


arXiv論文“Tackling Real-World Autonomous Driving using Deep Reinforcement Learning“,上傳於2022年7月5日,作者來自義大利的帕爾馬大學Vislab和安霸公司(收購Vislab)。

在典型的自主駕駛管線中,規則控制系統代表了兩個最關鍵的元件,其中感測器擷取的資料和感知演算法處理的資料用於實現安全舒適的自動駕駛行為。特別是,規劃模組預測自動駕駛汽車在執行正確的高級操作時應遵循的路徑,同時控制系統執行一系列低階操作,控制轉向、油門和煞車。
這項工作提出一種無模型(model- free)深度強化學習(DRL)規劃器,訓練一個預測加速度和轉向角的神經網絡,從而獲得一個用自主駕駛汽車的定位和感知演算法輸出的數據駕駛車輛的單一模組。特別是,經過充分模擬訓練的系統能夠在模擬和真實(帕爾馬城區)無障礙環境中平穩安全地駕駛,證明了該系統具有良好的泛化能力,也可以在訓練場景以外的環境駕駛。此外,為了將系統部署在真實的自動駕駛汽車上,並減少模擬性能和真實性能之間的差距,作者還開發一個由微型神經網路表示的模組,該模組能夠在模擬訓練期間復現真實環境的汽車動態行為。
在過去幾十年中,從簡單的、基於規則的方法到實現基於AI的智慧系統,車輛自動化等級的提高取得了巨大進展。特別是,這些系統旨在解決基於規則的方法的主要局限性,即缺乏與其他道路使用者的協商和交互,以及對場景動態性理解較差。
強化學習(RL)廣泛用於解決使用離散控制空間輸出的任務,如圍棋、Atari遊戲或西洋棋以及連續控制空間的自主駕駛。特別是,RL演算法廣泛應用於自主駕駛領域,用於開發決策和機動執行系統,如主動變換車道、車道維持、超車機動、十字路口和環島處理等。
本文採用D-A3C的延遲版本,屬於所謂的Actor-Critics演算法家族。特別由兩個不同的實體組成:Actor和Critics。 Actor的目的是選擇智體必須執行的動作,而Critics 估計狀態值函數,也就是智體特定狀態的良好程度。換句話說,Actor是動作上的機率分佈π(a | s;θπ)(其中θ是網路參數),critics是估計態值函數v(st;θv)=E(Rt | st),其中R是期待的回報。
內部開發的高清地圖實現了模擬模擬器;場景的示例如圖a所示,是在真實自動駕駛汽車測試系統的部分地圖區域,而圖b顯示智體感知的周圍視圖,對應於50×50公尺的區域,被分為四個通道:障礙物(圖c),可駕駛空間(圖d)、智體應遵循的路徑(圖e)和停止線(圖f)。模擬器中高清地圖允許檢索有關外部環境的多個信息,如位置或車道數、道路限速等。
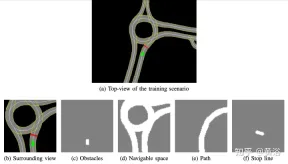
專注於實現平穩安全的駕駛風格,因此在靜態場景中訓練智體,不包括障礙物或其他道路使用者,學習遵循路線並遵守速度限制。
使用如圖所示的神經網路對智體進行訓練,每100毫秒預測一次轉向角和加速度。分為兩個子模組:第一個子模組能夠定義轉向角sa,第二個子模組用來定義加速度acc。這兩個子模組的輸入由4個通道(可駕駛空間、路徑、障礙物和停止線)表示,對應於智體的周圍視圖。每個視覺輸入通道包含4個84×84像素的影像,以便為智體提供過去狀態的歷史。與此視覺輸入一起,網路接收5個標量參數,包括目標速度(道路速度限制)、智體的當前速度、當前速度-目標速度比,以及與轉向角和加速度相關的最後動作。
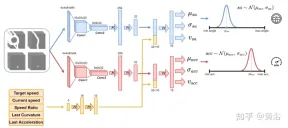
為了確保探索(exploration),採用兩個高斯分佈對兩個子模組輸出進行取樣,獲得相對加速度(acc=N(μacc,σacc))和轉向角(sa=N(μsa,σsa))。標準差σacc和σsa在訓練階段由神經網路預測和調製,估計模型的不確定性。此外,此網路使用兩個不同的獎勵函數R-acc-t和R-sa-t,分別與加速度和轉向角相關,產生相應的狀態值估計(vacc和vsa)。
神經網路在帕爾馬城市的四個場景進行訓練。對於每個場景,建立多個實例,智體在這些實例上相互獨立。每個智體遵循運動學自行車模型,取值轉向角為[-0.2, 0.2],加速度為[-2.0 m, 2.0 m]。在該片段開始時,每個智體以隨機速度([0.0, 8.0])開始駕駛,並遵循其預定路徑,並遵守道路速度限制。該城區的道路速度限制在4 ms到8.3 ms之間。
最後,由於訓練場景中沒有障礙物,因此片段可以在以下一種終端狀態下結束:
- 達成目標:智體達到最終目標位置。
- 駕駛出道路:智體超出其預定路徑,錯誤地預測轉向角。
- 時間到了:完成片段的時間失效;這主要是由於加速度輸出的謹慎預測,駕駛速度低於道路速度限制。
為了獲得能夠在模擬和真實環境中順利駕駛汽車的策略,獎勵成型對實現預期行為至關重要。特別是,定義兩個不同的獎勵函數來分別評估兩個動作:R-acc-t和R-sa-t分別與加速度和轉向角有關,定義如下:
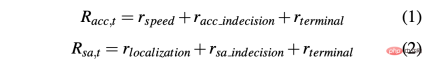
其中
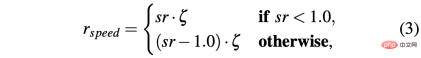
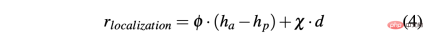
R-sa-t和R-acc-t在公式中都有一個元素,用於懲罰兩個連續動作,其加速度和轉向角的差值分別大於某個閾值δacc和δsa。特別是,兩個連續加速度之間的差異計算如下:∆acc=| acc(t)− acc(t− 1) | ,而racc_indecision的定義如下:
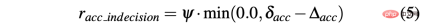
相反,轉向角的兩個連續預測之間的差異計算為∆sa=| sa(t)− sa(t− 1)|, 而rsa_indecision定義如下:
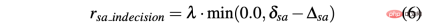
#最後,R-acc-t和R-sa-t取決於智體實現的終端狀態:
- 達成目標:代理人達到目標位置,因此兩個獎勵的rterminal設定為1.0;
- 駕駛出道路:智能體偏離其路徑,主要是由於對轉向角的預測不準確。因此,將負訊號-1.0指定給Rsa,t,負訊號0.0給R-acc-t;
- 時間到了:完成該片段的可用時間失效,這主要是由於智體的加速預測過於謹慎;因此,rterminal假設−1.0給R-acc-t,0.0給R-sa-t。
與模擬器相關的主要問題之一在於模擬數據和真實數據之間的差異,這是由於難以在模擬器內真實再現真實世界的情況造成的。為了克服這個問題,用一個合成模擬器來簡化神經網路的輸入,並減少模擬數據和真實數據之間的差距。事實上,4個作為神經網路輸入的通道(障礙物、駕駛空間、路徑和停止線)所包含的資訊可以透過感知和定位演算法以及嵌入在真實自動駕駛汽車上的高清地圖輕鬆再現。
此外,使用模擬器的另一個相關問題與模擬智體執行目標動作與自動駕駛汽車執行該命令的兩個方式不同有關。實際上,在時間t計算的目標動作,理想情況下可以在模擬的同一精確時刻立即生效。不同的是,這不會發生在真實車輛上,因為真實情況是,此類目標動作將以某種動態執行,從而導致執行延遲(t δ)。因此,有必要在模擬中引入此類反應時間,以便在真正的自動駕駛汽車上訓練智體去處理此類延遲。
為此,為了實現更真實的行為,首先訓練智體,將低通濾波器添加到智體必須執行的神經網路預測目標動作中。如圖所示,藍色曲線表示在模擬中採用目標動作(其範例的轉向角)發生的理想和瞬時響應時間。然後,引入低通濾波器後,綠色曲線會辨識模擬的智體響應時間。相反,橘色曲線顯示自動駕駛車輛在執行相同轉向動作的行為。然而,可以從圖中註意到,模擬車輛和真實車輛之間的反應時間差異仍然相關。
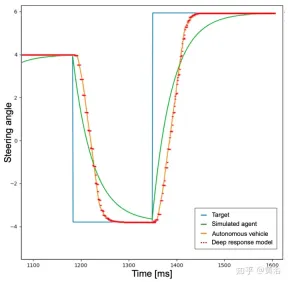
事實上,神經網路預先設定的加速度和轉向角點不是可行的命令,也沒有考慮一些因素,例如係統的慣性、執行器的延遲和其他非理想因素。因此,為了盡可能真實地再現真實車輛的動力學,開發一個由3個全連接層(深度響應)組成的小型神經網路組成的模型。深度響應行為的曲線圖如上圖的紅色虛線所示,可以注意到與代表真實自動駕駛汽車的橘色曲線非常相似。鑑於訓練場景沒有障礙物和交通車輛,所描述的問題對於轉向角的活動更為明顯,但同樣的想法已應用於加速度輸出。
用自動駕駛汽車上收集的資料集訓練深度響應模型,其中輸入對應於人類駕駛員給車輛的命令(加速器壓力和方向盤轉動),輸出對應於車輛的油門、煞車和彎曲,可用GPS、里程計或其他技術測量。透過這種方式,將此類模型嵌入模擬器中,獲得更具可擴展性的系統,從而再現自動駕駛汽車的行為。因此,深度響應模組對於轉向角的校正至關重要,但即使以不太明顯的方式,對於加速度也是必要的,並且隨著障礙物的引入,這一點將清晰可見。
在真實資料上測試了兩種不同的策略,以驗證深度反應模型對系統的影響。隨後,驗證車輛正確地沿著路徑行駛,並遵守高清地圖所得到的速度限制。最後,證明透過模仿學習(Imitation Learning)對神經網路進行預訓練可以顯著縮短總訓練時間。
策略如下:
- 策略1:不使用深度反應模型進行訓練,但使用低通濾波器模擬真實車輛對目標動作的反應。
- 策略2:透過引入深度響應模型進行訓練,確保更現實的動態。
在模擬中執行的測試對這兩種策略都產生了良好的結果。事實上,無論是在訓練過的場景,或是在沒有訓練的地圖區域,智體都能夠在100%的情況下以平穩安全的行為達到目標。
透過在真實場景中測試策略,得到了不同的結果。策略1無法處理車輛動力學,與模擬中的智體相比,其執行預測動作的方式不同;透過這種方式,策略1將觀察到其預測結果的意外狀態,導致自動駕駛汽車上的含噪和不舒服行為。
這種行為也會影響系統的可靠性,事實上,有時需要人工協助以避免自動駕駛汽車駛出道路。
相反,在對自動駕駛汽車進行的所有真實測試中,策略2從未要求人類接管,因為知道車輛動態以及系統將如何演變為預測動作。唯一需要人為介入的情況是避免其他道路使用者;然而,這些情況不被視為失敗,因為策略1和策略2都是在無障礙場景中訓練的。
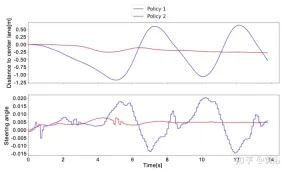
為了更好地理解策略1和策略2之間的差異,如圖是神經網路預測的轉向角以及在真實世界測試的短時窗口內到中心車道的距離。可以注意到這兩種策略行為是完全不同的,策略1(藍色曲線)與策略2(紅色曲線)相比是嘈雜和不安全的,這證明了深度響應模組對於在真正自動駕駛汽車上部署策略至關重要。
為了克服RL的限制,即需要數百萬個片段才能達到最優解,透過模仿學習(IL)進行了預訓練。此外,即使IL的趨勢是訓練大型模型,也使用相同的小型神經網路(約100萬個參數),因為想法是繼續使用RL框架訓練系統,以確保更穩健性和泛化能力。這樣,不會增加硬體資源的使用,考慮到未來可能的多智體訓練,這一點至關重要。
IL訓練階段使用的資料集由模擬智體生成,這些智體遵循基於規則的方法運動。特別是,對於彎曲,用pure pursuit的追蹤演算法,其中智體的目的是沿著特定的航路點移動。相反,用IDM模型來控制智體的縱向加速度。
為了創建資料集,基於規則的智體在四個訓練場景上移動,每100毫秒保存一次標量參數和四個視覺輸入。相反,輸出由pure pursuit演算法和IDM模型給出。
與輸出相對應的兩個橫向和縱向控制項僅表示元組(μacc,μsa)。因此,在IL訓練階段,不估計標準差(σacc,σsa)的值,也不估計值函數(vacc,vsa)。這些特徵以及深度響應模組在IL RL訓練階段學習。
如圖所示,展示從預訓練階段(藍色曲線,IL RL)開始訓練同一神經網絡,並和四種情況下RL(紅色曲線,純RL)結果比較。即使IL RL訓練所需的次數比純RL少,且趨勢也更穩定,但這兩種方法都取得良好的成功率(如圖a)。

此外,圖b中所示的獎勵曲線證明,使用純RL方法獲得的策略(紅色曲線)甚至沒有達到更多訓練時間的可接受解,而IL RL策略在幾個片段內達到最優解(圖b的藍色曲線)。這種情況下,最優解由橘色虛線表示。此基線表示,以在4個場景執行50000片段的模擬智體所獲得的平均獎勵。模擬的智體遵循確定性規則,與收集IL預訓練資料集的規則相同,即用pure pursuit規則做彎曲和IDM規則做縱向加速度。這兩種方法之間的差距可能更明顯,訓練系統執行更複雜的機動,其中可能需要智體互動。
以上是深度強化學習處理真實世界的自動駕駛的詳細內容。更多資訊請關注PHP中文網其他相關文章!

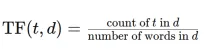 將文本文檔轉換為帶有TFIDFECTORIZER的TF-IDF矩陣Apr 18, 2025 am 10:26 AM
將文本文檔轉換為帶有TFIDFECTORIZER的TF-IDF矩陣Apr 18, 2025 am 10:26 AM本文解釋了術語“頻率分析”頻率(TF-IDF)技術,這是一種自然語言處理(NLP)的關鍵工具(NLP),用於分析文本數據。 TF-IDF通過加權TE超過基本詞袋方法的局限性
 使用Langchain建立智能AI代理:實用指南Apr 18, 2025 am 10:18 AM
使用Langchain建立智能AI代理:實用指南Apr 18, 2025 am 10:18 AM使用蘭班釋放AI特工的力量:初學者指南 想像一下,通過讓她與Chatgpt聊天來向您的祖母展示人工智能的奇觀 - 當AI毫不費力地進行對話時,她的臉上的興奮! Th
 MISTRAL大2:足夠強大,可以挑戰Llama 3.1 405b?Apr 18, 2025 am 10:16 AM
MISTRAL大2:足夠強大,可以挑戰Llama 3.1 405b?Apr 18, 2025 am 10:16 AMMISTRAL大2:深入了解Mistral AI強大的開源LLM Meta AI最近發布的Llama 3.1模型系列很快被Mistral AI揭幕了其迄今為止最大的模型:Mistral flow 2。這個1230億參數
 穩定擴散中的噪聲時間表是什麼? - 分析VidhyaApr 18, 2025 am 10:15 AM
穩定擴散中的噪聲時間表是什麼? - 分析VidhyaApr 18, 2025 am 10:15 AM了解擴散模型中的噪聲時間表:綜合指南 您是否曾經被AI產生的令人驚嘆的數字藝術視覺效果所吸引,並想知道基礎機制? 關鍵要素是“噪聲時間表,&quo
 如何使用GPT-4O構建對話聊天機器人? - 分析VidhyaApr 18, 2025 am 10:06 AM
如何使用GPT-4O構建對話聊天機器人? - 分析VidhyaApr 18, 2025 am 10:06 AM使用GPT-4O構建上下文聊天機器人:綜合指南 在AI和NLP迅速發展的景觀中,聊天機器人已成為開發人員和組織必不可少的工具。 創建真正引人入勝且聰明的聊天的關鍵方面
 2025年建造AI代理的前7個框架Apr 18, 2025 am 10:00 AM
2025年建造AI代理的前7個框架Apr 18, 2025 am 10:00 AM本文探討了建立AI代理的七個領先框架 - 自主軟件實體,這些軟件實體可以感知,決定和採取行動實現目標。 這些代理人超越了傳統的強化學習,利用高級計劃和推理
 I型和II型錯誤有什麼區別? - 分析VidhyaApr 18, 2025 am 09:48 AM
I型和II型錯誤有什麼區別? - 分析VidhyaApr 18, 2025 am 09:48 AM了解統計假設檢驗中的I型和II型錯誤 想像一下一項臨床試驗測試一種新的血壓藥物。 該試驗的結論大大降低了血壓,但實際上並非如此。這是一種類型
 使用Sumy庫的自動文本摘要Apr 18, 2025 am 09:37 AM
使用Sumy庫的自動文本摘要Apr 18, 2025 am 09:37 AMSumy:您的AI驅動摘要助理 厭倦了篩選無盡的文件? 強大的Python庫Sumy提供了一種簡化的解決方案,用於自動文本摘要。 本文探討了Sumy的功能,指導您通過


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

MinGW - Minimalist GNU for Windows
這個專案正在遷移到osdn.net/projects/mingw的過程中,你可以繼續在那裡關注我們。 MinGW:GNU編譯器集合(GCC)的本機Windows移植版本,可自由分發的導入函式庫和用於建置本機Windows應用程式的頭檔;包括對MSVC執行時間的擴展,以支援C99功能。 MinGW的所有軟體都可以在64位元Windows平台上運作。

SublimeText3 英文版
推薦:為Win版本,支援程式碼提示!

SublimeText3漢化版
中文版,非常好用

SAP NetWeaver Server Adapter for Eclipse
將Eclipse與SAP NetWeaver應用伺服器整合。

PhpStorm Mac 版本
最新(2018.2.1 )專業的PHP整合開發工具

