
美團搜尋粗排優化的探索與實踐

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-04-12 11:31:091962瀏覽
作者: 雪江所貴李想等
粗排是工業界搜廣推系統的重要模組。美團搜尋排序團隊在優化粗排效果的探索和實踐中,基於業務實際場景,從精排聯動和效果性能聯合優化兩方面優化粗排,提升了粗排的效果。
1. 前言
眾所周知,在搜尋、推薦、廣告等大規模工業界應用領域,為了平衡效能和效果,排序系統普遍採用級聯架構[1,2],如下圖1 所示。以美團搜尋排序系統為例,整個排序分為粗排、精排、重排和混排層;粗排位於召回和精排之間,需要從千級候選item 集合中篩選出百級item 集合送給精排層。

圖1 排序漏斗
從美團搜尋排序全連結視角檢視粗排模組,目前粗排層最佳化存在以下幾個挑戰點:
- #樣本選擇偏差:級聯排序系統下,粗排離最後的結果顯示環節較遠,導致粗排模型離線訓練樣本空間與待預測的樣本空間有較大的差異,有嚴重的樣本選擇偏差。
- 粗排精排連動:粗排處於召回與精排之間,粗排需要更多取得並利用後續鏈路的資訊來提升效果。
- 效能限制:線上粗排預測的候選集遠高於精排模型,然而實際整個搜尋系統對效能有嚴格的要求,導致粗排需要專注於預測性能。
本文將圍繞上述挑戰點來分享美團搜尋粗排層優化的相關探索與實踐,其中樣本選擇偏差問題我們放在精排聯動問題中一起解決。本文主要分成三個部分:第一部分會簡單介紹美團搜尋排序粗排層的演進路線;第二部分介紹粗排優化的相關探索與實踐,其中第一個工作是採用知識蒸餾和對比學習使精排和粗排聯動來優化粗排效果,第二個工作是考慮粗排性能和效果trade-off 的粗排優化,相關工作均已全量上線,且效果顯著;最後是總結與展望部分,希望這些內容對大家有所幫助與啟發。
2. 粗排演進路線
#美團搜尋的粗排技術演進分為以下幾個階段:
- 2016 年:基於相關性、品質度、轉換率等資訊進行線性加權,此方法簡單但是特徵的表達能力較弱,權重人工決定,排序效果存在很大的提升空間。
- 2017 年:採用基於機器學習的簡單 LR 模型進行 Pointwise 預估排序。
- 2018 年:採用基於向量內積的雙塔模型,兩邊分別輸入查詢詞、使用者以及上下文特徵和商家特徵,經過深度網路計算後,分別產出使用者&查詢詞向量與商家向量,再透過內積計算得到預估分數進行排序。此方法可以事先把商家向量計算保存好,所以在線上預測快,但是兩側資訊的交叉能力有限。
- 2019 年:為了解決雙塔模型無法很好地建模交叉特徵的問題,將雙塔模型的輸出作為特徵與其他交叉特徵透過GBDT 樹模型進行融合。
- 2020 年至今:由於算力的提升,開始探索 NN 端對端粗排模型並且持續迭代 NN 模型。
現階段,工業界粗排模型常用的有雙塔模型,例如騰訊[3]和愛奇藝[4];互動式NN 模型,如阿里巴巴[1,2]。下文主要介紹美團搜尋在粗排升級為 NN 模型過程中的相關最佳化工作,主要包括粗排效果最佳化、效果&效能聯合最佳化兩個部分。
3. 粗排優化實踐
隨著大量的效果優化工作[5,6]在美團搜尋精排NN 模型落地,我們也開始探索粗排NN 模型的優化。考慮到粗排有嚴格的性能約束,直接將精排優化的工作復用到粗排是不適用的。以下將介紹將精排的排序能力遷移到粗排的精排連動效果最佳化工作,以及基於神經網路結構自動搜尋的效果和效能 trade-off 最佳化工作。
3.1 精排連動效果最佳化
粗排模型受限於評分效能約束,這會導致模型結構相比精排模型更簡單,特徵數也比精排少很多,因此排序效果差於精排。為了彌補粗排模型結構簡單、特徵較少帶來的效果損失,我們嘗試知識蒸餾法[7]來連動精排對粗排進行最佳化。
知識蒸餾是目前業界簡化模型結構並最小化效果損失的普遍方法,它採取一種Teacher-Student 範式:結構複雜、學習能力強的模型作為Teacher 模型,結構較簡單的模型作為Student 模型,透過Teacher 模型來輔助Student 模型訓練,從而將Teacher 模型的「知識」傳遞給Student 模型,實現Student 模型的效果提升。精排蒸餾粗排的示意圖如下圖 2 所示,蒸餾方案分為以下三種:精排結果蒸餾、精排預測分數蒸餾、特徵表徵蒸餾。以下將分別介紹這些蒸餾方案在美團搜尋粗排中的實務經驗。

圖2 精排蒸餾粗排示意圖
3.1.1 精排結果列表蒸餾
#粗排作為精排的前置模組,它的目標是初步篩選出品質比較好的候選集合進入精排,從訓練樣本選取來看,除了常規的使用者發生行為(點擊、下單、支付)的item 作為正樣本,曝光未發生行為的item 作為負樣本外,還可以引入一些透過精排模型排序結果建構的正負樣本,這樣既能一定程度緩解粗排模型的樣本選擇偏置,也能將精排的排序能力移轉到粗排。以下將介紹在美團搜尋場景下,使用精排排序結果蒸餾粗排模型的實務經驗。
策略1:在使用者回饋的正負樣本基礎上,隨機選取少量精排排序靠後的未曝光樣本作為粗排負樣本的補充,如圖3 所示。此項改動離線 Recall@150(指標解釋參考附錄) 5PP,線上 CTR 0.1%。

圖3 補充排序結果靠後負例
##策略2 :直接在精排排序後的集合裡面進行隨機採樣得到訓練樣本,精排排序的位置作為label 構造pair 對進行訓練,如下圖4 所示。離線效果相比策略1 Recall@150 2PP,線上 CTR 0.06%。

圖4 排序靠前後構成pair 對樣本
策略3:基於策略2的樣本集選取,採用對精排排序位置進行分檔構造label ,然後根據分檔label 建構pair 對進行訓練。離線效果相比策略2 Recall@150 3PP,線上 CTR 0.1%。
3.1.2 精排預測分數蒸餾前面使用排序結果蒸餾是一種比較粗糙使用精排資訊的方式,我們在這個基礎上進一步添加預測分數蒸餾[8],希望粗排模型輸出的分數與精排模型輸出的分數分佈盡量對齊,如下圖5 所示:

圖5 精排預測分數建構輔助損失
在具體實現上,我們採用兩階段蒸餾範式,基於預先訓練好的精排模型來蒸餾粗排模型,蒸餾Loss 採用的是粗排模型輸出和精排模型輸出的最小平方誤差,並且加入一個參數Lambda 來控制蒸餾Loss 對最終Loss 的影響,如公式(1)所示。使用精排分數蒸餾的方法,離線效果 Recall@150 5PP,線上效果 CTR 0.05%。
3.1.3 特徵表徵蒸餾
業界透過知識蒸餾實現精排指導粗排表徵建模已經被驗證是一種有效提升模型效果的方式[ 7],然而直接用傳統的方法蒸餾表徵有以下缺陷:第一是無法蒸餾粗排和精排之間的排序關係,而前文已提到,排序結果蒸餾在我們的場景中,線下、線上均有效果提升;第二是傳統採用KL 散度作為表徵度量的知識蒸餾方案,把表徵的每一維獨立對待,無法有效地蒸餾高度相關的、結構化的信息[9],而在美在團搜尋場景下,資料是高度結構化的,因此採用傳統的知識蒸餾策略來做表徵蒸餾可能無法較好地捕捉這種結構化的知識。
我們將對比學習技術應用到粗排建模中,使得粗排模型在蒸餾精排模型的表徵時,也能蒸餾到序的關係。我們用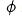 來表示粗排模型,用
來表示粗排模型,用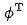 來表示精排模型。假設q是資料集中的一個請求
來表示精排模型。假設q是資料集中的一個請求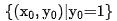 是該請求下的正樣例,而
是該請求下的正樣例,而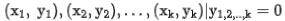 是該請求下對應的k個負樣例。
是該請求下對應的k個負樣例。
我們將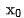 分別輸入到粗排和精排網絡中,得到其對應的表徵
分別輸入到粗排和精排網絡中,得到其對應的表徵 ,與同時,我們將
,與同時,我們將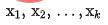 輸入到粗排網路中,得到粗排模型編碼後的表徵
輸入到粗排網路中,得到粗排模型編碼後的表徵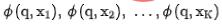 。對於對比學習負例對的選取,我們採用策略3 中的方案,對精排的順序進行分檔,同檔內精排、粗排的表徵對看成是正例,不同檔間粗排、精排的表徵對看成是負例,而後用InfoNCE Loss 來優化這個目標:
。對於對比學習負例對的選取,我們採用策略3 中的方案,對精排的順序進行分檔,同檔內精排、粗排的表徵對看成是正例,不同檔間粗排、精排的表徵對看成是負例,而後用InfoNCE Loss 來優化這個目標:
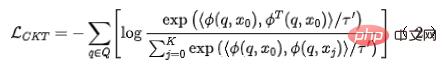
#其中 表示兩個向量的點積, 是溫度係數。透過對 InfoNCE loss 的性質進行分析,不難發現上式本質上等價於最大化粗排表徵和精排表徵互資訊的一個下界。因此,此方法本質上是在互資訊層面上最大化精排表徵和粗排表徵之間的一致性,能夠更有效地蒸餾結構化知識。

圖6 比較學習精排資訊遷移
在上文公式(1) 的基礎上,補充對比學習表徵蒸餾Loss,離線效果Recall@150 14PP,線上CTR 0.15%。相關工作的詳細內容可以參考我們的論文[10](正在投稿中)。
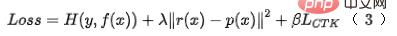
3.2 效果性能聯合優化
前面提到線上預測的粗排候選集較大,考慮到系統全鏈路效能的約束,粗排需要考慮預測效率。前文提到的工作都是基於簡單DNN 蒸餾的範式來進行優化,但是存在如下兩個問題:
- 目前受限於線上性能而只使用了簡單特徵,未引入更豐富的交叉特徵,導致模型效果還有進一步提升的空間。
- 固定粗排模型結構的蒸餾會損失蒸餾效果,造成次優解[11]。
根據我們的實務經驗,直接在粗排層引入交叉特徵是不能滿足線上時延要求的。因此為了解決以上問題,我們探索並實踐了基於神經網路架構搜尋的粗排建模方案,該方案同時優化粗排模型的效果和效能,選擇出滿足粗排時延要求的最佳特徵組合和模型結構,整體架構圖如下圖7所示:

#圖7 基於NAS 的特徵和模型結構
#選擇下面我們對其中的神經網路架構搜尋(NAS)以及引入效率建模這兩個關鍵技術點進行簡單介紹:
- #神經網路架構搜尋:如上圖7所示,我們採用基於ProxylessNAS[12]的建模方式,整個模型訓練除了網路參數外增加了特徵Masks 參數和網路架構參數,這些參數是可微分的,隨著模型目標一起學習。在特徵選擇部分,我們給每一個特徵引入一個基於伯努利分佈的Mask 參數 ,參見公式(4),其中伯努利分佈的θ 參數通過反向傳播進行更新,最終獲得每個特徵的重要度。在結構選擇部分,採用了L 層Mixop 表示,每組Mixop 包含N 個可供選擇的網路結構單元,在實驗中,我們採用了不同隱層神經單元數的多層感知機,其中N= {1024 , 512, 256, 128, 64},同時我們也增加了隱藏單元數為0 的結構單元,用於選擇具有不同層數的神經網路。

- 效率建模:為了在模型目標中建模效率指標,我們需要採用一個可微分的學習目標來表示模型耗時,粗排模型的耗時主要分為特徵耗時和模型結構耗時。
對於特徵耗時來說,每個特徵fi 的延時期望可以被建模為如公式(5)所示,其中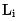 是服務端打點記錄的每個特徵時延。
是服務端打點記錄的每個特徵時延。
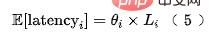
在實際情況中特徵可以分為兩大類,一部分是上游透傳類別特徵 ,其延遲主要來自上游傳輸延時;另一類特徵 來自於本地獲取(讀取KV 或計算),那麼每個特徵組合的延遲可以被建模為:
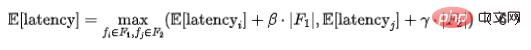
其中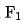 和
和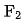 表示對應特徵集合的數,
表示對應特徵集合的數,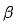 和
和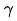 #建模系統特徵拉取並發度。
#建模系統特徵拉取並發度。
對於模型結構的延時建模可參見上圖7 右邊部分,由於這些Mixop 的執行是順序進行的,因此我們可以採取遞歸的方式的計算模型結構延時,整個模型部分的耗時可以用最後一層的Mixop 來表達,示意圖如下圖8 所示:

圖8 模型延時計算圖
圖8 左邊是配備網路架構選擇的粗排網絡,其中 表示第 層的第 個神經單元的權重。右邊是網路延時計算示意圖。因此整個模型預測部分耗時可以用最後一層模型來表示,如公式(7)所示:
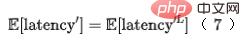
最終我們把效率指標引入模型,最終模型訓練的Loss 如下面公式(8)所示,其中,f 表示精排網絡,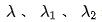 表示平衡因子,
表示平衡因子,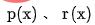 分別表示粗排和精排的評分輸出。
分別表示粗排和精排的評分輸出。
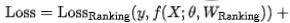

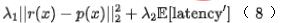
透過神經網路架構搜尋的建模來聯合優化粗排模型的效果和預測性能,離線Recall@150 11PP, 最終在線上在延時不增加的情況下,線上指標CTR 0.12%;詳細工作可參考[13],已被KDD 2022 接收。
4. 總結
從2020 年開始,我們透過大量的工程性能優化使粗排層落地MLP 模型,在2021 年我們繼續在MLP 模型基礎上,持續迭代粗排模型來提升粗排效果。
首先,我們藉鑒業界常用的蒸餾方案來連動精排優化粗排,從精排結果蒸餾、精排預測分數蒸餾、特徵表徵蒸餾三個層面分別進行了大量實驗,在不增加線上延時的情況下,提升粗排模型效果。其次,考慮到傳統蒸餾方式無法很好地處理排序場景中的特徵結構化訊息,我們自研了一套基於對比學習的精排資訊遷移粗排方案。
最後,我們進一步考慮到粗排優化本質上是效果和性能的trade-off,採用多目標建模的思路同時優化效果和性能,落地神經網絡架構自動搜尋技術來進行求解,讓模型自動選擇效率和效果最佳的特徵集合和模型結構。後續我們會從以下幾個方面繼續迭代粗排層技術:
- 粗排多目標建模:目前的粗排本質上還是單目標模型,目前我們正在嘗試將精排層的多目標建模應用於粗排。
- 粗排連動的全系統動態算力分配:粗排可以控制召回的算力以及精排的算力,針對不同場景,模型需要的算力是不一樣的,因此動態算力分配可以在不降低線上效果的情況下減少系統算力消耗,目前我們已經在這個方面取得了一定的線上效果。
5. 附錄
傳統的排序離線指標多以NDCG、MAP、AUC 類別指標為標準,對於粗排來說,其本質更偏向以集合選擇為目標的回想類別任務,因此傳統的排序指標不利於衡量粗排模型迭代效果好壞。我們借鏡[6]中 Recall 指標作為粗排離線效果的衡量指標,以精排排序結果為 ground truth,衡量粗排和精排排序結果 TopK 的對齊程度。 Recall 指標具體定義如下:
此公式的物理意義即為衡量粗排排序前K 個與精排排序前K 的重合度,此指標更符合粗排集合選擇的本質。
6. 作者簡介
曉江、所貴、李想、曹越、培浩、肖垚、達遙、陳勝、雲森、利前等,均來自美團平台/搜尋推薦演算法部。
以上是美團搜尋粗排優化的探索與實踐的詳細內容。更多資訊請關注PHP中文網其他相關文章!