



雖然ImageNet早已完成歷史使命,但在電腦視覺領域仍是關鍵的資料集。
2016年,在ImageNet上訓練後的分類模型,sota準確率仍不到80%;時至今日,僅靠大規模預訓練模型的zero-shot泛化就能達到80.1%的準確率。

最近LAION使用開源程式碼OpenCLIP框架訓練了一個全新的 ViT-G/14 CLIP 模型,在ImageNet資料集上,原版OpenAI CLIP的準確率只有75.4%,而OpenCLIP實現了80.1% 的zero-shot準確率,在MS COCO 上實現了74.9% 的zero-shot影像檢索(Recall@5),這也是目前效能最強的開源CLIP 模型。

LAION全稱為Large-scale Artificial Intelligence Open Network,是一家非營利組織,其成員來自世界各地,旨在向公眾提供大規模機器學習模型、資料集和相關程式碼。他們聲稱自己是真正的Open AI,100%非營利且100%免費。
有興趣的小夥伴可以把手頭的CLIP模型更新版本了!

模型位址:https://huggingface.co/laion/CLIP-ViT-bigG-14 -laion2B-39B-b160k
OpenCLIP模型在各個資料集上具體的效能如下表所示。

Zero-shot能力
一般來說,電腦視覺(CV)模型在各個任務上的sota表現都是基於特定領域的訓練數據,無法泛化到其他領域或任務中,導致對視覺世界的通用屬性理解有限。
泛化問題對於那些缺乏大量訓練資料的領域尤其重要。
理想情況下,CV模型應該學會圖像的語意內容,而不是過度關注訓練集中的特定標籤。例如對於狗的圖像,模型應該能夠理解圖像中有一隻狗,更進一步來理解背景中有樹、時間是白天、狗在草地上等等。
但當下採用「分類訓練」得到的結果與預期正好相反,模型學習將狗的內部表徵推入相同的「狗向量空間」,將貓推入相同的「貓向量空間」,所有的問題的答案都是二元,即圖像是否能夠與一個類別標籤對齊。

對新任務重新訓練一個分類模型也是一種方案,但是訓練本身需要大量的時間和資金投入來收集分類資料集以及訓練模型。
幸運的是,OpenAI 的CLIP模型是一個非常靈活的分類模型,通常不需要重新訓練即可用於新的分類任務中。
CLIP為何能Zero-Shot
對比語言-影像預訓練(CLIP, Contrastive Language-Image Pretraining)是 OpenAI 於2021年發布的一個主要基於Transformer的模型。
CLIP 由兩個模型組成,一個Transformer編碼器用於將文字轉換為embedding,以及一個視覺Transformer(ViT)用於對圖像進行編碼。

CLIP內的文字和圖像模型在預訓練期間都進行了最佳化,以在向量空間中對齊相似的文字和圖像。在訓練過程中,將資料中的圖像-文字對在向量空間中將輸出向量推得更近,同時分離不屬於一對的圖像、文字向量。

CLIP與一般的分類模型之間有幾個差異:
首先,OpenAI 使用從網路上爬取下來的包含4億文字-圖像對的超大規模資料集進行訓練,其好處在於:
1. CLIP的訓練只需要「圖像-文字對」而不需要特定的類別標籤,而這種類型的數據在當今以社交媒體為中心的網路世界中非常豐富。
2. 大型資料集意味著 CLIP 可以對圖像中的通用文字概念進行理解的能力。
3. 文字描述(text descriptor)中往往包含圖像中的各種特徵,而不只是一個類別特徵,也就是說可以建立一個更全面的圖像和文字表徵。
上述優勢也是CLIP其建立Zero-shot能力的關鍵因素,論文的作者也對比了在ImageNet上專門訓練的ResNet-101模型和CLIP模型,將其應用於從ImageNet 派生的其他數據集,下圖為效能比較。

可以看到,儘管ResNet-101是在ImageNet上進行訓練的,但它在相似資料集上的效能比CLIP 在相同任務上的表現差得多。
在將ResNet 模型應用於其他領域時,一個常用的方法是「linear probe」(線性探測),即將ResNet模型最後幾層所學到的特性輸入到一個線性分類器中,然後針對特定的資料集進行微調。
在CLIP論文中,線性偵測ResNet-50與zero-shot的CLIP 進行了對比,結論是在相同的場景中,zero-shot CLIP 在多個任務中的效能都優於在ResNet -50中的線性探測。

不過值得注意的是,當給定更多的訓練樣本時,Zero-shot並沒有優於線性探測。
用CLIP做Zero-shot分類
從上面的描述可以知道,圖像和文字編碼器可以建立一個512維度的向量,將輸入的圖像和文字輸入映射到相同的向量空間。
用CLIP做Zero-shot分類也就是把類別資訊放入文字句子中。
舉個例子,輸入一張圖像,想要判斷其類別為汽車、鳥或貓,就可以創建三個文字字串來表示類別:
T1代表車:a photo of a car
T2代表鳥:a photo of a bird
T3代表貓:a photo of a cat
將類別描述輸入到文字編碼器中,就可以得到可以代表類別的向量。
假設輸入的是一張貓的照片,用ViT 模型對其進行編碼獲取圖像向量後,將其與類別向量計算餘弦距離作為相似度,如果與T3的相似度最高,就代表圖像的類別屬於貓。

可以看到,類別標籤並不是一個簡單的詞,而是基於模板「a photo of a {label}」 的格式重新改寫為一個句子,從而可以擴展到不受訓練限制的類別預測。
實驗中,使用此prompt模板在ImageNet的分類準確性上提高了1.3個百分點,但prompt模板並不總是能提高性能,在實際使用中需要根據不同的數據集進行測試。
Python實作
想要快速使用CLIP做zero-shot分類也十分容易,作者選取了Hugging Face中的frgfm/imagenette資料集作為演示,該資料集包含10個標籤,且全部儲存為整數值。

使用 CLIP進行分類,需要將整數值標籤轉換為對應的文字內容。

在直接將標籤和照片進行相似度計算前,需要初始化 CLIP模型,可以使用透過 Hugging Face transformers找到的 CLIP 實作。

文本transformer無法直接讀取文本,而是需要一組稱為token ID(或input _ IDs)的整數值,其中每個唯一的整數表示一個word或sub-word(即token)。

將轉換後的tensor輸入到文字transformer中可以取得標籤的文字embedding

注意,目前CLIP輸出的向量還沒有經過歸一化(normalize),點乘後所獲得的相似性結果是不準確的。

下面就可以選擇一個資料集中的影像作測試,經過相同的處理過程後取得到影像向量。

將影像轉換為尺寸為(1, 3, 224, 224)向量後,輸入到模型中即可獲得embedding

下一步是計算圖像embedding和資料集中的十個標籤文字embedding之間的點積相似度,得分最高的即是預測的類別。

模型給出的結果為cassette player(卡帶播放器),在整個資料集再重複運行一遍後,可以得到準確率為98.7%

#除了Zero-shot分類,多模態搜尋、目標偵測、 生成式模型如OpenAI 的Dall-E 和Stable disusion,CLIP打開了電腦視覺的新大門。
以上是ImageNet零樣本準確率首次超過80%,地表最強開源CLIP模型更新的詳細內容。更多資訊請關注PHP中文網其他相關文章!

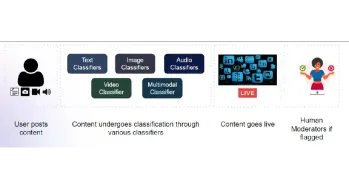 構建用於內容審核的多模式模型Apr 12, 2025 am 10:51 AM
構建用於內容審核的多模式模型Apr 12, 2025 am 10:51 AM介紹 想像一下,當一條進攻性帖子突然出現時,您正在瀏覽自己喜歡的社交媒體平台。在您點擊報告按鈕之前,它已經消失了。那是內容主音
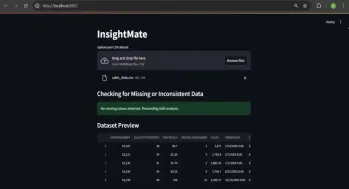 與洞察員自動化數據見解Apr 12, 2025 am 10:44 AM
與洞察員自動化數據見解Apr 12, 2025 am 10:44 AM介紹 在當今數據繁多的世界中,處理龐大的數據集可能會令人不知所措。這就是洞察力的來源。它旨在使探索您的數據變得輕而易舉。只需上傳您的數據集,您就會獲得Instan

 什麼是補充代理? |入門指南-Analytics VidhyaApr 12, 2025 am 10:40 AM
什麼是補充代理? |入門指南-Analytics VidhyaApr 12, 2025 am 10:40 AM介紹 想像一下,開發與對話相同的應用程序。將沒有復雜的開發環境可以設置,也無需查看配置文件。將概念轉換為有價值的應用程序
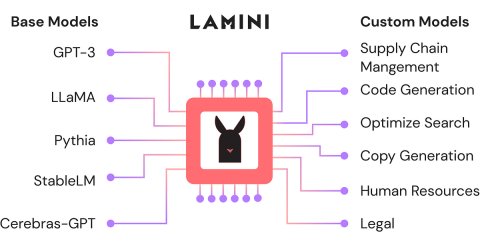 使用Lamini-Analytics Vidhya微調開源LLMApr 12, 2025 am 10:20 AM
使用Lamini-Analytics Vidhya微調開源LLMApr 12, 2025 am 10:20 AM最近,隨著大語言模型和AI的興起,我們看到了自然語言處理方面的無數進步。文本,代碼和圖像/視頻生成等域中的模型具有存檔的人類的推理和P
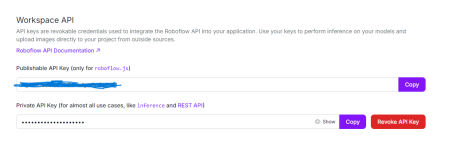 Python中使用OpenCV和Roboflow進行性別檢測 - 分析VidhyaApr 12, 2025 am 10:19 AM
Python中使用OpenCV和Roboflow進行性別檢測 - 分析VidhyaApr 12, 2025 am 10:19 AM介紹 從面部圖像中檢測性別是計算機視覺的眾多迷人應用之一。在這個項目中,我們將OpenCV結合在一起,以解決位置與性別分類的Roboflow API
 生成AI在個性化廣告內容中的作用是什麼?Apr 12, 2025 am 10:18 AM
生成AI在個性化廣告內容中的作用是什麼?Apr 12, 2025 am 10:18 AM介紹 自易貨系統概念以來,廣告世界一直在進化。廣告商找到了創造性的方法來引起我們的關注。在當前年齡,消費者期望BR
 Openai' o1-preview vs o1-mini:向前邁出的一步Apr 12, 2025 am 10:04 AM
Openai' o1-preview vs o1-mini:向前邁出的一步Apr 12, 2025 am 10:04 AM介紹 9月12日,OpenAI發布了一項名為“與LLM的學習推理”的更新。他們介紹了O1模型,該模型是使用強化學習來應對複雜推理任務的訓練。是什麼設置了此mod


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

Atom編輯器mac版下載
最受歡迎的的開源編輯器

SecLists
SecLists是最終安全測試人員的伙伴。它是一個包含各種類型清單的集合,這些清單在安全評估過程中經常使用,而且都在一個地方。 SecLists透過方便地提供安全測試人員可能需要的所有列表,幫助提高安全測試的效率和生產力。清單類型包括使用者名稱、密碼、URL、模糊測試有效載荷、敏感資料模式、Web shell等等。測試人員只需將此儲存庫拉到新的測試機上,他就可以存取所需的每種類型的清單。

DVWA
Damn Vulnerable Web App (DVWA) 是一個PHP/MySQL的Web應用程序,非常容易受到攻擊。它的主要目標是成為安全專業人員在合法環境中測試自己的技能和工具的輔助工具,幫助Web開發人員更好地理解保護網路應用程式的過程,並幫助教師/學生在課堂環境中教授/學習Web應用程式安全性。 DVWA的目標是透過簡單直接的介面練習一些最常見的Web漏洞,難度各不相同。請注意,該軟體中

SublimeText3 Linux新版
SublimeText3 Linux最新版

EditPlus 中文破解版
體積小,語法高亮,不支援程式碼提示功能

