


如今,一些看起來非常像人類的句子實際上是由人工智慧系統產生的,這些系統已經在大量的人類文本中進行了訓練。人們習慣於假定流暢的語言來自於有思想、有感覺的人類,以至於相反的證據可能難以理解,並且認為如果一個人工智慧模型能夠流暢地表達自己,就意味著它也像人類一樣思考和感受。

因此,Google的一名前工程師最近聲稱,Google的人工智慧系統LAMDA有自我意識,因為它可以雄辯地生成關於其所謂感受的文本,這也許並不奇怪。這一事件和隨後的媒體報導導致了一些文章和帖子,懷疑關於人類語言的計算模型是有生命的說法。
由Google的LaMDA等模型產生的文字可能很難與人類寫的文字區分開來。這項令人印象深刻的成就是一項長達數十年的計劃的結果,該計劃旨在建立能夠生成符合語法、有意義的語言的模型。今天的模型,即接近人類語言的資料和規則集,在幾個重要方面與這些早期的嘗試不同。首先,它們基本上是在整個互聯網上訓練的。第二,它們可以學習相距甚遠的字詞之間的關係,而不僅僅是相鄰的字詞。第三,它們透過大量的內部進行調整,甚至連設計它們的工程師都很難理解為什麼它們會產生一個字的序列而不是另一個字的序列。
大型人工智慧語言模型可以進行流暢的對話。然而,它們沒有要傳達的整體訊息,所以它們的短語往往遵循常見的文學套路,這些套路是從被訓練的文本中提取的。人腦有推斷詞語背後意圖的硬性規定。每次你參與對話時,你的大腦都會自動建立一個談話夥伴的心理模型。然後,你利用他們所說的話,用這個人的目標、感覺和信念來填補這個模型。從話語到心理模型的跳躍過程是無縫的,每當你收到一個完整的句子時就會被觸發。這個認知過程在日常生活中為你節省了大量的時間和精力,大大促進了你的社會互動。然而,在人工智慧系統的情況下,它卻失靈了,因為它憑空建立了一個心理模型。

一個可悲的諷刺是,讓人們把人性賦予大型人工智慧語言模型的認知偏見也會導致它們以不人道的方式對待真正的人類。社會文化語言學研究表明,假設流暢的表達和流暢的思維之間的聯繫過於緊密,會導致對不同的人產生偏見。例如,有外國口音的人往往被認為是不太聰明,不太可能得到他們所勝任的工作。對那些不被認為是有聲望的方言,如美國的南方英語,對使用手語的聾啞人,以及對有口吃等語言障礙的人,也存在類似的偏見。這些偏見是非常有害的,往往會導致種族主義和性別歧視的假設,並且被一再證明是毫無根據的。
以上是谷歌用人工智慧凸顯出人類認知的缺陷的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 生成AI應用的代理框架 - 分析VidhyaApr 13, 2025 am 11:13 AM
生成AI應用的代理框架 - 分析VidhyaApr 13, 2025 am 11:13 AM想像一下,擁有一個由AI驅動的助手,不僅可以響應您的查詢,還可以自主收集信息,執行任務甚至處理多種類型的數據(TEXT,圖像和代碼)。聽起來有未來派?在這個a


 您需要查看的3台Openai' s的動手實驗 - 分析VidhyaApr 13, 2025 am 11:06 AM
您需要查看的3台Openai' s的動手實驗 - 分析VidhyaApr 13, 2025 am 11:06 AM介紹 您在講話之前真正思考和理性多久?當前最新的LLM GPT-4O已經在不花很多時間做出回應的情況下提供了令人印象深刻的回應。但是想像一下它是否開始服用
 如何訪問OpenAi O1? - 分析VidhyaApr 13, 2025 am 11:05 AM
如何訪問OpenAi O1? - 分析VidhyaApr 13, 2025 am 11:05 AM介紹 草莓在市場上! ! !我希望這將像其他OpenAI最新車型帶來的人工智能的最新進步一樣富有成果。 我們一直在等待GPT-5這麼長時間
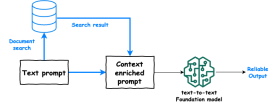 使用llamaindex構建多文件代理抹布Apr 13, 2025 am 11:03 AM
使用llamaindex構建多文件代理抹布Apr 13, 2025 am 11:03 AM介紹 在人工智能快速發展的領域中,處理和理解大量信息的能力變得越來越重要。輸入多文件代理抹布 - 一個功能強大的應用
 免費學習SQL的YouTube頻道 - 分析VidhyaApr 13, 2025 am 10:46 AM
免費學習SQL的YouTube頻道 - 分析VidhyaApr 13, 2025 am 10:46 AM介紹 掌握SQL(結構化查詢語言)對於追求數據管理,數據分析和數據庫管理的個人至關重要。如果您是從新手開始的,或者是經驗豐富的專業人士,請尋求改進,
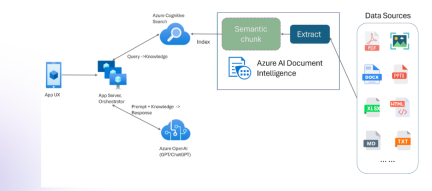 具有多模式和Azure文檔智能的抹布Apr 13, 2025 am 10:38 AM
具有多模式和Azure文檔智能的抹布Apr 13, 2025 am 10:38 AM介紹 在基於數據運行的當前世界中,關係AI圖(RAG)通過關聯數據並繪製關係來對行業產生很大影響。但是,如果一個人可以再進一步多怎麼辦


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

MinGW - Minimalist GNU for Windows
這個專案正在遷移到osdn.net/projects/mingw的過程中,你可以繼續在那裡關注我們。 MinGW:GNU編譯器集合(GCC)的本機Windows移植版本,可自由分發的導入函式庫和用於建置本機Windows應用程式的頭檔;包括對MSVC執行時間的擴展,以支援C99功能。 MinGW的所有軟體都可以在64位元Windows平台上運作。

MantisBT
Mantis是一個易於部署的基於Web的缺陷追蹤工具,用於幫助產品缺陷追蹤。它需要PHP、MySQL和一個Web伺服器。請查看我們的演示和託管服務。

Safe Exam Browser
Safe Exam Browser是一個安全的瀏覽器環境,安全地進行線上考試。該軟體將任何電腦變成一個安全的工作站。它控制對任何實用工具的訪問,並防止學生使用未經授權的資源。

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)

Dreamweaver Mac版
視覺化網頁開發工具

