



怎麼利用Node進行圖片壓縮?以下這篇文章以PNG圖片為例跟大家介紹一下進行圖片壓縮的方法,希望對大家有幫助!

最近要搞圖片處理服務,其中一個就是要實作圖片壓縮功能。以前前端開發的時候只要利用canvas現成的API處理下就能實現,後端可能也有現成的API但我並不知道。仔細想想,我從來沒有詳細了解圖片壓縮原理,那剛好趁這次去研究學習下,所以有了這篇文章來記錄。老樣子,如有不對的地方,DDDD(帶弟弟)。
我們先把圖片上傳到後端,看看後端接收了什麼樣的參數。這裡後端我用的是Node.js(Nest),圖片我以PNG圖為例。
介面與參數列印如下:
@Post('/compression')<br/>@UseInterceptors(FileInterceptor('file'))<br/>async imageCompression(@UploadedFile() file: Express.Multer.File) {<br/> <br/> return {<br/> file<br/> }<br/>}<br/>
要進行壓縮,我們就需要拿到影像資料。可以看到,唯一能藏匿圖像資料的就是這串buffer。那這串buffer描述了什麼,就需要先弄清楚什麼是PNG。 【相關教學推薦:nodejs影片教學、程式設計教學】
#PNG
##這裡是PNG的WIKI地址。
閱讀之後,我了解到PNG是由一個8 byte的檔案頭加上多個的區塊(chunk)組成。示意圖如下:
關鍵塊(Critical chunks),一種叫輔助塊(Ancillary chunks)。關鍵塊是必不可少的,沒有關鍵塊,解碼器將無法正確識別並展示圖片。輔助塊是可選的,部分軟體在處理圖片之後就有可能攜帶輔助塊。每個區塊都是四個部分組成:4 byte 描述這個區塊的內容有多長,4 byte 描述這個區塊的類型是什麼,n byte 描述區塊的內容(n 就是前面4 byte 值的大小,也就是說,一個區塊最大長度為28*4),4 byte CRC校驗檢查區塊的數據,標記著一個區塊的結束。其中,區塊類型的4 byte 的值為4個acsii碼,第一個字母大寫表示是關鍵區塊,小寫表示是輔助區塊;第二個字母大寫表示是公有,小寫表示是私有;第三個字母必須是大寫,用於PNG後續的擴展;第四個字母表示該區塊不識別時,能否安全複製,大寫表示未修改關鍵區塊時才能安全複製,小寫表示都能安全複製。 PNG官方提供許多定義的區塊類型,這裡只需要知道關鍵區塊的類型即可,分別是IHDR,PLTE,IDAT,IEND。
IHDR
PNG要求第一個區塊必須是IHDR。 IHDR的區塊內容是固定的13 byte,包含了圖片的以下資訊:
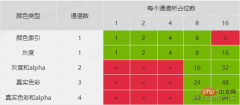
寬度width (4 byte) & 高度height (4 byte)位元深bit depth (1 byte,值為1,2,4,8或16) & 顏色類型color type (1 byte,值為0,2,3,4或6)壓縮方法compression method (1 byte,值為0 ) & 過濾方式filter method (1 byte,值為0)交錯方式interlace method (1 byte,值為0或1)寬度和高度很容易理解,剩下的幾個好像都很陌生,接下來我將進行說明。 在說明位深之前,我們先來看顏色類型,顏色類型有5種值:- 0 表示灰階(grayscale)它只有一個通道( channel),看成rgb的話,可以理解它的三色通道值是相等的,所以不需要多餘兩個通道表示。
- 2 表示真實色彩(rgb)它有三個通道,分別是R(紅色),G(綠色),B(藍色)。
3 表示顏色索引(indexed)它也只有一個通道,表示顏色的索引值。此類型往往配備一組顏色列表,具體的顏色是根據索引值和顏色列表查詢得到的。
4 表示灰階和alpha 它有兩個通道,除了灰階的通道外,多了一個alpha通道,可以控制透明度。
6 表示真實色彩和alpha 它有四個通道。
之所以要說到通道,是因為它和這裡的位深有關。位深的值就定義了每個通道所佔的位數(bit)。位元深跟顏色類型組合,就能知道圖片的顏色格式類型和每個像素所佔的記憶體大小。 PNG官方支援的組合如下表:
過濾和壓縮是因為PNG中儲存的不是圖像的原始數據,而是處理後的數據,這也是為什麼PNG圖片所佔記憶體較小的原因。 PNG使用了兩步驟進行了圖片資料的壓縮轉換。
第一步,過濾。過濾的目的是為了讓原始圖片資料經過此規則後,能進行更大的壓縮比。舉個例子,如果有一張漸變圖片,從左往右,顏色依次為[#000000, #000001, #000002, ..., #ffffff],那麼我們就可以約定一條規則,右邊的像素總是和它前一個左邊的像素進行比較,那麼處理完的資料就變成了[1, 1, 1, ..., 1],這樣是不是就能進行更好的壓縮。 PNG目前只有一種濾波方式,就是基於鄰近像素作為預測值,用目前像素減去預測值。過濾的類型一共有五種,(目前我還不知道這個類型值在哪裡存儲,有可能在IDAT裡,找到了再來刪除這條括號裡的已確定該類型值儲存在IDAT資料中)如下表所示:
| Type byte | #Filter name | Predicted value |
|---|---|---|
| 0 | None | |
| #1 | Sub | |
| 2 | Up |
第二步,压缩。PNG也只有一种压缩算法,使用的是DEFLATE算法。这里不细说,具体看下面的章节。
交错方式,有两种值。0表示不处理,1表示使用Adam7 算法进行处理。我没有去详细了解该算法,简单来说,当值为0时,图片需要所有数据都加载完毕时,图片才会显示。而值为1时,Adam7会把图片划分多个区域,每个区域逐级加载,显示效果会有所优化,但通常会降低压缩效率。加载过程可以看下面这张gif图。

PLTE
PLTE的块内容为一组颜色列表,当颜色类型为颜色索引时需要配置。值得注意的是,颜色列表中的颜色一定是每个通道8bit,每个像素24bit的真实色彩列表。列表的长度,可以比位深约定的少,但不能多。比如位深是2,那么22,最多4种颜色,列表长度可以为3,但不能为5。
IDAT
IDAT的块内容是图片原始数据经过PNG压缩转换后的数据,它可能有多个重复的块,但必须是连续的,并且只有当上一个块填充满时,才会有下一个块。
IEND
IEND的块内容为0 byte,它表示图片的结束。
阅读到这里,我们把上面的接口改造一下,解析这串buffer。
@Post('/compression')<br/>@UseInterceptors(FileInterceptor('file'))<br/>async imageCompression(@UploadedFile() file: Express.Multer.File) {<br/> const buffer = file.buffer;<br/><br/> const result = {<br/> header: buffer.subarray(0, 8).toString('hex'),<br/> chunks: [],<br/> size: file.size,<br/> };<br/><br/> let pointer = 8;<br/> while (pointer < buffer.length) {<br/> let chunk = {};<br/> const length = parseInt(buffer.subarray(pointer, pointer + 4).toString('hex'), 16);<br/> const chunkType = buffer.subarray(pointer + 4, pointer + 8).toString('ascii');<br/> const crc = buffer.subarray(pointer + length, pointer + length + 4).toString('hex');<br/> chunk = {<br/> ...chunk,<br/> length,<br/> chunkType,<br/> crc,<br/> };<br/><br/> switch (chunkType) {<br/> case 'IHDR':<br/> const width = parseInt(buffer.subarray(pointer + 8, pointer + 12).toString('hex'), 16);<br/> const height = parseInt(buffer.subarray(pointer + 12, pointer + 16).toString('hex'), 16);<br/> const bitDepth = parseInt(<br/> buffer.subarray(pointer + 16, pointer + 17).toString('hex'),<br/> 16,<br/> );<br/> const colorType = parseInt(<br/> buffer.subarray(pointer + 17, pointer + 18).toString('hex'),<br/> 16,<br/> );<br/> const compressionMethod = parseInt(<br/> buffer.subarray(pointer + 18, pointer + 19).toString('hex'),<br/> 16,<br/> );<br/> const filterMethod = parseInt(<br/> buffer.subarray(pointer + 19, pointer + 20).toString('hex'),<br/> 16,<br/> );<br/> const interlaceMethod = parseInt(<br/> buffer.subarray(pointer + 20, pointer + 21).toString('hex'),<br/> 16,<br/> );<br/><br/> chunk = {<br/> ...chunk,<br/> width,<br/> height,<br/> bitDepth,<br/> colorType,<br/> compressionMethod,<br/> filterMethod,<br/> interlaceMethod,<br/> };<br/> break;<br/> case 'PLTE':<br/> const colorList = [];<br/> const colorListStr = buffer.subarray(pointer + 8, pointer + 8 + length).toString('hex');<br/> for (let i = 0; i < colorListStr.length; i += 6) {<br/> colorList.push(colorListStr.slice(i, i + 6));<br/> }<br/> chunk = {<br/> ...chunk,<br/> colorList,<br/> };<br/> break;<br/> default:<br/> break;<br/> }<br/> result.chunks.push(chunk);<br/> pointer = pointer + 4 + 4 + length + 4;<br/> }<br/><br/> return result;<br/>}<br/>
这里我测试用的图没有PLTE,刚好我去TinyPNG压缩我那张测试图之后进行上传,发现有PLTE块,可以看一下,结果如下图。

通过比对这两张图,压缩图片的方式我们也能窥探一二。
PNG的压缩
前面说过,PNG使用的是一种叫DEFLATE的无损压缩算法,它是Huffman Coding跟LZ77的结合。除了PNG,我们经常使用的压缩文件,.zip,.gzip也是使用的这种算法(7zip算法有更高的压缩比,也可以了解下)。要了解DEFLATE,我们首先要了解Huffman Coding和LZ77。
Huffman Coding
哈夫曼编码忘记在大学的哪门课接触过了,它是一种根据字符出现频率,用最少的字符替换出现频率最高的字符,最终降低平均字符长度的算法。
举个例子,有字符串"ABCBCABABADA",如果按照正常空间存储,所占内存大小为12 * 8bit = 96bit,现对它进行哈夫曼编码。
1.统计每个字符出现的频率,得到A 5次 B 4次 C 2次 D 1次
2.对字符按照频率从小到大排序,将得到一个队列D1,C2,B4,A5
3.按顺序构造哈夫曼树,先构造一个空节点,最小频率的字符分给该节点的左侧,倒数第二频率的字符分给右侧,然后将频率相加的值赋值给该节点。接着用赋值后节点的值和倒数第三频率的字符进行比较,较小的值总是分配在左侧,较大的值总是分配在右侧,依次类推,直到队列结束,最后把最大频率和前面的所有值相加赋值给根节点,得到一棵完整的哈夫曼树。
4.对每条路径进行赋值,左侧路径赋值为0,右侧路径赋值为1。从根节点到叶子节点,进行遍历,遍历的结果就是该字符编码后的二进制表示,得到:A(0)B(11)C(101)D(100)。
完整的哈夫曼树如下(忽略箭头,没找到连线- -!):

压缩后的字符串,所占内存大小为5 * 1bit + 4 * 2bit + 2 * 3bit + 1 * 3bit = 22bit。当然在实际传输过程中,还需要把编码表的信息(原始字符和出现频率)带上。因此最终占比大小为 4 * 8bit + 4 * 3bit(频率最大值为5,3bit可以表示)+ 22bit = 66bit(理想状态),小于原有的96bit。
LZ77
LZ77算法还是第一次知道,查了一下是一种基于字典和滑动窗的无所压缩算法。(题外话:因为Lempel和Ziv在1977年提出的算法,所以叫LZ77,哈哈哈?)
我们还是以上面这个字符串"ABCBCABABADA"为例,现假设有一个4 byte的动态窗口和一个2byte的预读缓冲区,然后对它进行LZ77算法压缩,过程顺序从上往下,示意图如下:

总结下来,就是预读缓冲区在动态窗口中找到最长相同项,然后用长度较短的标记来替代这个相同项,从而实现压缩。从上图也可以看出,压缩比跟动态窗口的大小,预读缓冲区的大小和被压缩数据的重复度有关。
DEFLATE
DEFLATE【RFC 1951】是先使用LZ77编码,对编码后的结果在进行哈夫曼编码。我们这里不去讨论具体的实现方法,直接使用其推荐库Zlib,刚好Node.js内置了对Zlib的支持。接下来我们继续改造上面那个接口,如下:
import * as zlib from 'zlib';<br/><br/>@Post('/compression')<br/>@UseInterceptors(FileInterceptor('file'))<br/>async imageCompression(@UploadedFile() file: Express.Multer.File) {<br/> const buffer = file.buffer;<br/><br/> const result = {<br/> header: buffer.subarray(0, 8).toString('hex'),<br/> chunks: [],<br/> size: file.size,<br/> };<br/><br/> // 因为可能有多个IDAT的块 需要个数组缓存最后拼接起来<br/> const fileChunkDatas = [];<br/> let pointer = 8;<br/> while (pointer < buffer.length) {<br/> let chunk = {};<br/> const length = parseInt(buffer.subarray(pointer, pointer + 4).toString('hex'), 16);<br/> const chunkType = buffer.subarray(pointer + 4, pointer + 8).toString('ascii');<br/> const crc = buffer.subarray(pointer + length, pointer + length + 4).toString('hex');<br/> chunk = {<br/> ...chunk,<br/> length,<br/> chunkType,<br/> crc,<br/> };<br/><br/> switch (chunkType) {<br/> case 'IHDR':<br/> const width = parseInt(buffer.subarray(pointer + 8, pointer + 12).toString('hex'), 16);<br/> const height = parseInt(buffer.subarray(pointer + 12, pointer + 16).toString('hex'), 16);<br/> const bitDepth = parseInt(<br/> buffer.subarray(pointer + 16, pointer + 17).toString('hex'),<br/> 16,<br/> );<br/> const colorType = parseInt(<br/> buffer.subarray(pointer + 17, pointer + 18).toString('hex'),<br/> 16,<br/> );<br/> const compressionMethod = parseInt(<br/> buffer.subarray(pointer + 18, pointer + 19).toString('hex'),<br/> 16,<br/> );<br/> const filterMethod = parseInt(<br/> buffer.subarray(pointer + 19, pointer + 20).toString('hex'),<br/> 16,<br/> );<br/> const interlaceMethod = parseInt(<br/> buffer.subarray(pointer + 20, pointer + 21).toString('hex'),<br/> 16,<br/> );<br/><br/> chunk = {<br/> ...chunk,<br/> width,<br/> height,<br/> bitDepth,<br/> colorType,<br/> compressionMethod,<br/> filterMethod,<br/> interlaceMethod,<br/> };<br/> break;<br/> case 'PLTE':<br/> const colorList = [];<br/> const colorListStr = buffer.subarray(pointer + 8, pointer + 8 + length).toString('hex');<br/> for (let i = 0; i < colorListStr.length; i += 6) {<br/> colorList.push(colorListStr.slice(i, i + 6));<br/> }<br/> chunk = {<br/> ...chunk,<br/> colorList,<br/> };<br/> break;<br/> case 'IDAT':<br/> fileChunkDatas.push(buffer.subarray(pointer + 8, pointer + 8 + length));<br/> break;<br/> default:<br/> break;<br/> }<br/> result.chunks.push(chunk);<br/> pointer = pointer + 4 + 4 + length + 4;<br/> }<br/><br/> const originFileData = zlib.unzipSync(Buffer.concat(fileChunkDatas));<br/><br/> // 这里原图片数据太长了 我就只打印了长度<br/> return {<br/> ...result,<br/> originFileData: originFileData.length,<br/> };<br/>}<br/>
最终打印的结果,我们需要注意红框的那几个部分。可以看到上图,位深和颜色类型决定了每个像素由4 byte组成,然后由于过滤方式的存在,会在每行的第一个字节进行标记。因此该图的原始数据所占大小为:707 * 475 * 4 byte + 475 * 1 byte = 1343775 byte。正好是我们打印的结果。
我们也可以试试之前TinyPNG压缩后的图,如下:

可以看到位深为8,索引颜色类型的图每像素占1 byte。计算得到:707 * 475 * 1 byte + 475 * 1 byte = 336300 byte。结果也正确。
总结
现在再看如何进行图片压缩,你可能很容易得到下面几个结论:
1.减少不必要的辅助块信息,因为辅助块对PNG图片而言并不是必须的。
2.减少IDAT的块数,因为每多一个IDAT的块,就多余了12 byte。
3.降低每个像素所占的内存大小,比如当前是4通道8位深的图片,可以统计整个图片色域,得到色阶表,设置索引颜色类型,降低通道从而降低每个像素的内存大小。
4.等等....
至于JPEG,WEBP等等格式图片,有机会再看。溜了溜了~(还是使用现成的库处理压缩吧)。
好久没写文章,写完才发现语雀不能免费共享,发在这里吧。
更多node相关知识,请访问:nodejs 教程!
以上是怎麼利用Node進行圖片壓縮的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 Python vs. JavaScript:開發環境和工具Apr 26, 2025 am 12:09 AM
Python vs. JavaScript:開發環境和工具Apr 26, 2025 am 12:09 AMPython和JavaScript在開發環境上的選擇都很重要。 1)Python的開發環境包括PyCharm、JupyterNotebook和Anaconda,適合數據科學和快速原型開發。 2)JavaScript的開發環境包括Node.js、VSCode和Webpack,適用於前端和後端開發。根據項目需求選擇合適的工具可以提高開發效率和項目成功率。
 JavaScript是用C編寫的嗎?檢查證據Apr 25, 2025 am 12:15 AM
JavaScript是用C編寫的嗎?檢查證據Apr 25, 2025 am 12:15 AM是的,JavaScript的引擎核心是用C語言編寫的。 1)C語言提供了高效性能和底層控制,適合JavaScript引擎的開發。 2)以V8引擎為例,其核心用C 編寫,結合了C的效率和麵向對象特性。 3)JavaScript引擎的工作原理包括解析、編譯和執行,C語言在這些過程中發揮關鍵作用。
 JavaScript的角色:使網絡交互和動態Apr 24, 2025 am 12:12 AM
JavaScript的角色:使網絡交互和動態Apr 24, 2025 am 12:12 AMJavaScript是現代網站的核心,因為它增強了網頁的交互性和動態性。 1)它允許在不刷新頁面的情況下改變內容,2)通過DOMAPI操作網頁,3)支持複雜的交互效果如動畫和拖放,4)優化性能和最佳實踐提高用戶體驗。
 C和JavaScript:連接解釋Apr 23, 2025 am 12:07 AM
C和JavaScript:連接解釋Apr 23, 2025 am 12:07 AMC 和JavaScript通過WebAssembly實現互操作性。 1)C 代碼編譯成WebAssembly模塊,引入到JavaScript環境中,增強計算能力。 2)在遊戲開發中,C 處理物理引擎和圖形渲染,JavaScript負責遊戲邏輯和用戶界面。
 從網站到應用程序:JavaScript的不同應用Apr 22, 2025 am 12:02 AM
從網站到應用程序:JavaScript的不同應用Apr 22, 2025 am 12:02 AMJavaScript在網站、移動應用、桌面應用和服務器端編程中均有廣泛應用。 1)在網站開發中,JavaScript與HTML、CSS一起操作DOM,實現動態效果,並支持如jQuery、React等框架。 2)通過ReactNative和Ionic,JavaScript用於開發跨平台移動應用。 3)Electron框架使JavaScript能構建桌面應用。 4)Node.js讓JavaScript在服務器端運行,支持高並發請求。
 Python vs. JavaScript:比較用例和應用程序Apr 21, 2025 am 12:01 AM
Python vs. JavaScript:比較用例和應用程序Apr 21, 2025 am 12:01 AMPython更適合數據科學和自動化,JavaScript更適合前端和全棧開發。 1.Python在數據科學和機器學習中表現出色,使用NumPy、Pandas等庫進行數據處理和建模。 2.Python在自動化和腳本編寫方面簡潔高效。 3.JavaScript在前端開發中不可或缺,用於構建動態網頁和單頁面應用。 4.JavaScript通過Node.js在後端開發中發揮作用,支持全棧開發。
 C/C在JavaScript口譯員和編譯器中的作用Apr 20, 2025 am 12:01 AM
C/C在JavaScript口譯員和編譯器中的作用Apr 20, 2025 am 12:01 AMC和C 在JavaScript引擎中扮演了至关重要的角色,主要用于实现解释器和JIT编译器。1)C 用于解析JavaScript源码并生成抽象语法树。2)C 负责生成和执行字节码。3)C 实现JIT编译器,在运行时优化和编译热点代码,显著提高JavaScript的执行效率。
 JavaScript在行動中:現實世界中的示例和項目Apr 19, 2025 am 12:13 AM
JavaScript在行動中:現實世界中的示例和項目Apr 19, 2025 am 12:13 AMJavaScript在現實世界中的應用包括前端和後端開發。 1)通過構建TODO列表應用展示前端應用,涉及DOM操作和事件處理。 2)通過Node.js和Express構建RESTfulAPI展示後端應用。


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

VSCode Windows 64位元 下載
微軟推出的免費、功能強大的一款IDE編輯器

Atom編輯器mac版下載
最受歡迎的的開源編輯器

ZendStudio 13.5.1 Mac
強大的PHP整合開發環境

MinGW - Minimalist GNU for Windows
這個專案正在遷移到osdn.net/projects/mingw的過程中,你可以繼續在那裡關注我們。 MinGW:GNU編譯器集合(GCC)的本機Windows移植版本,可自由分發的導入函式庫和用於建置本機Windows應用程式的頭檔;包括對MSVC執行時間的擴展,以支援C99功能。 MinGW的所有軟體都可以在64位元Windows平台上運作。

DVWA
Damn Vulnerable Web App (DVWA) 是一個PHP/MySQL的Web應用程序,非常容易受到攻擊。它的主要目標是成為安全專業人員在合法環境中測試自己的技能和工具的輔助工具,幫助Web開發人員更好地理解保護網路應用程式的過程,並幫助教師/學生在課堂環境中教授/學習Web應用程式安全性。 DVWA的目標是透過簡單直接的介面練習一些最常見的Web漏洞,難度各不相同。請注意,該軟體中

