
詳解怎麼使用Golang爬取必應壁紙

- 青灯夜游轉載
- 2023-02-20 19:38:283127瀏覽

做爬蟲不用說,就是用python就好,一個requests包走天下。但是呢,聽說golang內建的http包非常牛逼,咱就是說不得整點活,也剛好學習學習新東西,複習下http協議的請求和回應相關的知識點。話不多說,咱直接開整
這篇文章爬下必應壁紙先小試牛刀。狗頭保命狗頭保命狗頭保命
#爬蟲流程概述
graph TD 请求数据 --> 解析数据 --> 数据入库
上圖的流程圖大家可以看到,其實爬蟲並不麻煩,整個流程就只有三步而已。接下來具體聊聊每一步需要做什麼
請求資料:在這裡我們需要使用golang中的內建套件http套件向目標位址發起請求,這一步就完成了
解析資料:這裡我們需要對請求到的資料進行解析,因為不是整個請求到的資料我們都需要,我們只需要某些具體的關鍵的資料而已。這一步也叫資料清洗
資料入庫:不難理解,這就是將解析好的資料進行入庫操作
實戰分析
先到必應壁紙官網上觀察,做爬蟲的話是需要對資料特別敏感的。這是首頁訊息,整個頁面是非常簡潔的
接下來,需要調出瀏覽器的開發者工具(這個大家應該都非常熟悉吧,不熟悉的話很難跟下去的喔)。直接按下F12或右鍵點擊檢查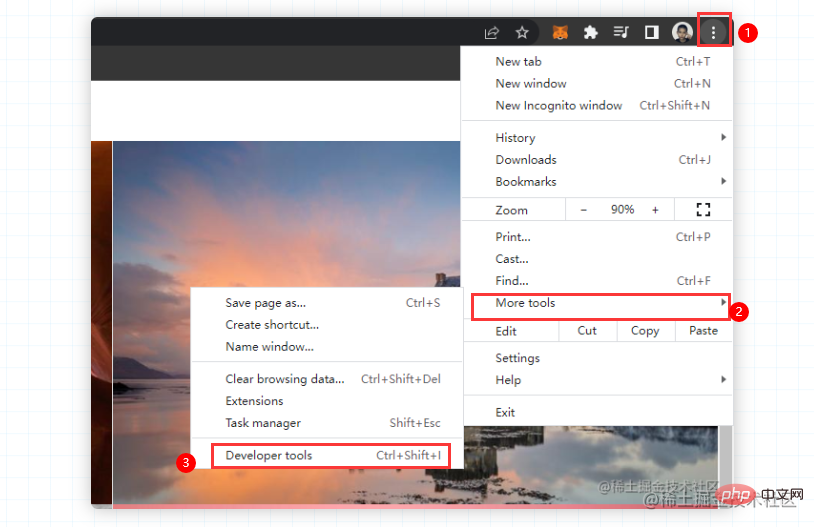
 但是呢?在必應桌布上,右鍵不能呼叫控制台,只能手動調出了。大家不用擔心,照第一張圖操作就好。如果有同學的chrome是中文的,也是一樣的操作,選擇更多工具,選擇開發者工具即可
但是呢?在必應桌布上,右鍵不能呼叫控制台,只能手動調出了。大家不用擔心,照第一張圖操作就好。如果有同學的chrome是中文的,也是一樣的操作,選擇更多工具,選擇開發者工具即可
不出意外呢,大家一定看到的是這樣的頁面
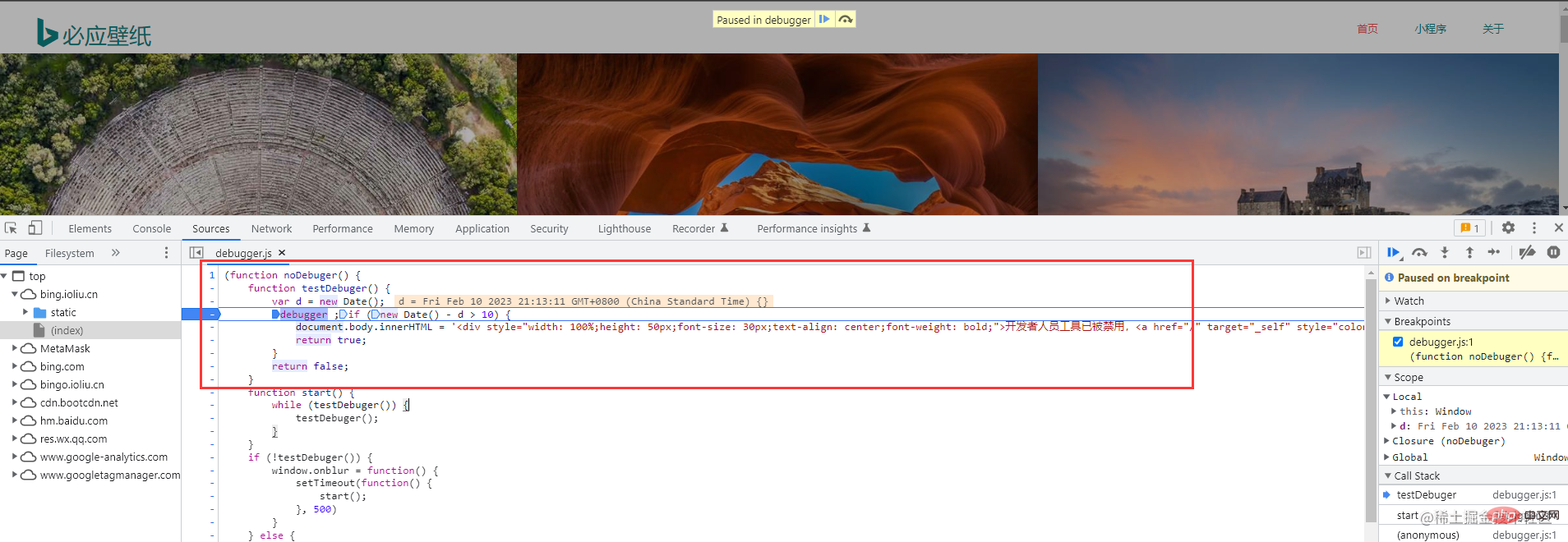 這個沒關係的,只是必應壁紙網站的一些反爬錯誤而已。 (我很久之前爬的時候還沒有這個反爬錯誤)這個是不影響我們操作的
這個沒關係的,只是必應壁紙網站的一些反爬錯誤而已。 (我很久之前爬的時候還沒有這個反爬錯誤)這個是不影響我們操作的
接下來選擇這個工具,幫助我們快速定位到我們想要的元素上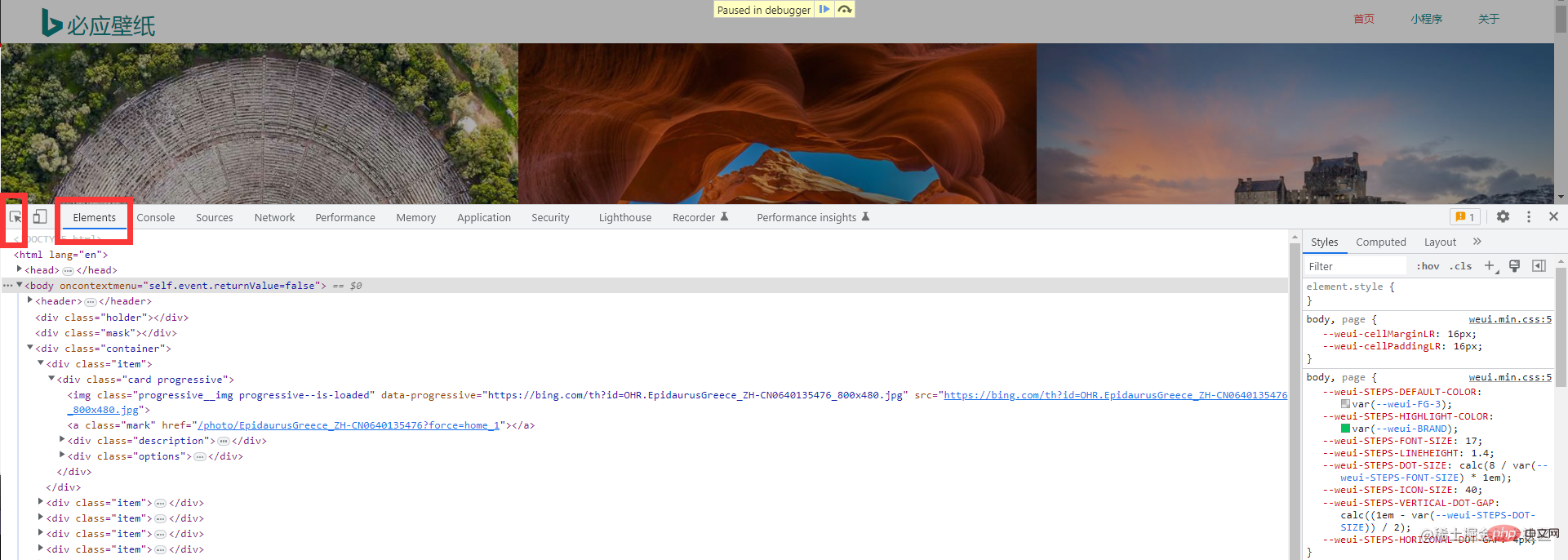 然後我們就能找到我們所需的圖片資訊
然後我們就能找到我們所需的圖片資訊
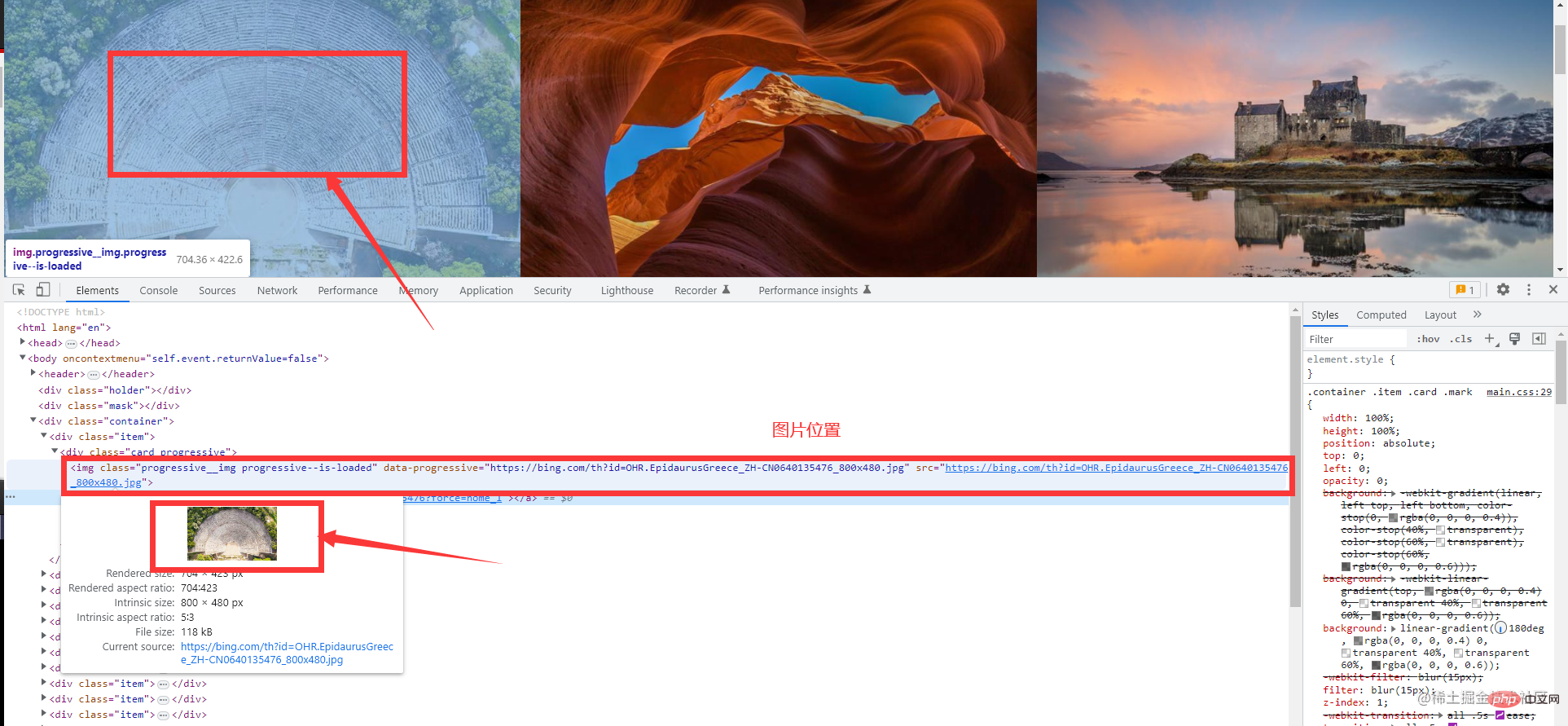
程式碼實戰
下面是爬取一頁的資料
package main
import (
"fmt"
"github.com/PuerkitoBio/goquery"
"io"
"io/ioutil"
"log"
"net/http"
"os"
"time"
)
func Run(method, url string, body io.Reader, client *http.Client) {
req, err := http.NewRequest(method, url, body)
if err != nil {
log.Println("获取请求对象失败")
return
}
req.Header.Set("user-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36")
resp, err := client.Do(req)
if err != nil {
log.Println("发起请求失败")
return
}
if resp.StatusCode != http.StatusOK {
log.Printf("请求失败,状态码:%d", resp.StatusCode)
return
}
defer resp.Body.Close() // 关闭响应对象中的body
query, err := goquery.NewDocumentFromReader(resp.Body)
if err != nil {
log.Println("生成goQuery对象失败")
return
}
query.Find(".container .item").Each(func(i int, s *goquery.Selection) {
imgUrl, _ := s.Find("a.ctrl.download").Attr("href")
imgName := s.Find(".description>h3").Text()
fmt.Println(imgUrl)
fmt.Println(imgName)
DownloadImage(imgUrl, i, client)
time.Sleep(time.Second)
fmt.Println("-------------------------")
})
}
func DownloadImage(url string, index int, client *http.Client) {
req, err := http.NewRequest("POST", url, nil)
if err != nil {
log.Println("获取请求对象失败")
return
}
req.Header.Set("user-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36")
resp, err := client.Do(req)
if err != nil {
log.Println("发起请求失败")
return
}
data, err := ioutil.ReadAll(resp.Body)
if err != nil {
log.Println("读取请求体失败")
return
}
baseDir := "./image/image-%d.jpg"
f, err := os.OpenFile(fmt.Sprintf(baseDir, index), os.O_CREATE|os.O_TRUNC|os.O_WRONLY, 0666)
if err != nil {
log.Println("打开文件失败", err.Error())
return
}
defer f.Close()
_, err = f.Write(data)
if err != nil {
log.Println("写入数据失败")
return
}
fmt.Println("下载图片成功")
}
func main() {
client := &http.Client{}
url := "https://bing.ioliu.cn/?p=%d"
method := "GET"
Run(method, url, nil, client)
}下面是爬取多頁資料爬取多頁的程式碼沒有多大的改動,我們還是需要先觀察網站的特點
 發現什麼了嗎?第一頁p=1,第二頁p=2,第十頁p=10
發現什麼了嗎?第一頁p=1,第二頁p=2,第十頁p=10
所以我們直接起一個for循環,然後復用之前爬取單頁的程式碼就行
// 爬取多页的main函数如下
func main() {
client := &http.Client{}
url := "https://bing.ioliu.cn/?p=%d"
method := "GET"
for i := 1; i < 5; i++ { // 实现分页操作
Run(method, fmt.Sprintf(url, i), nil, client)
}
}總結
在我們這個例子中,我們解析網頁資料使用的工具的一個第三方包,因為用正規真的太麻煩了
推薦學習:Golang教學
#以上是詳解怎麼使用Golang爬取必應壁紙的詳細內容。更多資訊請關注PHP中文網其他相關文章!