
知識拓展:自平衡解決資料傾斜的分錶方法

- 藏色散人轉載
- 2023-04-02 06:30:021592瀏覽
這篇文章為大家帶來了關於數據表的相關知識,其中主要給大家分享一種自平衡解決數據傾斜的分錶方法,感興趣的朋友下面一起來看一下吧,希望對大家有幫助。
1、背景
這篇主要描述了B端令牌系統應用資料分錶解決業務資料量增大,且存在的資料傾斜問題,主要面向的場景是一對多資料傾斜問題
1)B令牌的業務背景
先簡述B令牌的業務背景, B令牌系統是用於行銷場景中,將許多使用者綁定在一個令牌上,再將令牌綁定在促銷上,從而實現差異和精準行銷,一般情況下一個令牌的生命週期等同於這個促銷。
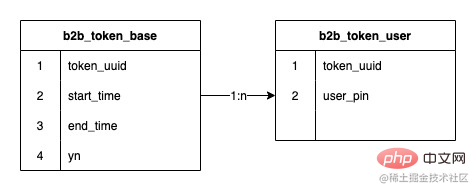
2)B端令牌的結構現況
令牌和令牌使用者關係是一個一對多的關係,早期的令牌系統使用jed分庫,2個分片,中間進行了一次擴容達到了8個分片,儲存的資料行數達到了1.2億
3)資料和業務現況
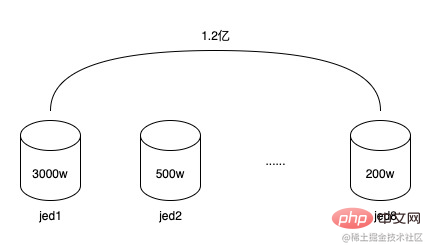
1.2億數據,分佈在8個分庫中,每個分庫平均1500萬,但由於分庫欄位使用的是令牌ID(token_uuid),有得令牌用戶少,只有幾千到一萬,有的令牌用戶多,有100萬到150萬,令牌總數量並不多,只有2萬左右,所以導致資料存在傾斜,有的分庫有3000多萬數據,有的分庫可能只有幾百萬,這已經開始導致資料庫讀寫效能下降。而又因為令牌使用者關係表資料結構很簡單,雖然資料行數很多,但佔用的空間卻不大。 8個分庫總佔用量還不足20G。同時令牌的生命週期基本上和促銷相同,一個令牌服務於一個或幾個促銷後,就會慢慢過期被棄之不用,後續會繼續創建新的令牌。所以這些過期令牌是可以進行歸檔的。
同時由於B端業務的發展,業務訴求也更多,和業務溝通中了解到,未來會上線自動選人系統,由系統自動創建令牌,並選擇適合促銷的人群,未來每個月資料增量在3000萬左右,如果運行一年就會增加3.6億,屆時單表資料量平均會達到6000萬,目前的設計架構已經完全無法滿足業務需求。
同時目前也存在根據令牌ID分頁查詢令牌下使用者的功能,但僅限於給管理端運作使用,使用也不頻繁。
2、解決方案的思考
1) 怎麼解決這個問題
面對日益下降的資料庫讀寫效能,以及業務成長的需求,當下面臨以下幾個問題:
如何解決單表資料行數過多的問題
目前分庫方案存在較嚴重的資料傾斜
如果應對未來資料的成長
2) 技術方案研究與對比
a.資料庫分錶
一般情況來處理第一個問題,通常都是分庫分錶,而當下我們已經是8個分庫,而且8個分庫才佔用了不足20G空間,單庫資源浪費嚴重,所以完全不會考慮繼續增加分庫的方式,所以分錶才是解決方法。
資料分錶通常有兩種方式:垂直分錶和水平分錶。
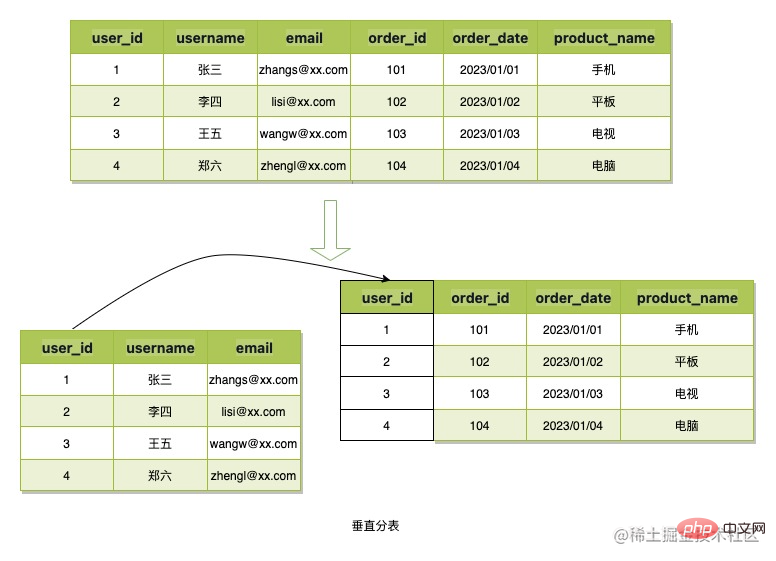
垂直分錶指的是將資料的列進行拆分,然後應用主鍵或其他業務欄位進行關聯,從而降低單表資料佔用空間,或減少冗餘餘存儲,B令牌的場景資料結構簡單,資料佔用空間小,所以不會使用該分錶方式。
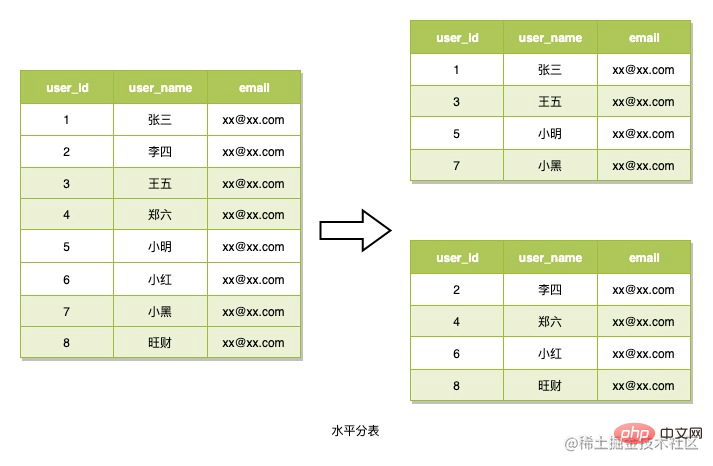
水平分錶指的是將資料的行以一種路由演算法拆分到多張表中,讀取時候也基於這種路由演算法來讀取數據,這種分錶策略一般用來應對資料結構並不複雜,但資料行特別多的場景。這也是我們即將使用的方式。使用這種方式要考慮的就是如何設計路由演算法,這裡也是用這種方式來分錶。
b.路由演算法
資料分錶路由演算法的使用在業界也有多種,一種是利用一致性hash,選擇適當的分錶字段,對字段值hash後值是固定的,使用該值通過取模或按位運算的方式得到一個固定的序號,從而確定數據存儲在哪張表中。
比較常見的應用如分庫大多就是使用一致性hash的方式,透過即時計算分庫欄位的值判斷資料屬於哪個分庫從而決定將資料存入哪個分庫或從哪個分庫讀取資料。而如果查詢時沒有指定分庫欄位則需要同時向所有分庫發出查詢請求,最後在匯總結果。
另外像java程式碼的HashMap資料結構其實也是一種一致性hash演算法的分錶策略,透過對key進行hash後決定將資料存入數組的哪個序號,HashMap裡面用的不是取模的方式取得序號,而是使用位元運算的方式,使用這種方式也決定了HashMap的擴容都是按照2的x次方的大小進行擴容,以後有機會可以介紹這個原理。
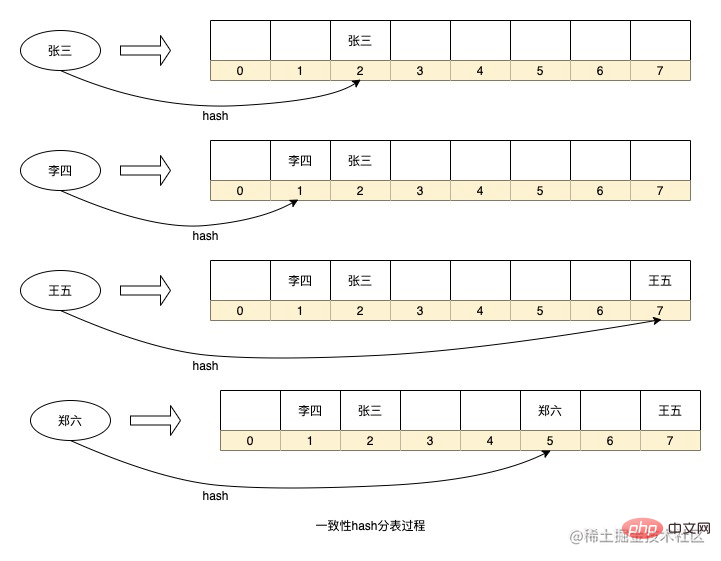
上面就是HashMap中的一個簡化的資料Hash儲存過程,當然我省略了一些細節,例如HashMap中每一個節點都是一個鍊錶(衝突過多還會變成紅黑樹)。應用在我們的場景中就可以將每個序號當成是一張資料表即可。
以上這種路由演算法的優點的路由策略簡單,即時計算也不用增加額外儲存空間,但也存在一個問題就是如果要擴容則需要將歷史資料重新hash一遍進行遷移,例如資料庫分函式庫如果增加分庫則需要將所有資料重新計算分庫,HashMap擴容也會執行rehash重新計算key在陣列的序號。如果資料量太大,這種計算過程耗時將會很長。同時,如果資料表太少,或選擇分片的欄位離散程度低都會導致資料傾斜。
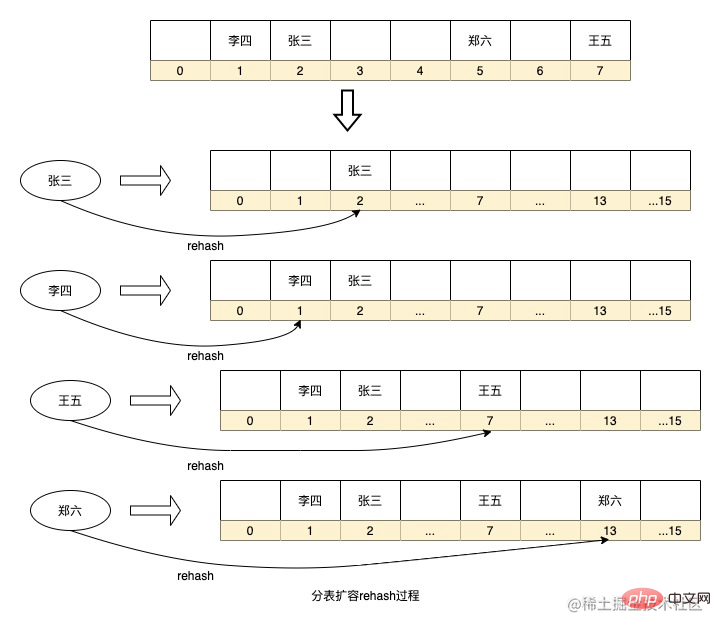
還有一種分錶演算法優化了這種rehash過程,這就是一致性hash環,這種方式是在實體節點之間抽像出很多虛擬節點,然後再利用一致性hash演算法將資料打在這些虛擬節點上,而每個實體節點其實是負責的該實體節點逆時針方向上和另一個實體節點相鄰的虛擬節點的資料。這種方式的好處是假如需要擴容增加節點,增加的節點放在環上任意位置,也只會影響到該節點順時針方向上相鄰節點的數據,只需要將該節點中的部分數據遷移到這個新節點上即可,大大降低rehash的過程。同時由於虛擬節點多,也可以增加讓資料更均勻的分佈在這個環上,只要將實體節點放置在適當的位置,就能最大程度保證的解決資料傾斜問題。
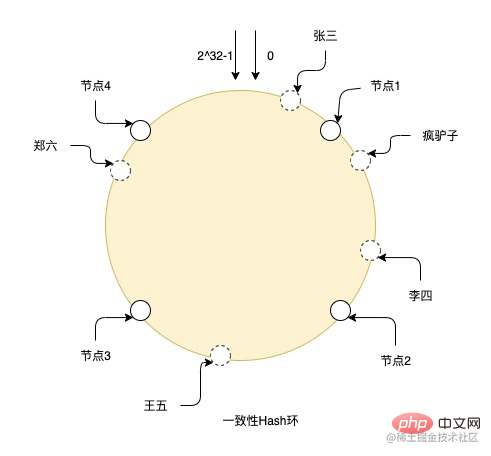
比如圖上就是一個一致性Hash環的hash過程,在整個環上有從0到2^32-1個節點,其中實線的就是真實節點,其他都是虛擬節點,張三通過hash後落到環上的虛擬節點,然後從虛擬節點的位置順時針尋找真實節點,最終數據就存儲在真實節點上,所以瘋驢子和李四就存儲在節點2上,王五在節點3上,鄭六在節點4上。
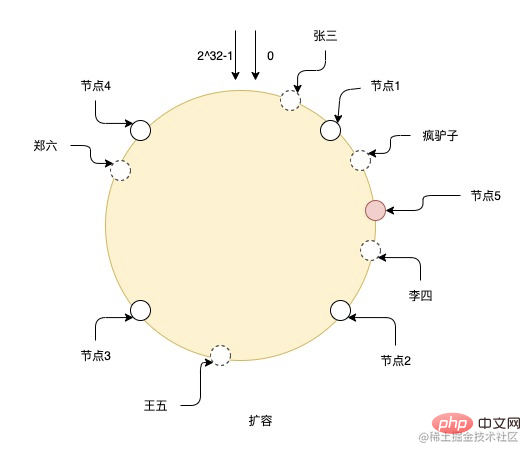
擴充了一個節點5號後,則需要將節點1和節點5之間的資料遷移到節點5上,其他節點資料則不用變更。但如圖上看到的,只加這一個節點,也容易導致每個節點負責的資料不均勻,例如節點2和節點5,相較於其他節點負責的資料就少了很多,所以擴容時最好是成倍擴容,這樣數據可以繼續保持均勻。
3) 思考我的方案
再回到B令牌的業務場景上來,需要能達成以下訴求
首先必須使用水平分錶來解決單表資料量過大的問題
需要能支援根據令牌分頁查詢使用者
由於目前業務資料增量在3000萬,但不排除未來業務持續成長的可能,分錶數量需要能支援未來擴展
資料行數過高,未來在擴展時必須保證無需資料遷移或資料遷移成本低
#需要解決資料傾斜問題,確保不因為單表資料量過大而導致整體效能降低
#基於以上訴求,首先看問題b,如果要支持根據令牌分頁查詢用戶,就需要保證令牌下的所有用戶都在同一張表上,才能簡單的支持分頁查詢,否則用一些匯總歸併演算法則複雜程度過高了,而且表格太多也會降低查詢效能。雖然也可以透過將資料異質es提供查詢功能,但僅僅是為了少量管理端的查詢訴求再進行資料異質,成本有些高收益並不明顯,也有些浪費資源。所以分錶欄位只能確定使用令牌ID。
而上面也提到令牌ID數量不多,而且令牌下的使用者也從1萬到100萬不等,單純使用一致性hash的方式用令牌ID作為分錶策略則會導致資料傾斜嚴重,未來擴容時資料遷移成本也很高。
但使用一致性hash環又會導致未來在擴容時最好是按2的倍數擴容,不然就會存在有的節點負責的虛擬節點多,有的節點負責虛擬節點少,導致數據不均勻。然而在和資料庫同事溝通,一個資料庫下的資料表數量不宜太多,否則會對資料庫帶來較大壓力,而一致性hash環這種方式可能擴兩三次容就會導致分錶數達到一個很高的數值。
基於上述問題,在確定使用令牌id作為分錶的前提下,就需要著重思考如何支援動態擴容和解決資料傾斜的問題。
3、方案落地
1) 方案概述
a.如何支援動態擴容
分錶的欄位已經確定使用令牌ID,而前面也提到我們的資料結構是令牌和使用者是一對多的關係數據,那麼在建立令牌時hash出的分錶序號儲存下來,後續基於儲存的分錶序號進行路由,就可以確保未來擴容時也不會影響存量資料的路由,無需進行資料遷移。
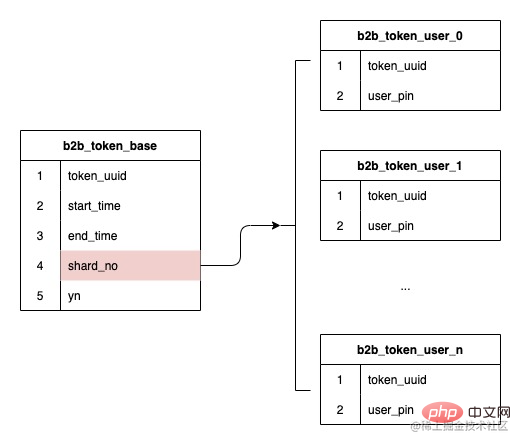
b.如何解決資料傾斜
#由於選用了令牌ID作為分錶字段,而各令牌資料量大小不一,資料傾斜就會是一個大問題。所以這裡就想辦法引入了一個分錶水位的概念。

在使用者要求儲存或刪除關係使用者數的時候,基於分錶序號對目前分錶數量進行一個增減的計數,當某個分錶中的當資料量處於高水位時,就將該分錶從分錶演算法中剔除,從而讓該分錶不會繼續產生新的資料。
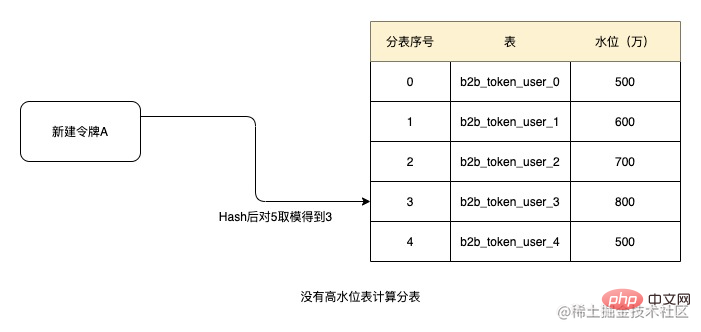
例如當設定閾值1000萬為高水位,由於以上5張表都沒有達到高水位,則創建令牌時根據令牌ID進行Hash後取模得到3,依序取得表,則目前令牌的分錶號為b2b_token_user_3。後續關係數據都從該表中取得。
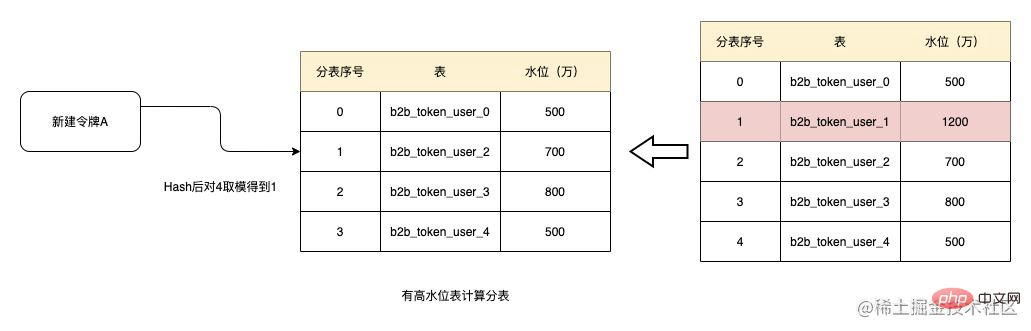
運行一段時間後,表b2b_token_user_1資料量已經成長到了1200萬,超過了1000萬的水位,這時候在創建令牌則將該表移除,在此進行Hash後取模得到1,則目前分到的表就是b2b_token_user_2。而如果b2b_token_user_1的水位如果一直無法降下來,則該表後續都不會再參與分錶,表中的資料量也不會再增加。
當然有一種可能就是所有表都進入了高水位,為了兜底,這時水位功能就失效,所有表都加入到分錶中來。
c.定期資料歸檔,降低分錶水位
如果表中的資料量只會不斷增加,而不會減少的話,那麼早晚所有的表都會達到高水位,這就無法達到動態的效果。上述背景有提到,令牌創建後是為某一批促銷服務,促銷終止後,令牌也會失去作用,同時令牌上也有有效期限,超過有效期限的令牌也會失去作用。所以定期對資料進行歸檔就可以讓那些處於高水位的表把水位慢慢降下來,重新加入到分錶中。
而且目前令牌已經存在了一張b2b_token_user的表,裡面的資料已經有1.2億,可以將該表作為圖上的0號表,這樣在第一次上線時只要將歷史令牌都的分錶序號都記為0即可,存量資料就不需要再進行遷移,而該表資料量水位高,也不會參與分錶。再搭配定期的資料歸檔,該表的水位也會慢慢將下來。
d.監控機制
雖然可以透過定期進行資料歸檔,可以讓表的水位降下來,但隨著業務發展,可能會存在大多數表都進入了高水位,而且都是有效數據的情況。這時候系統就會像HashMap判斷容量達到75%就自動擴容一樣,我們不能夠自動創建表,但當75%的表都進入高水位可以告警出來,開發人員監聽到告警人工介入,觀察是需要調高水位,還是進行表的擴容。
3) 不足
• 水位門檻與擴容監控
目前水位的閾值還是依靠人工手動設置,應該設置多大還是比較感性的,只能設置一個,在告警以後適當調整。不過其實可以在系統中自動監控介面讀寫效能的波動,發現大多數表達到高水位時,介面讀寫效能都沒有明顯變化,可以係統自動調高閾值,進而形成智慧閾值。
而介面效能讀寫出現明顯變化時發現大多數表都達到了閾值,則可以警告提示應考慮擴容。
4、總結
解決問題從來沒有銀彈,我們需要利用手中的技術手段和工具,進行組合、適配,使其適合我們當下的業務和場景,沒有好或不好,只有適不適合。
以上是知識拓展:自平衡解決資料傾斜的分錶方法的詳細內容。更多資訊請關注PHP中文網其他相關文章!