
「位置嵌入」:Transformer背後的秘密

- 王林轉載
- 2023-04-10 10:01:031084瀏覽
譯者 | 崔皓
審查 | 孫淑娟
#目錄
- 簡介
- NLP中的嵌入概念
- 需要在變形金剛中進行位置嵌入
- 各種類型的初始試誤實驗
- #基於頻率的位置嵌入
- 總結
- 參考文獻
簡介
#深度學習領域中Transformer架構的引入無疑為無聲的革命鋪平了道路,對於NLP的分支而言特別重要。 Transformer架構中最不可或缺的就是“位置嵌入”,它使神經網路有能力理解長句中單字的順序和它們之間的依賴關係。
我們知道,RNN和LSTM,在Transformer之前就已經被引入,即使沒有使用位置嵌入,也有能力理解單字的排序。那麼,你會有一個明顯的疑問,為什麼這個概念會被引入到Transformer中,並且如此強調這個概念的優勢。這篇文章將把這些前因後果給您娓道。
NLP中的嵌入概念
#嵌入是自然語言處理中的一個過程,用於將原始文字轉換為數學向量。這是因為機器學習模型將無法直接處理文字格式,並將其用於各種內部計算過程。
針對Word2vec、Glove等演算法進行的嵌入過程稱為詞嵌入或靜態嵌入。
透過這種方式可以將包含大量單字的文字語料庫傳遞到模型中進行訓練。這個模型將為每個詞分配相應的數學值,假設那些出現頻率較高的詞是相似的。在這個過程之後,得出的數學值將用於進一步的計算。
比如說,考慮到我們的文本語料庫有3個句子,如下:
- 英國政府每年向巴勒莫的國王和王后發放大量補貼,聲稱對行政管理有一定控制權。
- 王室成員除了國王和王后之外,還包括他們的女兒瑪麗-特蕾莎-夏洛特(Madame Royale)、國王的妹妹伊麗莎白夫人、男僕克萊里和其他人。
- 這被莫德雷德背叛的消息打斷了,蘭斯洛特沒有參與最後的致命衝突,他在國王和王后面前都活了下來,而圓桌的衰落也是如此。
在這裡,我們可以看到「國王」和「女王」這兩個字經常出現。因此,該模型將假設這些詞之間可能存在一些相似性。當這些單字轉換為數學值時,在多維空間中表示時,它們會被放在一個小的距離上。
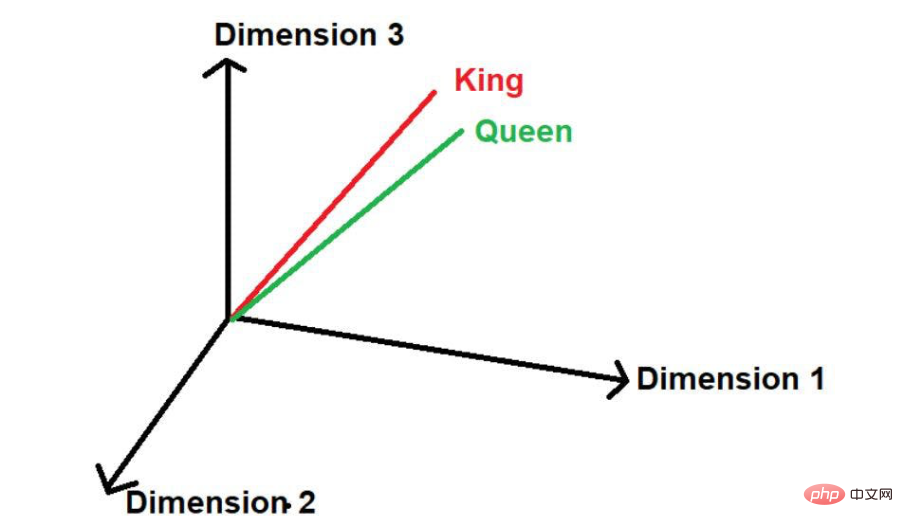
圖片來源:作者提供插圖
#假設有另一個單字“路”,那麼從邏輯上講,它不會像“國王”和“王后”一樣那麼頻繁地出現在這個大型文本語料庫中。因此,這個詞將遠離“國王”和“王后”並被遠遠地放在空間中的其他位置。
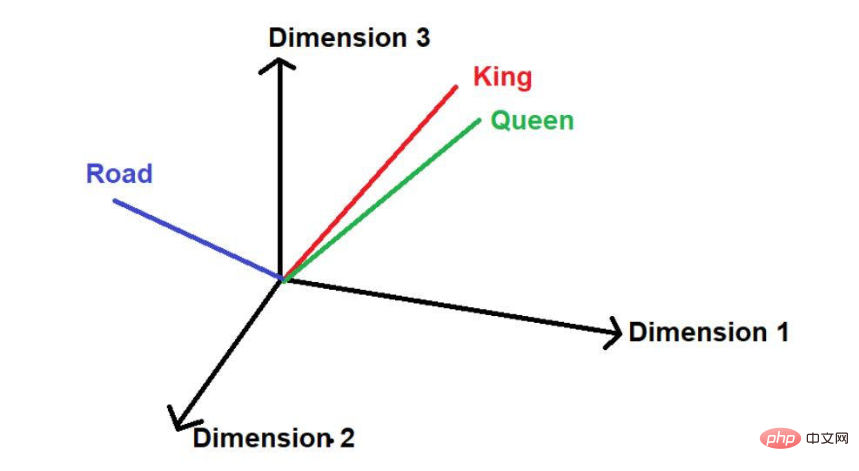
圖片來源:由作者提供插圖
在數學上,一個向量是用一連串的數字來表示的,其中每個數字代表這個詞在某個特定維度上的大小。比如說:我們在這裡把
因此,「國王」在三維空間中以[0.21,0.45,0.67]的形式表示。
字 "女王 "可以表示為[0.24,0.41,0.62]。
詞 "Road "可以表示為[0.97,0.72,0.36]。
需要在Transformer中進行位置嵌入
正如我們在介紹部分所討論的,對位置嵌入的需求是為了使神經網路理解句子中的排序和位置依賴性。
例如,讓我們考慮以下句子:
第1句--"雖然薩欽-坦杜爾卡今天沒有打出100分,但他帶領球隊獲得了勝利」。
第2句--"雖然薩欽-坦杜爾卡今天打出100分,但他沒能領球隊獲得了勝利"。
這兩個句子看起來很相似,因為它們共享大部分的單字,但它們的內在意義卻非常不同。沒"這樣的字的排序和位置已經改變了傳達訊息的背景。
因此,在NLP專案中,理解位置資訊是非常關鍵的。如果模型只是使用多維空間中的數字而誤解了上下文,就會導致嚴重的後果,特別是在預測性模型中。
為了克服這個挑戰,神經網路架構,如RNN(循環神經網路)和LSTM(長期短時間記憶)被引入。在某種程度上,這些架構在理解位置資訊方面非常成功。他們成功背後的主要秘密是,透過保留單字的順序來學習長句子。除此之外,它們還擁有關於離 "感興趣的詞 "很近的詞和離 "感興趣的詞 "很遠的詞的信息。
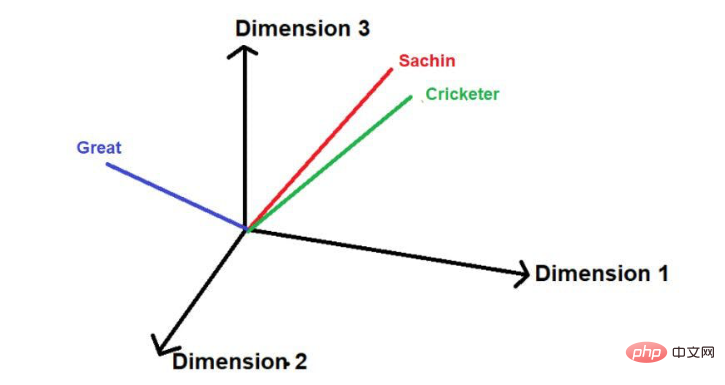
比如說,請考慮以下句子--
"薩欽是有史以來最偉大的板球運動員」。

圖片來源:作者提供插圖
紅色底線的單字是這些字的。這裡可以看到,"感興趣的詞 "是按照原文的順序來遍歷的。
此外,他們還可以透過記住

圖片來源:由作者提供插圖
#雖然,透過這些技術,RNN/ LSTM可以理解大型文字語料庫中的位置資訊。但是,真正的問題是對大型文字語料庫中的單字進行順序遍歷。想像一下,我們有一個非常大的文本語料庫,其中有100萬個詞,按順序遍歷每一個字需要非常長的時間。有時,為訓練模型承擔這麼多的計算時間是不可行的。
為了克服這個挑戰,引進了一個新的先進架構--"Transformer"。
Transformer架構的一個重要特點是,可以透過並行處理所有單字來學習一個文字語料庫。無論文字語料庫包含10個字或100萬個字,Transformer架構並不關心。

圖片來源:作者提供插圖

#圖片來源:作者提供插圖
現在,我們需要面對並行處理單字的挑戰了。因為所有的單字都是同時存取的,所以單字之間的依賴性資訊會遺失。因此,模型無法記住某一個特定單字的關聯資訊也無法準確地保存下來。這個問題再次將我們引向最初的挑戰,即儘管模型的計算/訓練時間大大減少,但仍要保留上下文的依賴關係。 那麼如何解決上述問題呢?解決方案是不斷試誤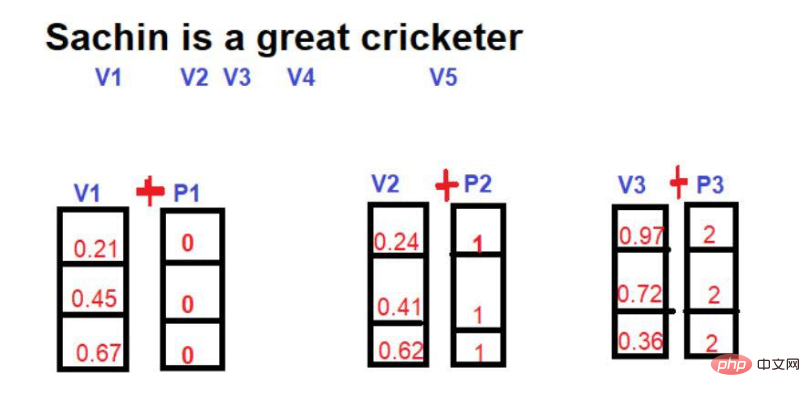 最初,當這個概念被引入時,研究人員非常渴望得出優化的方法,可以在Transformer結構中保留位置資訊。作為試誤實驗的一部分,嘗試的第一個方法是
最初,當這個概念被引入時,研究人員非常渴望得出優化的方法,可以在Transformer結構中保留位置資訊。作為試誤實驗的一部分,嘗試的第一個方法是
在這裡,我們的想法是在使用單字向量的同時引入新的數學向量,該向量包含單字的索引。
 圖片來源:作者提供插圖
圖片來源:作者提供插圖
假設下圖是詞語在多維空間中的代表
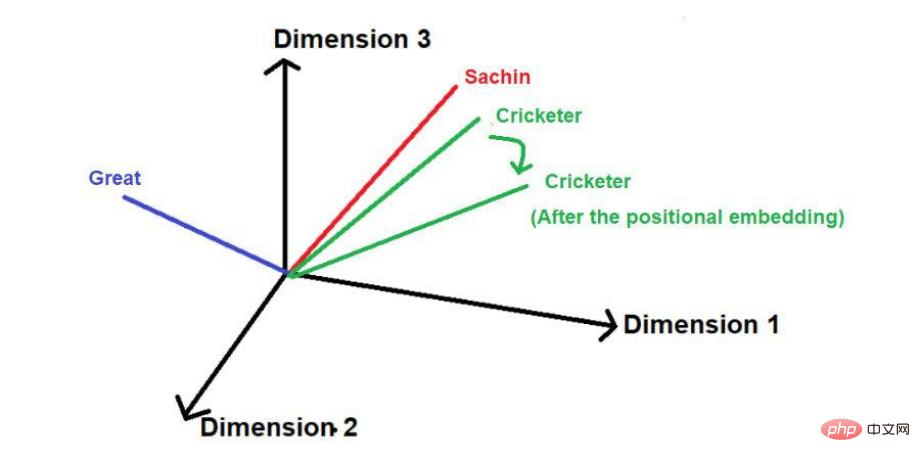 圖片來源:由作者提供插圖
圖片來源:由作者提供插圖
在加入位置向量後,其大小和方向可能會像下圖這樣改變每個單字的位置。
圖片來源:由作者提供插圖這種技巧的缺點是,如果句子特別長,那麼位置向量會按比例隨之增加。比方說,一個句子有25個單詞,那麼第一個單字將被加上一個幅度為0的位置向量,最後一個單字將會被加上一個幅度為24的位置向量。當我們在更高的維度上投射這些數值時,這種巨大的不確定性可能會造成問題。 另一種用來減少位置向量的技術是在這裡,每個單字相對於句子長度的分數值被計算為位置向量的幅度。 分數值的計算公式為######價值=1/N-1#######其中 "N "是某一特定字的位置。 ###比如說,讓我們考慮如下圖的例子--
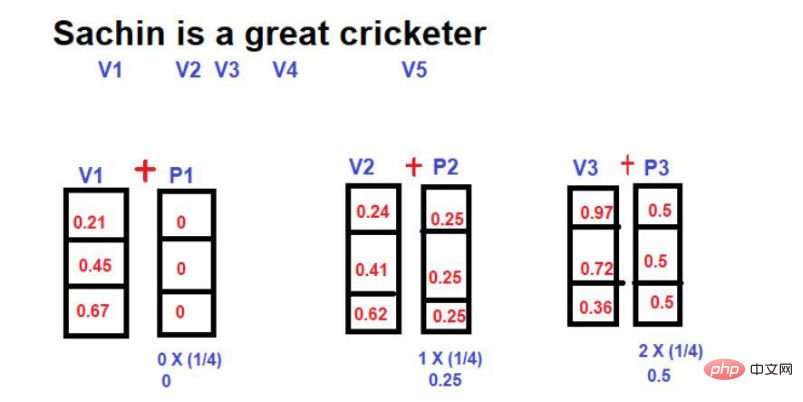
圖片來源:由作者提供插圖
在這種技術中,無論句子的長度如何,位置向量的最大幅度都可以限定為1。但是,也存在著一個很大的漏洞。如果比較兩個長度不同的句子,某個特定位置上單字的嵌入值就會不同。特定的詞或其對應的位置應該在整個文本語料庫中擁有相同的嵌入值,以方便理解其上下文。如果不同句子中的同一個字擁有不同的嵌入值,那麼在一個多維空間中表示文字語料庫的資訊將成為非常複雜的任務。即使實現了這樣一個複雜的空間,模型也很有可能因為過多的資訊失真而在某一點上崩潰。因此,這種技術被排除在Transformer位置嵌入的發展之外了。
最後,研究人員提出了一個Transformer架構,並在著名的白皮書中提到--"注意力是你需要的一切"。
基於頻率的位置嵌入
根據這項技術,研究人員推薦了一種基於波頻的文字嵌入方式,使用以下公式---
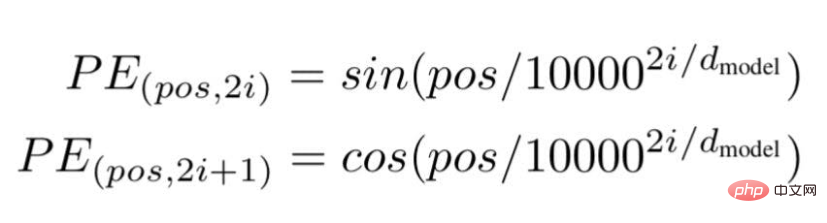
圖片來源:由作者提供插圖
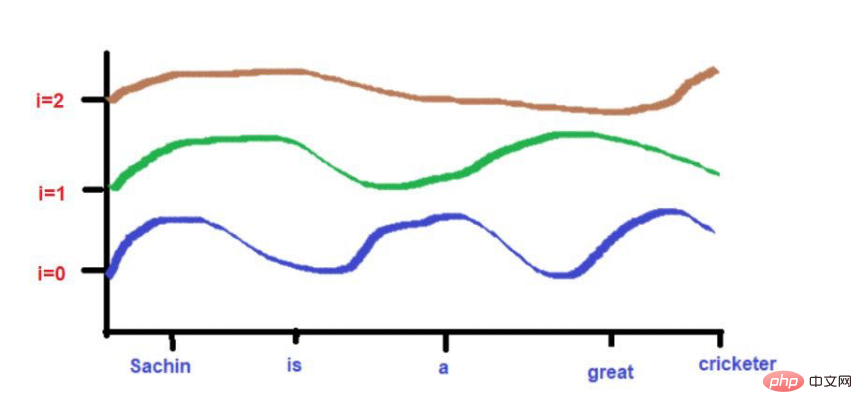
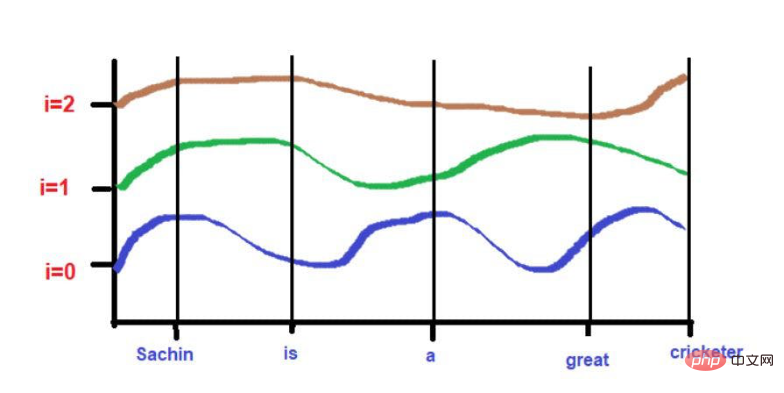
由於曲線的高度取決於X軸上所描述的單字位置,所以曲線的高度可以作為單字位置的代理。如果2個字的高度相似,那麼我們可以認為它們在句子中的接近度非常高。同樣,如果兩個字的高度相差很大,那麼我們可以認為它們在句子中的接近度很低。
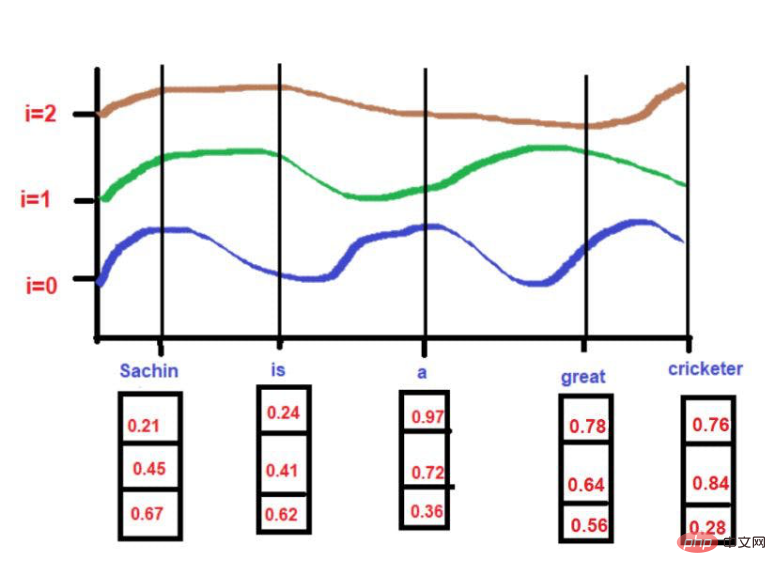
根據我們的例子文本--"薩欽是一位偉大的板球運動員"。
對
pos = 0
d = 3
i[0] = 0.21, i[1] = 0.45, i[2] = 0.67 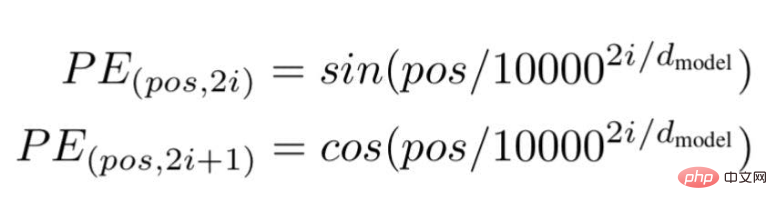
圖片來源:作者提供插圖
當 i =0,
PE(0,0) = sin(0/ 10000^2(0)/3)
PE(0,0) = sin(0)
PE(0,0) = 0
當 i =1 ,
PE(0,1) = cos(0/10000^2(1)/3)
PE(0,1) = cos(0)
# PE(0,1) = 1
當 i =2,
PE(0,2) = sin(0/10000^2(2)/3)
#PE(0,2) = sin(0)
PE(0,2) = 0
對於
pos = 3
##d = 3i[0] = 0.78, i[1] = 0.64, i[2] = 0.56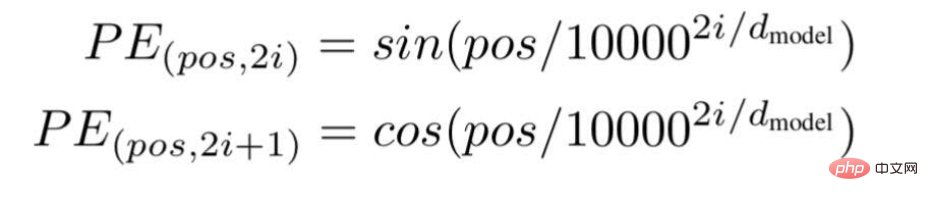 在應用公式的同時。
在應用公式的同時。
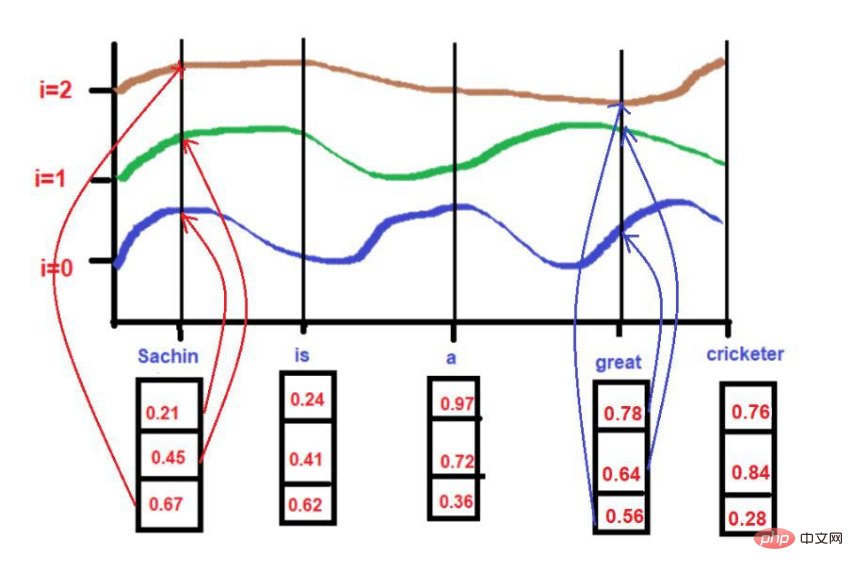 PE(3,2) = 0.03
PE(3,2) = 0.03
##圖片來源:由作者提供插圖
###在這裡,最大值將被限制在1(因為我們使用的是sin/cos函數)。因此,不存在早期技術中高量級位置向量的問題。 ###此外,彼此高度接近的字在較低的頻率下可能落在相似的高度,而在較高的頻率下它們的高度會有一點不同。
如果單字與單字之間的距離很近,那麼即使在較低的頻率下,它們的高度也會有很大的差異,而且它們的高度差異會隨著頻率的增加而增加。
比如說,考慮一下這句話--"國王和王后在路上行走"。
「國王"和 "路 "這兩個字放在較遠的位置。
考慮到在應用波頻公式後,這兩個字的高度大致相似。當我們達到更高的頻率(如0)時,它們的高度將變得更不一樣。
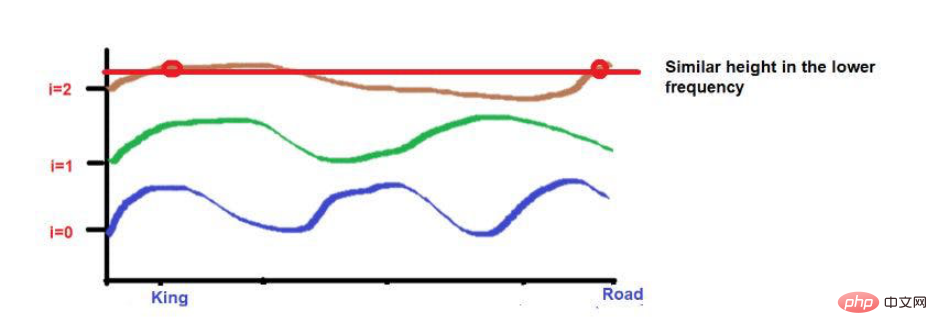
圖片來源:作者提供插圖
#圖片來源:作者提供插圖
圖片來源:由作者提供插圖
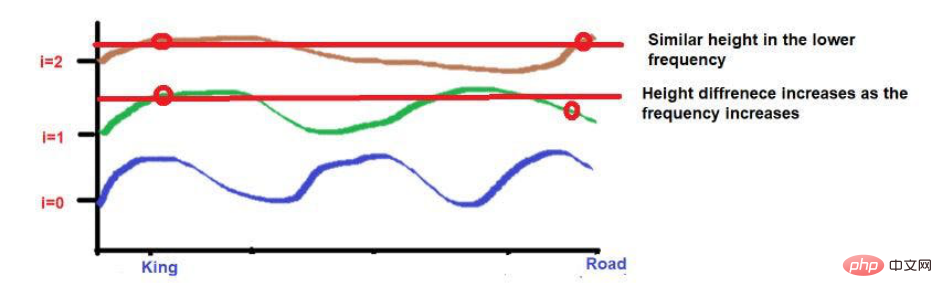
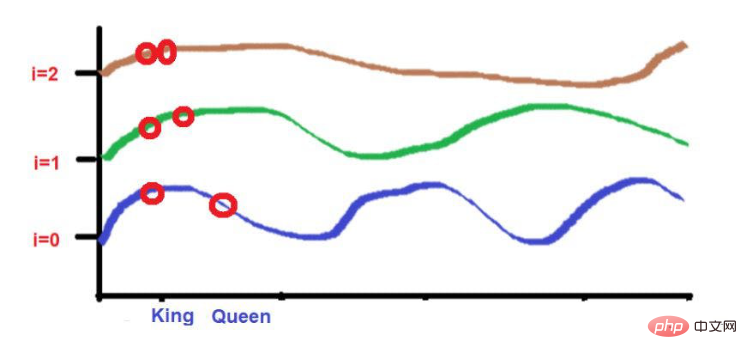 而「國王」和」王后"這兩個詞被放置在較近的位置。
而「國王」和」王后"這兩個詞被放置在較近的位置。
這2個字在較低的頻率(如這裡的2)中會被放置在相似的高度。當我們達到較高的頻率(如0)時,它們的高度差會增加一點,以便進行區分。
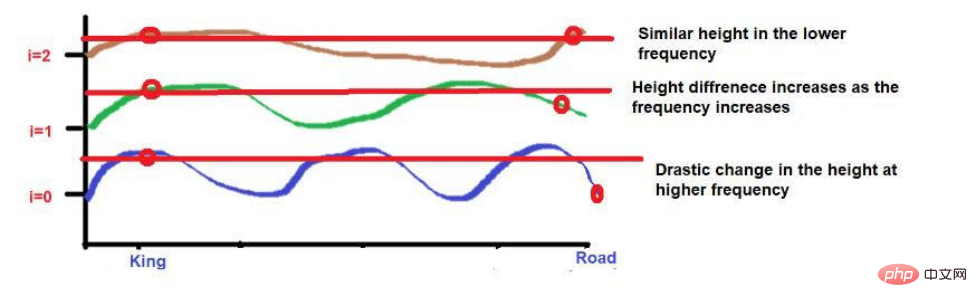
圖片來源:由作者提供插圖但我們需要注意的是,如果這些詞的接近程度較低,當向高頻率發展時,它們的高度將有很大的不同。如果單字的接近度很高,那麼當向更高頻率發展時,它們的高度將只有一點點的差異。 總結透過這篇文章,我希望你對機器學習中位置嵌入背後複雜的數學計算有一個直觀的了解。簡而言之,我們討論了從而實現某些目標的需要。 對於那些對 "自然語言處理 "感興趣的技術愛好者來說,我認為這些內容對理解複雜的計算方法是有幫助的。更詳細的信息,可以參考著名的研究論文--"注意力是你所需要的一切"。譯者介紹崔皓,51CTO社群編輯,資深架構師,擁有18年的軟體開發與架構經驗,10年分散式架構經驗。 原文標題:#Positional Embedding: The Secret behind the Accuracy of Transformer Neural Networks
######,作者:Sanjay Kumar#########以上是「位置嵌入」:Transformer背後的秘密的詳細內容。更多資訊請關注PHP中文網其他相關文章!