



理解人工智慧決策對研究人員、決策者和廣大人民來說非常重要。幸運的是,有一些方法可以確保我們了解更多。前沿人工智慧公司和學術屆所使用的深度學習模型已經變得如此複雜,以至於即使是建立模型的研究人員也難以理解正在做出的決策。
這一點在某項錦標賽上得到了最明顯的體現。在這場比賽中,資料科學家和職業圍棋選手經常被人工智慧在比賽中的決策所迷惑,因為它做出了非正式的遊戲,而這並不被認為是最強的一步。

為了更好地理解他們所建構的模型,人工智慧研究人員開發了三種主要的解釋方法。這些是局部解釋方法,只解釋一個具體的決定,而不是整個模型的決定,考慮到規模,這可能具有挑戰性。
研究者正確瞭解人工智慧決策的三種方法
特徵歸因
透過特徵歸因,人工智慧模型將識別輸入的哪些部分對特定決策是重要的。對於X射線,研究人員可以看到熱圖或模型認為對其決策最重要的單一像素。
使用這種特徵歸因解釋,可以檢查是否有虛假相關性。例如,它會顯示水印中的像素是否被突出顯示,或者實際腫瘤中的像素是否被突出顯示。
反事實解釋
當做出決定時,我們可能會感到困惑,不知道為什麼人工智慧會做出這樣或那樣的決定。由於人工智慧被部署在高風險的環境中,例如監獄、保險或抵押貸款,了解人工智慧拒絕因素或上訴的原因應該有助於他們在下次申請時獲得批准。
反事實解釋方法的好處是,它確切地告訴你需要如何更改輸入來翻轉決策,這可能具有實際用途。對於那些申請抵押貸款卻沒有得到的人來說,這個解釋會告訴他們需要做些什麼來達到他們想要的結果。
樣本重要性
樣本重要性解釋需要存取模型背後的基礎資料。如果研究人員注意到他們認為是錯誤的,他們可以運行一個樣本重要性解釋,以查看人工智慧是否輸入了它無法計算的數據,從而導致判斷錯誤。
以上是研究人員正確理解人工智慧決策的三種方法的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 生成AI應用的代理框架 - 分析VidhyaApr 13, 2025 am 11:13 AM
生成AI應用的代理框架 - 分析VidhyaApr 13, 2025 am 11:13 AM想像一下,擁有一個由AI驅動的助手,不僅可以響應您的查詢,還可以自主收集信息,執行任務甚至處理多種類型的數據(TEXT,圖像和代碼)。聽起來有未來派?在這個a


 您需要查看的3台Openai' s的動手實驗 - 分析VidhyaApr 13, 2025 am 11:06 AM
您需要查看的3台Openai' s的動手實驗 - 分析VidhyaApr 13, 2025 am 11:06 AM介紹 您在講話之前真正思考和理性多久?當前最新的LLM GPT-4O已經在不花很多時間做出回應的情況下提供了令人印象深刻的回應。但是想像一下它是否開始服用
 如何訪問OpenAi O1? - 分析VidhyaApr 13, 2025 am 11:05 AM
如何訪問OpenAi O1? - 分析VidhyaApr 13, 2025 am 11:05 AM介紹 草莓在市場上! ! !我希望這將像其他OpenAI最新車型帶來的人工智能的最新進步一樣富有成果。 我們一直在等待GPT-5這麼長時間
 使用llamaindex構建多文件代理抹布Apr 13, 2025 am 11:03 AM
使用llamaindex構建多文件代理抹布Apr 13, 2025 am 11:03 AM介紹 在人工智能快速發展的領域中,處理和理解大量信息的能力變得越來越重要。輸入多文件代理抹布 - 一個功能強大的應用
 免費學習SQL的YouTube頻道 - 分析VidhyaApr 13, 2025 am 10:46 AM
免費學習SQL的YouTube頻道 - 分析VidhyaApr 13, 2025 am 10:46 AM介紹 掌握SQL(結構化查詢語言)對於追求數據管理,數據分析和數據庫管理的個人至關重要。如果您是從新手開始的,或者是經驗豐富的專業人士,請尋求改進,
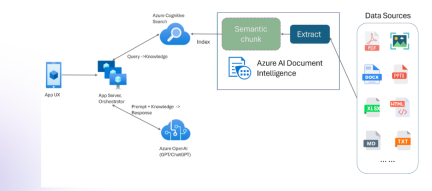 具有多模式和Azure文檔智能的抹布Apr 13, 2025 am 10:38 AM
具有多模式和Azure文檔智能的抹布Apr 13, 2025 am 10:38 AM介紹 在基於數據運行的當前世界中,關係AI圖(RAG)通過關聯數據並繪製關係來對行業產生很大影響。但是,如果一個人可以再進一步多怎麼辦


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

MinGW - Minimalist GNU for Windows
這個專案正在遷移到osdn.net/projects/mingw的過程中,你可以繼續在那裡關注我們。 MinGW:GNU編譯器集合(GCC)的本機Windows移植版本,可自由分發的導入函式庫和用於建置本機Windows應用程式的頭檔;包括對MSVC執行時間的擴展,以支援C99功能。 MinGW的所有軟體都可以在64位元Windows平台上運作。

MantisBT
Mantis是一個易於部署的基於Web的缺陷追蹤工具,用於幫助產品缺陷追蹤。它需要PHP、MySQL和一個Web伺服器。請查看我們的演示和託管服務。

Safe Exam Browser
Safe Exam Browser是一個安全的瀏覽器環境,安全地進行線上考試。該軟體將任何電腦變成一個安全的工作站。它控制對任何實用工具的訪問,並防止學生使用未經授權的資源。

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)

Dreamweaver Mac版
視覺化網頁開發工具

