
深入理解MySQL索引優化器工作原理

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2022-11-09 14:05:241721瀏覽
這篇文章為大家帶來了關於mysql的相關知識,其中主要介紹了關於索引優化器工作原理的相關內容,其中包括了MySQL Server的組成,MySQL優化器選擇索引額原理以及SQL成本分析,最後透過select 查詢總結整個查詢過程,下面一起來看一下,希望對大家有幫助。

推薦學習:mysql影片教學
#一、MySQL 最佳化器是如何選擇索引的
下面我們來看這張表,SUB_ODR_ID欄位建立了相關的2 個索引,根據我們前面所學我們建立一個PRIMARY KEY (ID)自增主鍵索引,(LOG_ID, SUB_ODR_ID)設定為聯合索引、唯一索引,兩個時間CREATE_TIME、UPDATE_TIME分別設定兩個索引。
CREATE TABLE `***` ( `ID` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键id', `LOG_ID` varchar(32) NOT NULL COMMENT '交易流水号', `ODR_ID` varchar(32) NOT NULL COMMENT '父单号', `SUB_ODR_ID` varchar(32) NOT NULL COMMENT '子单号', `CREATE_TIME` datetime(0) NOT NULL COMMENT '创建时间', `CREATE_BY` varchar(32) NOT NULL COMMENT ' 创建人', `UPDATE_TIME` datetime(0) NOT NULL DEFAULT CURRENT_TIMESTAMP(0) ON UPDATE CURRENT_TIMESTAMP(0) COMMENT '更新时间', `UPDATE_BY` varchar(32) NOT NULL COMMENT '更新人', PRIMARY KEY (`ID`) USING BTREE, UNIQUE INDEX `UNQ_LOG_SUBODR_ID`(`LOG_ID`, `SUB_ODR_ID`) USING BTREE, INDEX `IDX_ODR_ID`(`ODR_ID`) USING BTREE, INDEX `IDX_SUB_ID`(`SUB_ODR_ID`) USING BTREE, INDEX `IDX_CREATE_TIME`(`CREATE_TIME`) USING BTREE, INDEX `IDX_UPDATE_TIME`(`UPDATE_TIME`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 1 SET = utf8 COLLATE = utf8_general_ci COMMENT = '分摊业务明细表' ROW_FORMAT = Dynamic;
在查詢欄位 SUB_ODR_ID 中,理論上可以使用三個相關的索引:UNQ_LOG_SUBODR_ID、IDX_SUB_ID,MySQL優化器如何從這三個索引中進行選擇?
在關聯式資料庫中,B 樹只是用來儲存的資料結構。
如何使用它取決於資料庫的最佳化器。優化器確定特定索引的選擇,即執行計劃。優化器的選擇是基於成本,成本越低,首選指數越高。
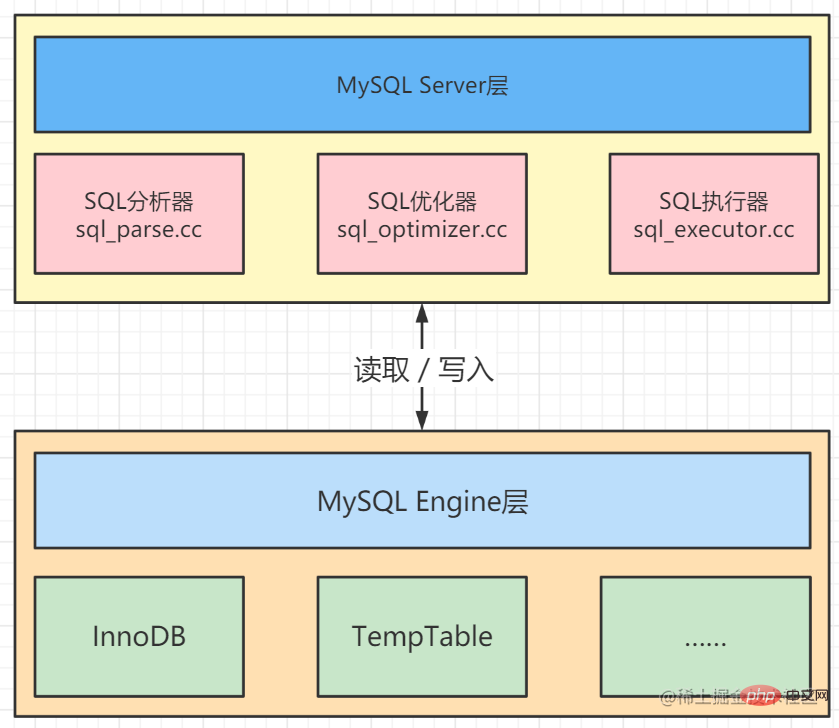
1、MySQL資料庫組成
MySQL資料庫由Server(伺服器)層和Engine(引擎)層組成。
Serve層有SQL分析器、SQL最佳化器和SQL執行器,負責SQL語句的特定執行過程。
Engine層負責儲存特定數據,例如最常用的InnoDB儲存引擎,以及用於在記憶體中儲存臨時結果集的TempTable引擎。
SQL優化器將分析所有可能的執行計劃,並選擇成本最低的執行。這個優化器被稱為CBO(基於成本的優化器)。
2、MySQL資料庫成本計算
在MySQL中,一條SQL 的運算成本計算,很好理解,就是訪問資料庫(資料庫頁、磁碟) 處理資料。
CPU成本,表示計算成本,例如索引鍵值的比較、記錄值的比較和結果集的排序。這些操作都在伺服器層完成
IO成本,表示引擎級IO的成本,MySQL 8.0可以透過區分錶的資料是否在記憶體中來分別計算讀取記憶體IO和磁碟IO的成本。
Cost = Server Cost + Engine Cost = CPU Cost + IO Cost
MySQL優化器認為,如果一段SQL需要建立一個基於磁碟的臨時表,那麼此時的成本是最大的,是基於記憶體的臨時表的20倍。比較索引鍵值和記錄的成本很低,但如果要比較的記錄很多,成本就會非常大。
MySQL 最佳化器認為,從磁碟讀取的開銷是記憶體開銷的 4 倍(成本不是一成不變的會根據硬體變化)。
二、MySQL查詢成本
查看各成本的值,MySQL優化器的工作原理,我們執行下面這行SQL語句,分析執行過程,MySQL 索引選擇是基於SQL 執行成本
EXPLAIN FORMAT=json select * from test.fork_business_detail f where f.sub_odr_id = ''
read_cost表示從InnoDB儲存引擎讀取的成本;
eval_cost表示伺服器層的CPU成本;
prefix_cost表示SQL的總成本;
data_read_per_join 表示讀取記錄中的位元組總數。
{
"query_block": {
"cost_info": {
"query_cost": "1.20"
},
"table": {
"access_type": "ref",
"possible_keys": [
"IDX_SUB_ID"
],
"key": "IDX_SUB_ID",
"used_key_parts": [
"SUB_ODR_ID"
],
"key_length": "98",
"ref": [
"const"
],
"cost_info": {
"read_cost": "1.00",
"eval_cost": "0.20",
"prefix_cost": "1.20",
"data_read_per_join": "1K"
},
"used_columns": [
"ID",
"LOG_ID",
"ODR_ID",
"SUB_ODR_ID",
"CREATE_TIME",
"CREATE_BY",
"UPDATE_TIME",
"UPDATE_BY"
]
}
}
}
三、SELECT 執行過程
如何提升MySQL的查詢效能?首先,您需要了解查詢最佳化器進行SQL處理的整個過程。 SELECT SQL 的執行過程為例,如下圖所示:
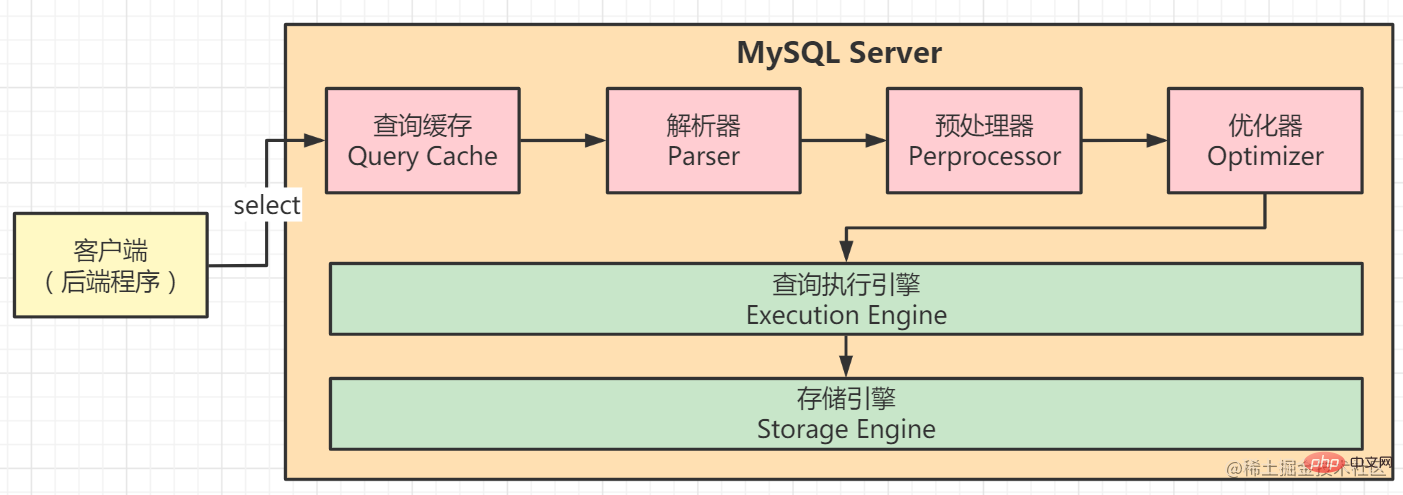
#用戶端傳送SELECT查詢至伺服器查詢;伺服器先檢查查詢快取。如果快取被命中,儲存在快取中的結果將立即回傳。否則,進入下一階段;
伺服器執行SQL解析、預處理,查詢最佳化器產生對應的執行計劃;MySQL根據最佳化器產生的執行計劃呼叫儲存引擎的API執行查詢;結果將返回到客戶端,並同時放入查詢快取。
推薦學習:mysql影片教學
#以上是深入理解MySQL索引優化器工作原理的詳細內容。更多資訊請關注PHP中文網其他相關文章!