



文字產生任務通常採用 teacher forcing 的方式來訓練,這種訓練方式使得模型在訓練過程中只能見到正樣本。然而生成目標與輸入之間通常會存在某些約束,這些約束通常由句子中的關鍵元素體現,例如在query 改寫任務中,“麥當勞點餐” 不能改成“肯德基點餐”,這裡面起到約束作用的關鍵元素是品牌關鍵字。透過引入對比學習在生成的過程中加入負樣本的模式使得模型能夠有效地學習到這些限制。
現有的基於對比學習方法主要集中在整句層面實現[1][2],而忽略了句子中的詞粒度的實體的訊息,下圖中的例子展示了句子中關鍵字的重要意義,對於一個輸入的句子,如果對它的關鍵字進行替換(e.g. cosmology->astrophysics),句子的含義會發生變化,從而在語義空間中的位置(由分佈來表示)也會改變。而關鍵字作為句子中最重要的訊息,對應於語意分佈上的一個點,它很大程度上也決定了句子分佈的位置。同時,在某些情況下,現有的對比學習目標對模型來說顯得過於容易,導致模型無法真正學習到區分正負例之間的關鍵資訊。
基於此,來自螞蟻集團、北大等機構的研究者提出了一種多粒度對比生成方法,設計了層次化對比結構,在不同層級上進行資訊增強,在句子粒度上增強學習整體的語義,在詞粒度上增強局部重要資訊。研究論文已被 ACL 2022 接收。

論文網址:https://aclanthology.org/2022.acl-long.304.pdf

#方法
我們的方法是基於經典的CVAE文本生成框架[3][4],每個句子都可以映射成為向量空間中的一個分佈,而句子中的關鍵字則可以看成是這個分佈上採樣得到的一個點。我們一方面透過句子粒度的對比來增強隱空間向量分佈的表達,另一方面透過構造的全局關鍵字graph 來增強關鍵字點粒度的表達,最後透過馬氏距離對關鍵字的點和句子的分佈構造層次間的對比來增強兩個粒度的訊息表達。最終的損失函數由三種不同的對比學習 loss 相加而得到。

句子粒度對比學習
##在Instance-level,我們利用原始輸入x、目標輸出

#及對應的輸出負樣本構成了句子粒度的比較pair

。我們利用一個先驗網路學習到先驗分佈

#,記為

#;透過一個後驗網路學習到近似的後驗分佈

與

#,分別記為

#和

。句子粒度對比學習的目標就是盡可能縮小先驗分佈和正後驗分佈的距離,同時盡可能推大的先驗分佈與負後驗分佈的距離,對應的損失函數如下:

其中為正樣本或負樣本,為溫度係數,用來表示距離度量,這裡我們使用KL 散度(Kullback–Leibler divergence )[5] 來測量兩個分佈直接的距離。
關鍵字粒度對比學習
- 關鍵字網絡
關鍵字粒度的對比學習是用來讓模型更多的關注到句子中的關鍵訊息,我們透過利用輸入輸出文字對應的正負關係建構一個keyword graph 來達到這個目標。具體來說,根據一個給定的句對

,我們可以分別從其中確定一個關鍵字

和


#(關鍵字抽取的方法我採用經典的TextRank 演算法[6]);對於一個句子



## ,可能存在與其關鍵字

#相同的其他句子,這些句子共同組成一個集合

與負例關鍵字

#。這樣在整個集合中,對任何一個輸出的句子

#,可以認為它所對應的關鍵字

與每個周圍的

(透過句子之間的正負關係關聯)之間都存在著一條正邊

,和每一個周圍的

#之間都存在一條負邊

#。基於這些關鍵字節點和他們直接的邊,我們就可以建構一個keyword graph

我們使用BERT embedding[7] 來作為每個節點

的初始化,並使用一個MLP層來學習每條邊的表示

。我們透過一個graph attention (GAT) 層和MLP 層來迭代式地更新關鍵字網路中的節點和邊,每個迭代中我們先透過如下的方式更新邊的表示:

##這裡

可以是

或

#。
############然後根據更新後的邊##########
,我們透過一個graph attention 層來更新每個節點的表示:

這裡

#都是可學習的參數,

#為注意力權重。為了防止梯度消失的問題,我們在

#上加上了殘差連接,得到該迭代中節點的表示

。我們使用最後一個迭代的節點表示作為關鍵字的表示,記為 u。
- 關鍵字比較


關鍵字粒度的比較來自於輸入句子的關鍵字

和一個偽裝(impostor)節點

。我們將輸入句子的輸出正樣本中提取的關鍵字記為

,它在上述關鍵字網路中的負鄰居節點記為

,則

,關鍵字粒度的比較學習loss 計算如下:

這裡

,h(·) 用來表示距離測量,在關鍵字粒度的對比學習中我們選用了餘弦相似度來計算兩個點之間的距離。
- 在跨粒度對比學習

#可以注意到上述句子粒度和關鍵字粒度的對比學習分別是在分佈和點上實現,這樣兩個粒度的獨立對比可能由於差異較小導致增強效果減弱。對此,我們基於點和分佈之間的馬氏距離(Mahalanobis distance)[8] 構建不同粒度之間對比關聯,使得目標輸出關鍵字到句子分佈的距離盡可能小於imposter 到該分佈的距離,從而彌補各粒度獨立對比可能帶來的對比消失的缺陷。具體來說,跨粒度的馬氏距離對比學習希望盡可能縮小句子的後驗語義分佈

和

之間的距離,同時盡可能拉大其與

之間的距離,損失函數如下:



這裡
同樣用來指
#或

#,而h(·) 為馬氏距離。

消融分析
我們對是否採用關鍵字、是否採用關鍵字網路以及是否採用馬氏距離對比分佈進行了消融分析實驗,結果顯示這三種設計對最後的結果確實起到了重要的作用,實驗結果如下圖所示。

視覺化分析
為了研究不同層級對比學習的作用,我們對隨機採樣的case 進行了可視化,透過t-sne[22] 進行降維處理後得到下圖。圖中可以看出,輸入句子的表示與抽取的關鍵字表示接近,這說明關鍵字作為句子中最重要的訊息,通常會決定語義分佈的位置。並且,在對比學習中我們可以看到經過訓練,輸入句子的分佈與正樣本更接近,與負樣本遠離,這說明對比學習可以起到幫助修正語意分佈的作用。

關鍵字重要性分析
最後,我們探討採樣不同關鍵字的影響。如下表所示,對於一個輸入問題,我們透過 TextRank 抽取和隨機選擇的方法分別提供關鍵字作為控制語意分佈的條件,並檢查產生文字的品質。關鍵字作為句子中最重要的訊息單元,不同的關鍵字會導致不同的語意分佈,產生不同的測試,選擇的關鍵字越多,產生的句子越準確。同時,其他模型產生的結果也展示在下表中。

業務應用程式
這篇文章中我們提出了一種跨粒度的層次化對比學習機制,在多個文本生成的資料集上均超過了具有競爭力的基線工作。基於該工作的 query 改寫模型在也在支付寶搜尋的實際業務場景成功落地,取得了顯著的效果。支付寶搜尋中的服務覆蓋領域寬廣且領域特色顯著,用戶的搜尋query 表達與服務的表達存在巨大的字面差異,導致直接基於關鍵字的匹配難以取得理想的效果(例如用戶輸入query「新上市汽車查詢”,無法召回服務“新車上市查詢”),query 改寫的目標是在保持query 意圖不變的情況下,將用戶輸入的query 改寫為更貼近服務表達的方式,從而更好的匹配到目標服務。如下是一些改寫範例:

以上是提升支付寶搜尋體驗,螞蟻、北大基於層次化對比學習文本生成框架的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 扩散+超分辨率模型强强联合,谷歌图像生成器Imagen背后的技术Apr 10, 2023 am 10:21 AM
扩散+超分辨率模型强强联合,谷歌图像生成器Imagen背后的技术Apr 10, 2023 am 10:21 AM近年来,多模态学习受到重视,特别是文本 - 图像合成和图像 - 文本对比学习两个方向。一些 AI 模型因在创意图像生成、编辑方面的应用引起了公众的广泛关注,例如 OpenAI 先后推出的文本图像模型 DALL・E 和 DALL-E 2,以及英伟达的 GauGAN 和 GauGAN2。谷歌也不甘落后,在 5 月底发布了自己的文本到图像模型 Imagen,看起来进一步拓展了字幕条件(caption-conditional)图像生成的边界。仅仅给出一个场景的描述,Imagen 就能生成高质量、高分辨率
 深度学习撞墙?LeCun与Marcus到底谁捅了马蜂窝Apr 09, 2023 am 09:41 AM
深度学习撞墙?LeCun与Marcus到底谁捅了马蜂窝Apr 09, 2023 am 09:41 AM今天的主角,是一对AI界相爱相杀的老冤家:Yann LeCun和Gary Marcus在正式讲述这一次的「新仇」之前,我们先来回顾一下,两位大神的「旧恨」。LeCun与Marcus之争Facebook首席人工智能科学家和纽约大学教授,2018年图灵奖(Turing Award)得主杨立昆(Yann LeCun)在NOEMA杂志发表文章,回应此前Gary Marcus对AI与深度学习的评论。此前,Marcus在杂志Nautilus中发文,称深度学习已经「无法前进」Marcus此人,属于是看热闹的不
 GPT-4的研究路径没有前途?Yann LeCun给自回归判了死刑Apr 04, 2023 am 11:55 AM
GPT-4的研究路径没有前途?Yann LeCun给自回归判了死刑Apr 04, 2023 am 11:55 AMYann LeCun 这个观点的确有些大胆。 「从现在起 5 年内,没有哪个头脑正常的人会使用自回归模型。」最近,图灵奖得主 Yann LeCun 给一场辩论做了个特别的开场。而他口中的自回归,正是当前爆红的 GPT 家族模型所依赖的学习范式。当然,被 Yann LeCun 指出问题的不只是自回归模型。在他看来,当前整个的机器学习领域都面临巨大挑战。这场辩论的主题为「Do large language models need sensory grounding for meaning and u
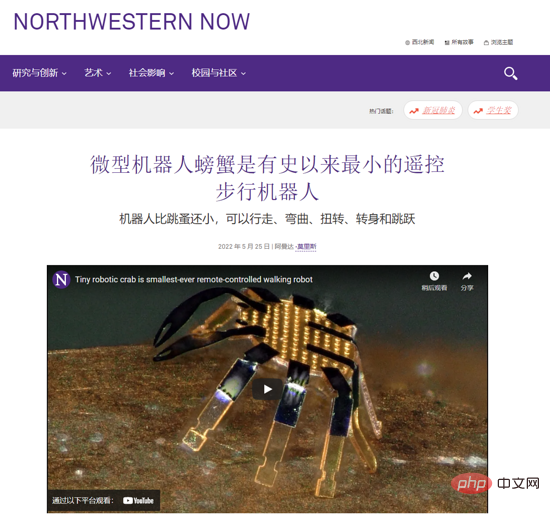 科学家展示世界上有史以来超小的“螃蟹”遥控步行机器人,体积比跳蚤还小Apr 09, 2023 pm 10:41 PM
科学家展示世界上有史以来超小的“螃蟹”遥控步行机器人,体积比跳蚤还小Apr 09, 2023 pm 10:41 PM日前,美国西北大学工程师开发出有史以来最小的遥控步行机器人,它以一种小巧可爱的螃蟹形式出现。这种微小的“螃蟹”机器人宽度只有半毫米,可以弯曲、扭曲、爬行、行走、转弯甚至跳跃,无需液压或电力。IT之家了解到,相关研究成果发表在《科学・机器人》上。据介绍,这种机器人是用形状记忆合金材料所制造的,然后可以变成所需的形状,当你加热后又会变回原来的形状,而热量消失时可以再次弹回变形时的样子。据介绍,其热量是由激光所带来的。激光通过“螃蟹”加热合金,但因为它们非常小,所以热量传播非常快,这使得它们的响应速度
 用魔法打败魔法!一个叫板顶级人类棋手的围棋AI输给了它的同类Apr 12, 2023 am 08:40 AM
用魔法打败魔法!一个叫板顶级人类棋手的围棋AI输给了它的同类Apr 12, 2023 am 08:40 AM近几年,自我博弈中的强化学习已经在围棋、国际象棋等一系列游戏中取得了超人的表现。此外,自我博弈的理想化版本还收敛于纳什均衡。纳什均衡在博弈论中非常著名,该理论是由博弈论创始人,诺贝尔奖获得者约翰 · 纳什提出,即在一个博弈过程中,无论对方的策略选择如何,当事人一方都会选择某个确定的策略,则该策略被称作支配性策略。如果任意一位参与者在其他所有参与者的策略确定的情况下,其选择的策略是最优的,那么这个组合就被定义为纳什均衡。之前就有研究表明,自我博弈中看似有效的连续控制策略也可以被对抗策略利用,这表明
 参数少量提升,性能指数爆发!谷歌:大语言模型暗藏「神秘技能」Apr 11, 2023 pm 11:16 PM
参数少量提升,性能指数爆发!谷歌:大语言模型暗藏「神秘技能」Apr 11, 2023 pm 11:16 PM由于可以做一些没训练过的事情,大型语言模型似乎具有某种魔力,也因此成为了媒体和研究员炒作和关注的焦点。当扩展大型语言模型时,偶尔会出现一些较小模型没有的新能力,这种类似于「创造力」的属性被称作「突现」能力,代表我们向通用人工智能迈进了一大步。如今,来自谷歌、斯坦福、Deepmind和北卡罗来纳大学的研究人员,正在探索大型语言模型中的「突现」能力。解码器提示的 DALL-E神奇的「突现」能力自然语言处理(NLP)已经被基于大量文本数据训练的语言模型彻底改变。扩大语言模型的规模通常会提高一系列下游N
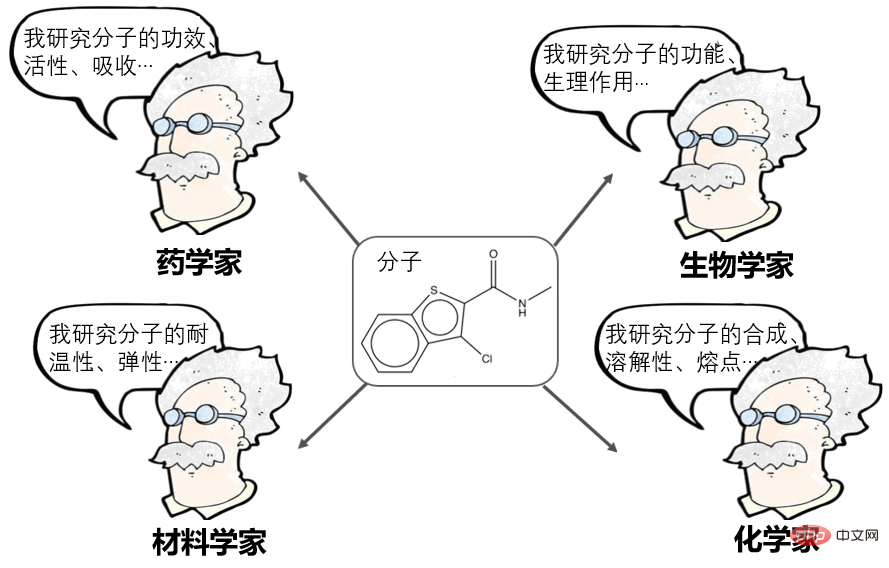 介绍全球首个基于自监督学习的分子图像生成框架ImageMolApr 23, 2023 pm 12:46 PM
介绍全球首个基于自监督学习的分子图像生成框架ImageMolApr 23, 2023 pm 12:46 PM分子是维持物质化学稳定性的最小单位。对分子的研究,是药学、材料学、生物学、化学等众多科学领域的基础性问题。分子的表征学习(MolecularRepresentationLearning)是近年来非常热门的方向,目前可分为诸多门派:计算药学家说:分子可以表示为一串指纹,或者描述符,如上海药物所提出的AttentiveFP,是这方面的杰出代表。NLPer说:分子可以表示为SMILES(序列),然后当作自然语言处理,如百度的X-Mol,是这方面的杰出代表。图神经网络研究者说:分子可以表示为一个图(G
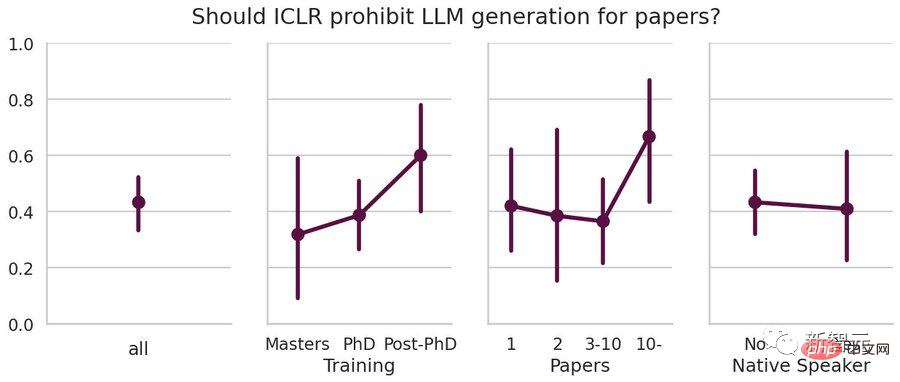 LeCun, 获得图灵奖的科学家表示支持使用LLM撰写论文。科研界的老将可能更不喜欢ChatGPT?May 09, 2023 am 10:22 AM
LeCun, 获得图灵奖的科学家表示支持使用LLM撰写论文。科研界的老将可能更不喜欢ChatGPT?May 09, 2023 am 10:22 AMChatGPT发布后,「用语言模型辅助论文写作」到底算作弊剽窃,还是合理使用写作工具,目前各高校、论文会议中仍然没有统一标准,甚至不同的科研人员对ChatGPT都持有不同的态度。有人认为ChatGPT可以提高写作质量,让非英语母语者减少语法错误等;但也有人认为生成的文字并不属于作者,违反学术道德。最近,康奈尔大学的副教授AlexanderRush在参加ICLR2023期间,在会议交流时采访了多位参会人员对「用LLM写论文」的态度。从结果来看,支持与反对占比基本五五开,并且支持和反对的程度相差无几


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

VSCode Windows 64位元 下載
微軟推出的免費、功能強大的一款IDE編輯器

WebStorm Mac版
好用的JavaScript開發工具

DVWA
Damn Vulnerable Web App (DVWA) 是一個PHP/MySQL的Web應用程序,非常容易受到攻擊。它的主要目標是成為安全專業人員在合法環境中測試自己的技能和工具的輔助工具,幫助Web開發人員更好地理解保護網路應用程式的過程,並幫助教師/學生在課堂環境中教授/學習Web應用程式安全性。 DVWA的目標是透過簡單直接的介面練習一些最常見的Web漏洞,難度各不相同。請注意,該軟體中

SecLists
SecLists是最終安全測試人員的伙伴。它是一個包含各種類型清單的集合,這些清單在安全評估過程中經常使用,而且都在一個地方。 SecLists透過方便地提供安全測試人員可能需要的所有列表,幫助提高安全測試的效率和生產力。清單類型包括使用者名稱、密碼、URL、模糊測試有效載荷、敏感資料模式、Web shell等等。測試人員只需將此儲存庫拉到新的測試機上,他就可以存取所需的每種類型的清單。

Atom編輯器mac版下載
最受歡迎的的開源編輯器

