
醫藥探索中的人工智慧

- PHPz轉載
- 2023-04-12 10:04:021724瀏覽
譯者| 崔皓
審校| 孫淑娟
開篇
本文探討了TypeDB幫助科學家們實現醫學上的下一個突破,並且會通過指導性的程式碼範例和視覺效果展示結果。

生物技術領域存在大量的炒作都集中在革命性藥物發現上。畢竟,過去十年是該領域的黃金時代。與之前的十年相比,2012年到2021年這段時間批准的新藥增加了73%--比之前的十年增加了25%。這些藥物包括治療癌症的免疫療法、基因療法,當然還有科威德疫苗。從這些方面可以看出製藥業做得很好。
但其呈現的趨勢也越來越令人擔憂。藥物發現的成本和風險正變得令人望而卻步。截至到目前,新藥推向市場的平均費用在10億至30億美元,平均時間在12至18年。同時,一種新藥的平均價格已經從2007年的2千美元飆升到2021年的18萬美元。
這就是為什麼許多人把希望寄託在人工智慧(AI)(如統計機器學習)上,以幫助加速新藥的開發,從早期目標識別到試驗。雖然已經利用各種機器學習演算法確定了一些化合物,但這些化合物仍處於早期發現或臨床前的開發階段。人工智慧徹底改變藥物發現的承諾仍然是令人興奮但尚未實現的承諾。
什麼是人工智慧?
為了實現這項承諾,理解人工智慧的真正意義就顯得至關重要了。近年來,人工智慧這個詞已經成為相當熱門的詞彙,沒有太多技術含量。那麼,什麼才是真正的人工智慧?
人工智慧,作為一個學術領域,從20世紀50年代起就已經存在了,隨著時間的推移,分支成各種類型,代表不同的學習方式。佩德羅-多明哥斯教授在《演算法大師》一書中對這些類型進行了描述(他稱它們為"部落"):連結主義者、符號主義者、進化主義者、貝葉斯主義者和模擬主義者。
在過去的十年裡,貝葉斯主義者和連結主義者受到了公眾的廣泛關注,而符號主義者則不同。符號學派在進行邏輯推理的規則集的基礎上,創造出真實的世界表徵。符號人工智慧系統沒有其他類型的人工智慧所享有的巨大宣傳,但它們擁有其他類型所缺乏的獨特而重要的能力:自動推理和知識表示。
對生物醫學知識的表現
事實上,知識表現的問題正是藥物發現中最大的問題之一。現有的資料庫軟體,如關聯式資料庫或圖形資料庫,很難準確地表示和理解生物學錯綜複雜的問題。
藥物探索所表述的問題很好地說明了要為不同的生物醫學資料來源(如Uniprot或Disgenet)建立統一的模型。在資料庫層面,這意味著創建資料模型(有些人可能稱這些為本體),描述無數複雜的實體和關係,如蛋白質、基因、藥物、疾病、交互作用等之間的關係。
這就是TypeDB,一個開源的資料庫軟體,旨在實現的目標--使開發者能夠創建高度複雜領域的真實表現,電腦可以利用它來獲得洞察力。
TypeDB的型別系統是基於實體關係的概念,代表了TypeDB中儲存的資料。這使得它足以捕捉複雜的生物醫學領域知識(透過類型推理、嵌套關係、超關係、規則推理等),使科學家獲得洞察力並加速藥物開發時間。
一家大型製藥公司的例子說明了這一點,該公司使用語義網標準為一個疾病網絡建模奮鬥了五年多,但在遷移到TypeDB之後,僅用三週時間就成功實現了這一目標。
例如,一個用TypeQL(TypeDB的查詢語言)寫的、描述蛋白質、基因和疾病的生物醫學模型看起來如下:
define protein sub entity, owns uniprot-id, plays protein-disease-association:protein, plays encode:encoded-protein; gene sub entity, owns entrez-id, plays gene-disease-association:gene, plays encode:encoding-gene; disease sub entity, owns disease-name, plays gene-disease-association:disease, plays protein-disease-association:disease; encode sub relation, relates encoded-protein, relates encoding-gene; protein-disease-association sub relation, relates protein, relates disease; gene-disease-association sub relation, relates gene, relates disease; uniprot-id sub attribute, value string; entrez-id sub attribute, value string; disease-name sub attribute, value string;
關於一個完整的工作實例,可以在Github上找到一個開源的生物醫學知識圖。這是從各種著名的生物醫學資源加載數據,如Uniprot、Disgenet、Reactome和其他。
有了儲存在TypeDB中的數據,你可以執行查詢,問一些問題,例如:哪些藥物會與SARS病毒有關的基因交互作用?
為了回答這個問題,我們可以使用TypeQL中的以下查詢。
match $virus isa virus, has virus-name "SARS"; $gene isa gene; $drug isa drug; ($virus, $gene) isa gene-virus-association; ($gene, $drug) isa drug-gene-interaction;
執行這個將使TypeDB傳回符合查詢條件的資料。並且可以在TypeDB Studio中可視化,如下所示,這將有助於了解哪些相關藥物可能值得進一步調查。
通过自动推理,TypeDB也可以推断出数据库中不存在的知识。这是通过编写规则来完成的,这些规则构成了TypeDB中模式的一部分。例如,一个规则可以推断出一个基因和一种疾病之间的关联,如果该基因编码的蛋白质与该疾病有关。这样的规则将被写成:
rule inference-example:
when {
(encoding-gene: $gene, encoded-protein: $protein) isa encode;
(protein: $protein, disease: $disease) isa protein-disease-association;
} then {
(gene: $gene, disease: $disease) isa gene-disease-association;
};然后,如果我们要插入以下数据:
TypeDB将能够推断出基因和疾病之间的联系,即使没有插入到数据库中。在这种情况下,以下关系基因-疾病-关联将被推断出来。
match $gene isa gene, has gene-id "2"; $disease isa disease, has disease-name $dn; ; (gene: $gene, disease:$disease) isa gene-disease-assocation;
通过机器学习加速目标探索
有了TypeDB对生物医学数据(符号)进行表示,再加上机器学习的上下文知识就可以让整个系统变得更加强大,从而增强洞察力。例如,可以通过药物探索管道发现有希望的目标。
寻找有希望的目标的方法是使用链接预测算法。TypeDB的规则引擎允许这样的ML模型执行,该模型通过推理推断对事实进行学习。这意味着从对平面的、无背景的数据学习转向对推理的、有背景的知识学习。其中一个好处是,根据领域的逻辑规则,预测可以被概括到训练数据的范围之外,并减少所需的训练数据量。
这样一个药物发现的工作流程如下:
1. 查询TypeDB,创建上下文知识的子图,利用TypeDB的全部表达能力。
2. 将子图转化为嵌入(embedding),并将这些嵌入到图学习算法中。
3. 预测结果(例如,作为基因-疾病关联之间的概率分数)可以被插入TypeDB,并用于验证/优先考虑某些目标。
有了数据库中的这些预测,我们可以提出更高层次的问题,利用这些预测与数据库中更广泛的背景知识。比如说:什么是最有可能成为黑色素瘤的基因目标,这些基因编码的蛋白质在黑色素细胞中如何表达?
用TypeQL写,这个问题看起来如下:
match $gene isa gene, has gene-id $gene-id; $protein isa protein; $cell isa cell, has cell-type "melanocytes"; $disease isa disease, has disease-name "melanoma"; ($gene, $protein) isa encode; ($protein, $cell) isa expression; ($gene, $disease) isa gene-disease-association, has prob $p; get $gene-id; sort desc $p;
这个查询的结果将是一个按概率分数排序的基因列表(如图学习者预测的):
{$gid "TOPGENE" isa gene-id;}
{$gid "BESTGENE" isa gene-id;}
{$gid "OTHERTARGET" isa gene-id;}
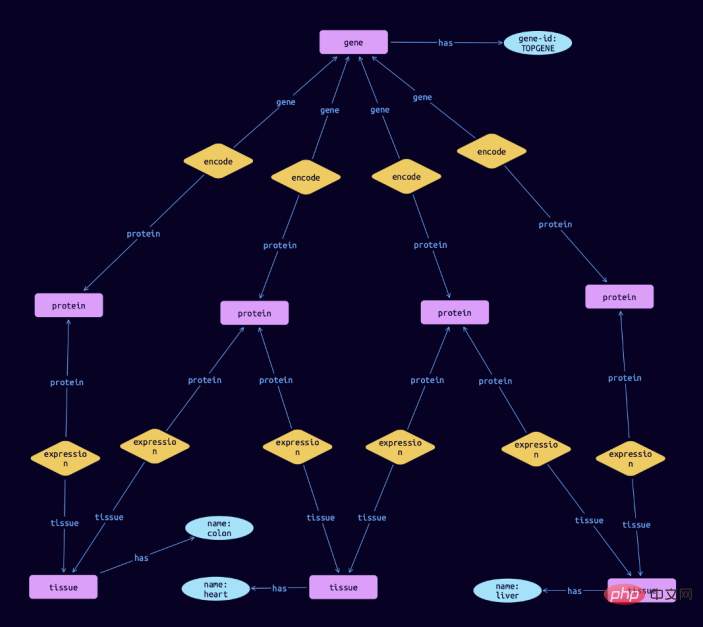
...然后,我们可以进一步研究这些基因,例如通过了解每个基因的生物学背景。比方说,我们想知道TOPGENE基因编码的蛋白质所处的组织。我们可以写下面的查询。
match $gene isa gene, has gene-id $gene-id; $gene-id "TOPGENE"; $protein isa protein; $tissue isa tissue, has name $name; $rel1 ($gene, $protein); $rel2 ($protein, $tissue);
在TypeDB Studio中可视化的结果,可以显示这个基因编码的蛋白质在结肠、心脏和肝脏中的表达:
结论
世界迫切需要创造治疗破坏性疾病的解决方案,希望通过人工智能的创新建立一个更健康的世界,在这个世界中每种疾病都可以被治疗。人工智能作用于药物探索仍处于起步阶段,但是如果一旦实现将会让生物学释放出新的创新浪潮,并使21世纪真正成为属于它的纪元。
在这篇文章中,我们看了TypeDB是如何实现生物医学知识的符号化表示,以及如何改善ML来为药物探索做出贡献的。在药物探索中应用人工智能的科学家们使用TypeDB来分析疾病网络,更好地理解生物医学研究的复杂性,并发现新的和突破性的治疗方式。
译者介绍
崔皓,51CTO社区编辑,资深架构师,拥有18年的软件开发和架构经验,10年分布式架构经验。
原文标题:Artificial Intelligence in Drug Discovery,作者:Tomás Sabat
以上是醫藥探索中的人工智慧的詳細內容。更多資訊請關注PHP中文網其他相關文章!