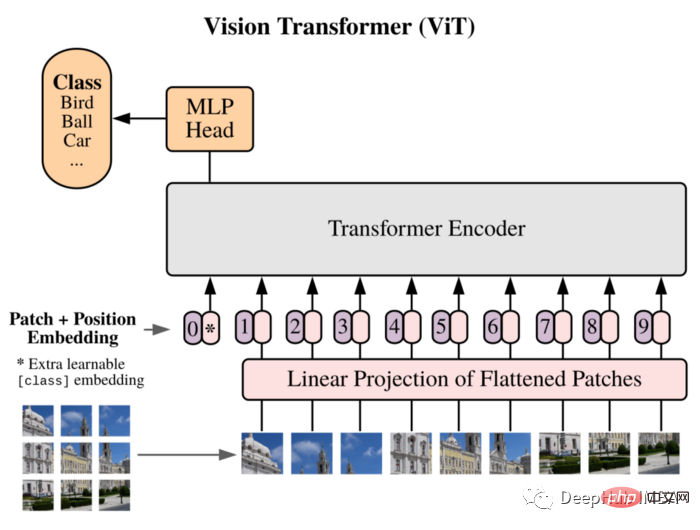
將影像分割成Patches,並將這些Patches的線性嵌入序列作為Transformer的輸入。 Patches的處理方式與NLP應用程式中的標記(單字)是相同的。
由於缺乏CNN固有的歸納偏差(如局部性),Transformer在訓練資料量不足時無法很好地泛化。但是當在大型資料集上訓練時,它確實在多個影像辨識基準上達到或擊敗了最先進的水平。
實現的結構如下所示:
class ViT(nn.Sequential): def __init__(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768, img_size: int = 356, depth: int = 12, n_classes: int = 1000, **kwargs): super().__init__( PatchEmbedding(in_channels, patch_size, emb_size, img_size), TransformerEncoder(depth, emb_size=emb_size, **kwargs), ClassificationHead(emb_size, n_classes)
訓練
訓練循環也是傳統的訓練過程:
vit = ViT(
n_classes = len(train_dataset.classes)
)
vit.to(device)
# train
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
optimizer = optim.Adam(vit.parameters(), lr=1e-3)
scheduler = ReduceLROnPlateau(optimizer, 'max', factor=0.3, patience=3, verbose=True)
criterion = nn.CrossEntropyLoss()
num_epochs = 30
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
vit.train()
running_loss = 0.0
running_corrects = 0
for inputs, labels in tqdm.tqdm(train_loader):
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
with torch.set_grad_enabled(True):
outputs = vit(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(train_dataset)
epoch_acc = running_corrects.double() / len(train_dataset)
scheduler.step(epoch_acc)
print('Loss: {:.4f} Acc: {:.4f}'.format(epoch_loss, epoch_acc))總結
使用PyTorch從頭開始訓練了這個Vision Transformer架構的自訂實作。因為資料集非常小(每個類別只有100個樣本),這影響了模型的效能,只獲得了0.71的準確率。
這只是一個簡單的演示,如果需要提高模型表現,可以使用更大的資料集,或者稍微調整架構的各種超參數!
這裡使用的vit程式碼來自:
https://medium.com/artificialis/vit-visiontransformer-a-pytorch-implementation-8d6a1033bdc5
以上是從視訊到音訊:使用VIT進行音訊分類的詳細內容。更多資訊請關注PHP中文網其他相關文章!