
詳細介紹Java虛擬機器:JVM垃圾回收器

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2022-07-14 16:52:392092瀏覽
這篇文章為大家帶來了關於java的相關知識,其中主要整理了JVM垃圾回收器的相關問題,包括了Serial與Serial Old 回收器、ParNew 回收器、Parallel 與Parallel Old 回收器等等內容,下面一起來看看,希望對大家有幫助。

推薦學習:《java影片教學》
並發與並行
- 並行(Parallel ):並行描述的是多條垃圾收集器執行緒之間的關係,說明同一時間有多條這樣的執行緒在協同工作,通常預設此時使用者執行緒是處於等待狀態。
- 並發(Concurrent):並發描述的是垃圾收集器執行緒與使用者執行緒之間的關係,說明同一時間垃圾收集器執行緒與使用者執行緒都在運行。由於使用者執行緒並未被凍結,所以程式仍然能回應服務請求,但由於 垃圾收集器執行緒佔用了一部分系統資源,此時應用程式的處理的吞吐量將受到一定影響。
垃圾回收器的分類
1. 以執行緒數分
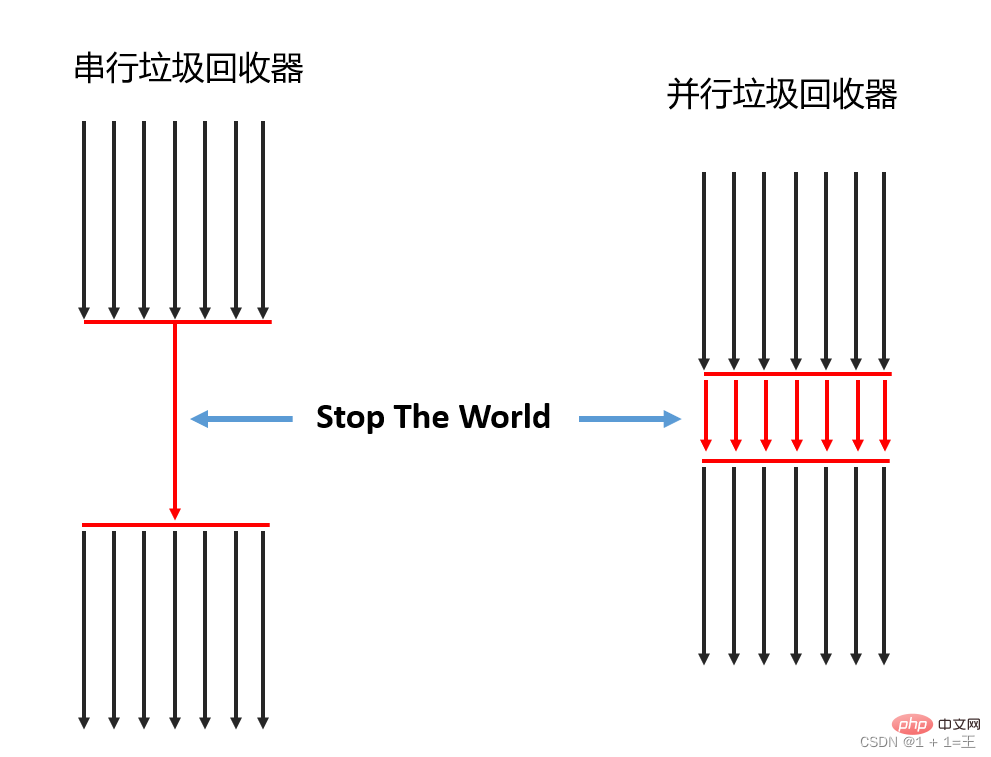
依照執行緒數(用於垃圾回收的)可以分為串列垃圾回收器和並行垃圾回收器。
- 串行垃圾回收器:在同一時間段內只允許有一個cPU用於執行垃圾回收操作,此時工作執行緒被暫停,直到垃圾收集工作結束。
- 並行垃圾回收器:可以運用多個CPU同時執行垃圾回收。

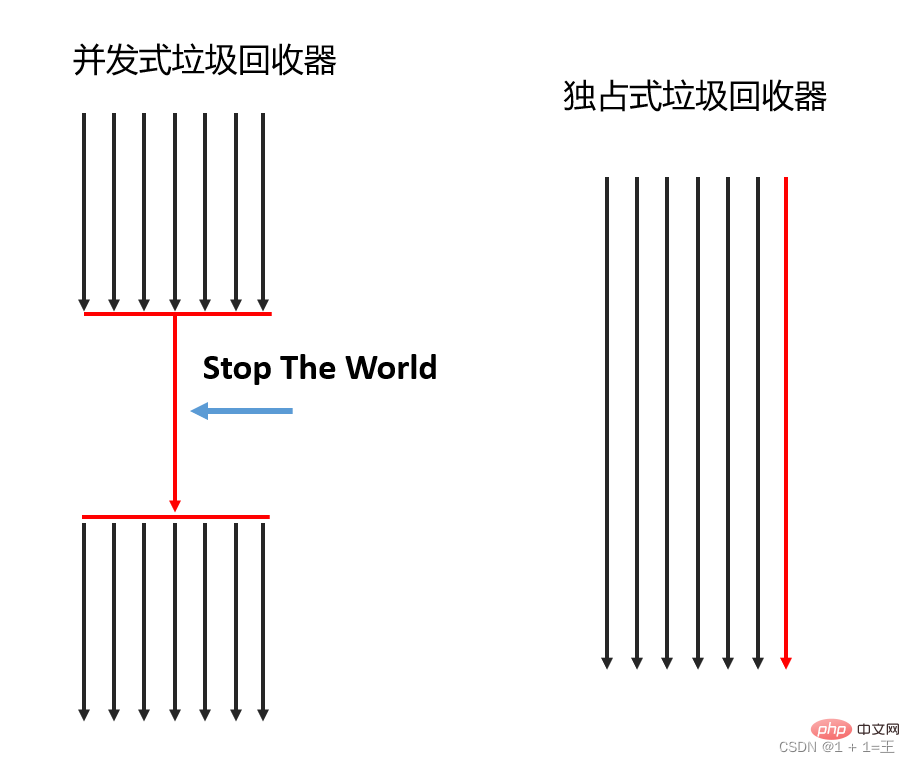
2. 以工作模式分
依照工作模式可以分為並發式垃圾回收器和獨佔式垃圾回收器。 - 並發式垃圾回收器:在同一時間段內只允許有一個cPU用於執行垃圾回收操作,此時工作執行緒被暫停,直到垃圾收集工作結束。
- 獨佔式垃圾回收器:可以運用多個CPU同時執行垃圾回收。
3. 以碎片處理方式分
依照工作模式可以分為壓縮式垃圾回收器和非壓縮式垃圾回收器。
壓縮式垃圾回收器會在回收完成後,對存活物件進行壓縮整理,消除回收後的碎片。
7種經典的垃圾回收器
- 序列回收器: serial、serial old
- 並列回收器: ParNew、Parallel scavenge、Parallel old
- 並發回收器: CMS、G1
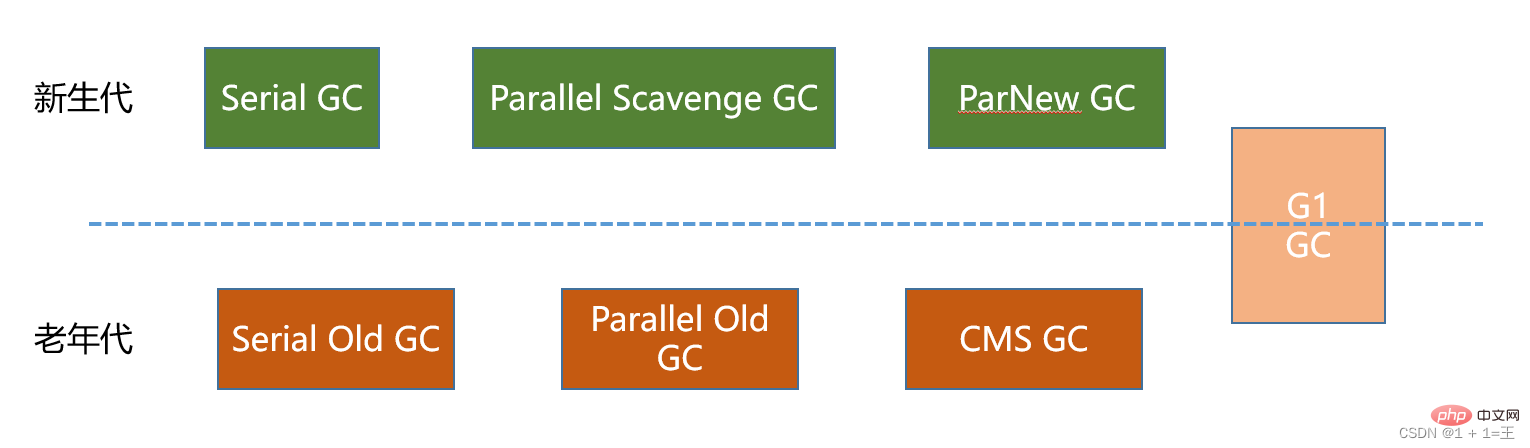
- 新生代收集器: serial、ParNew、Parallel scavenge;
- 舊年代收集器: Serial old、 Parallel old、CMS;
- 整堆收集器: G1;
垃圾回收器
Serial與Serial Old 回收器
Serial收集器是最基礎、歷史最悠久的收集器,曾經(在JDK 1.3.1之前)是HotSpot虛擬機新生代收集器的唯一選擇。 Serial收集器是一個單線程工作的收集器,當它進行垃圾收集時,必須暫停其他所有工作線程,直到它收集結束。
Serial Old是Serial收集器的老年代版本。
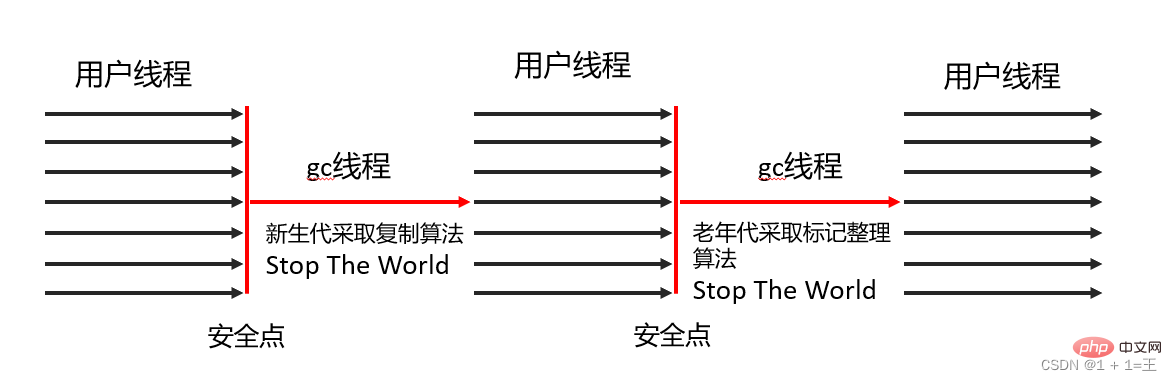
- Serial回收器採用複製演算法、串列回收和「Stop The World」 機制執行垃圾回收。
- Serial Old回收器標記—壓縮演算法、串列回收和「Stop The World」 機制執行垃圾回收。
ParNew 回收器
ParNew收集器實質上是Serial收集器的多執行緒並行版本,除了同時使用多條執行緒進行垃圾收集之外,其餘的行為包括Serial收集器可用的所有控制參數、收集演算法、Stop The World、物件分配規則、回收策略等都與Serial收集器完全一致。 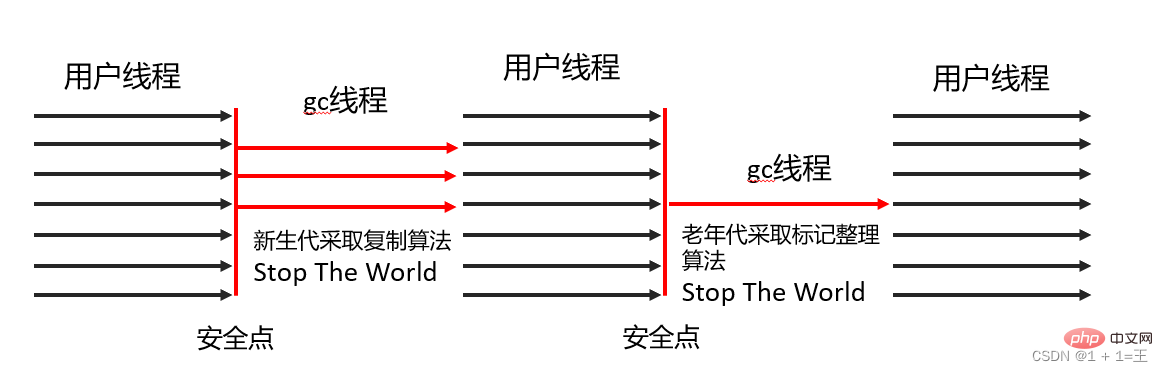
Parallel 與Parallel Old 回收器
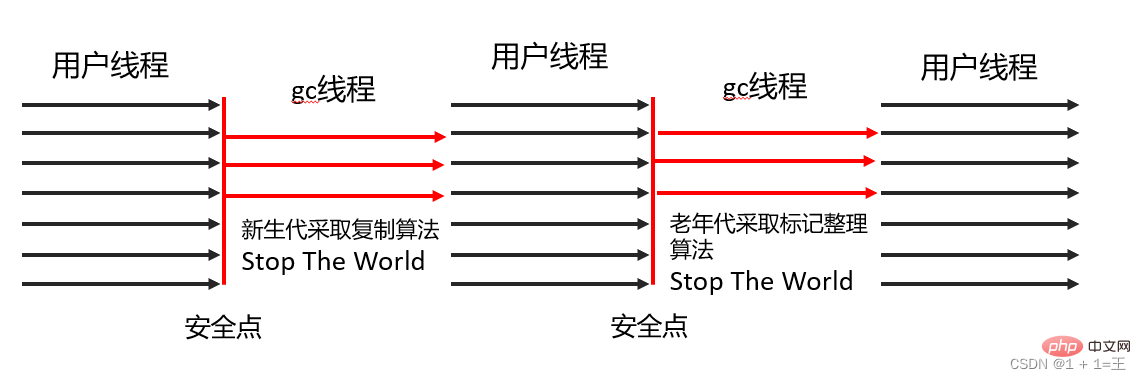
Parallel Scavenge收集器也是一款新生代收集器,它同樣是基於標記-複製演算法實現的收集器,也是能夠並行收集的多執行緒收集器。
和ParNew收集器不同,Parallel scavenge收集器的目標則是達到一個可控制的吞吐量,它也被稱為吞吐量優先的垃圾收集器。
吞吐量:處理器用於執行使用者程式碼的時間與處理器總消耗時間的比值。
高吞吐量可以最高效率地利用處理器資源,盡快完成程式的運算 任務,主要適合在背景運算而不需要太多互動的分析任務。
Parallel Old是Parallel Scavenge收集器的老年代版本,支援多執行緒並發收集,基於標記-整理演算法實 現。
CMS回收器
CMS(Concurrent Mark Sweep)收集器是一種以獲取最短回收停頓時間為目標的收集器。
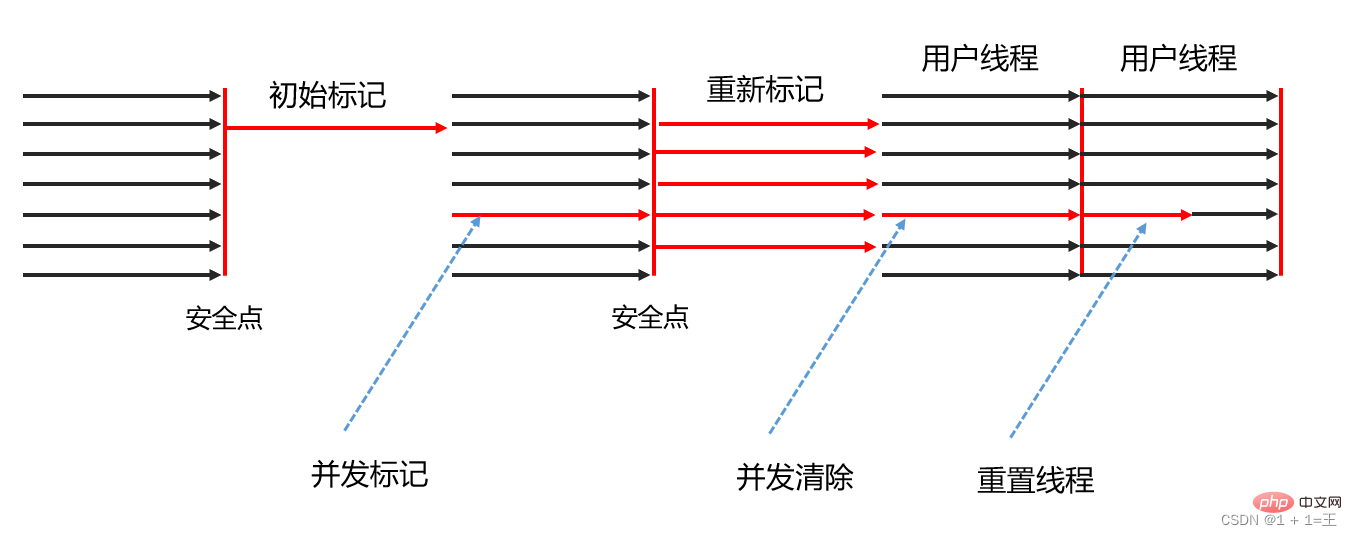
CMS收集器是基於標記-清除演算法實現的,它的運作可以分為四個步驟,包括:
- 初始標記
初始標記只是標記一下GC Roots能直接關聯到的對象,速度很快; - 並發標記
並發標記階段就是從GC Roots的直接關聯對象開始遍歷整個對象圖的過程,這個過程耗時較長但是不需要停頓用戶線程,可以與垃圾收集線程一起並發運行; - 重新標記
重新標記階段則是為了修正並發標記期間,因用戶程式繼續運作而導致標記產生變動的那一部分物件的標記記錄,這個階段的停頓時間通常會比初始標記階段稍長一些,但也遠比並發標記階段的時間短; - 並發清除
清理刪除掉標記階段判斷的已經死亡的對象,由於不需要移動存活對象,所以這個階段也是可以與使用者執行緒同時並發的。
CMS收集器無法處理“浮動垃圾”,有可能出現“Con-current Mode Failure”失敗進而導致另一個完全“Stop The World」的Full GC的產生。
在CMS的並發標記和並發清理階段,使用者執行緒是還在繼續運行的,程式在運行自然就還會伴隨有新的垃圾物件不斷產生,但這一部分垃圾物件是出現在標記過程結束以後,CMS無法在當次收集中處理掉它們,只好留待下一次垃圾收集時再清理掉。這一部分垃圾就稱為「浮動垃圾」。
同樣也是由於在垃圾收集階段使用者執行緒還需要持續運行,那就還需要預留足夠記憶體空間提供給使用者執行緒使用,因此CMS收集器不能像其他收集器一樣等待到老年代幾乎完全被填滿了再進行收集,必須預留一部分空間供並發收集時的程序運作使用。
CMS是基於「標記-清除」演算法實現的收集器,意味著收集結束時會有大量空間碎片產生,空間碎片過多時,將會給大物件分配帶來很大麻煩。
為什麼不使用標記—壓縮演算法避免碎片?
因為當並發清除時,用標記—壓縮整理記憶體的話,原來的使用者執行緒所使用的記憶體就無法使用。要保證使用者執行緒繼續執行,前提是它運行的資源不受影響。標記—壓縮更適合在「Stop The World」場景下使用。
G1(Garbage First)回收器
Garbage First開創了收集器面向局部收集的設計思路和基於Region的記憶體佈局形式,它是一款主要面向服務端應用的垃圾收集器,主要針對配備多核心CPU及大容量記憶體的機器,以極高機率滿足GC停頓時間的同時,也兼具高吞吐量的效能特性。
G1收集器出現之前的所有其他收集器,垃圾收集的目標範圍要不是整個新生代,就是整個老年代,再要嘛就是整個Java堆。而G1可以面向堆內存任何部分來組成回收集(Collection Set)進行回收,衡量標準不再是它屬於哪個分代,而是哪塊內存中存放的垃圾數量最多,回收收益最大。
G1回收器的特性
1. 並行與並發
- #並行性:G1在回收期間,可以有多個GC線程同時工作,此時用戶線程Stop The World。
- 並發性:G1擁有與應用程式交替執行的能力,部分工作可以和應用程式同時執行,因此,一般來說,不會在整個回收階段發生完全阻塞應用程式的情況。
2. 分代收集
#- G1也仍是遵循分代收集理論設計的,但其堆記憶體的佈局與其他收集器有非常明顯的差異:G1不再堅持固定大小以及固定數量的分代區域劃分,而是把連續的Java堆劃分為多個大小相等的獨立區域(Region),每一個Region都可以根據需要,扮演新生代的Eden空間、Survivor空間,或者老年代空間。 收集器能夠對扮演不同角色的 Region採用不同的策略去處理,這樣無論是新創建的對象還是已經存活了一段時間、熬過多次收集的 舊對像都能獲得很好的收集效果。
- Region中還有一類特殊的Humongous區域,專門用來儲存大物件。 G1認為只要大小超過了一個 Region容量一半的物件即可判定為大物件。
3. 空間整合
- G1在記憶體回收時以region為基本單位,region之間使用複製演算法,但整體可看做是標記—壓縮演算法。
4. 可預測的停頓時間模型
- #G1收集器能建立可預測的停頓時間模型,它將Region作為單次回收的最小單元,即每次收集到的記憶體空間都是Region大小的整數倍,這樣可以有計劃地避免在整個Java堆中進行全區域的垃圾收集。
- G1收集器去追蹤各個Region裡面的垃圾堆積的「價值」大小,價值即回收所獲得的空間大小以及回收所需時間的經驗值,然後在後台維護一個優先列表,每次根據用戶設定允許的收集停頓時間,優先處理回收價值收益最大的那些Region。
- 這種使用Region劃分記憶體空間,以及具有優先順序的區域回收方式,保證了G1收集器在有限的時間內獲 取盡可能高的收集效率。
- 停頓預測模型是以衰減均值為理論基礎來實現的,在垃圾收集過程中,G1收集器會記錄每個Region的回收耗時、每個Region記憶集裡的髒卡數量等各個可測量的步驟所花費的成本,並分析得出平均值、標準差、置信度等統計資料。然後透過這些資訊預測現在開始回收的話,由 哪些Region組成回收集才可以在不超過期望停頓時間的限制下獲得最高的收益。
Region裡面存在的跨Region引用物件如何解決?
使用記憶集避免全堆作為GC Roots掃描,它的每個Region都維護有自己的記憶集,這些記憶集會記錄下別的Region 指向自己的指針,並標記這些指針分別在哪些卡頁的範圍之內。 G1的記憶集在儲存結構的本質上是一 種雜湊表,Key是別的Region的起始位址,Value是一個集合,裡面儲存的元素是卡片表的索引號碼。
G1收集器的運作過程
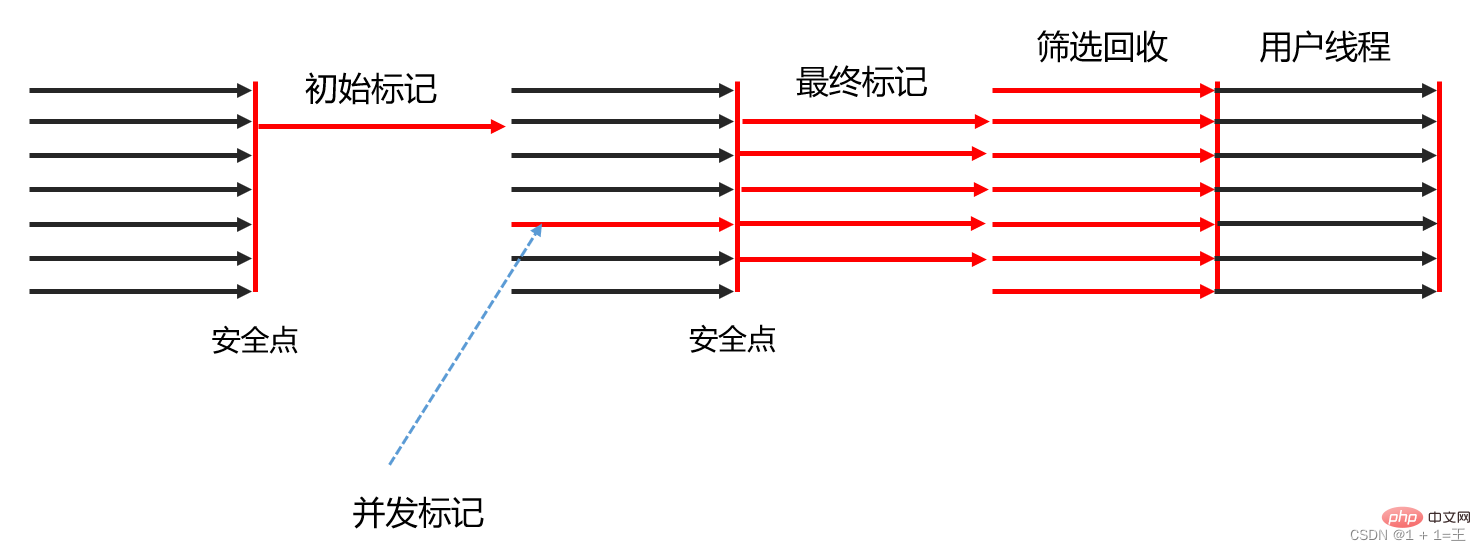
- 初始標記(Initial Marking):只是標記一下GC Roots能直接關聯到的對象,並且修改TAMS指標的值,讓下一階段使用者執行緒並發運行時,能正確地在可用的Region中分配新物件。這個階段需要 停頓線程,但耗時很短,而且是藉用進行Minor GC的時候同步完成的,所以G1收集器在這個階段實際 並沒有額外的停頓。
- 並發標記(Concurrent Marking):從GC Root開始對堆中物件進行可達性分析,遞歸掃描整個堆裡的物件圖,找出要回收的對象,這階段耗時較長,但可與使用者程式並發執行。當物件圖掃描完成以 後,也要重新處理SATB記錄下的在並發時有引用變動的物件。
- 最終標記(Final Marking):對使用者執行緒做另一個短暫的暫停,用於處理並發階段結束後仍遺留 下來的最後那少量的SATB記錄。
- 篩選回收(Live Data Counting and Evacuation):負責更新Region的統計數據,對各個Region的回收價值和成本進行排序,根據用戶所期望的停頓時間來製定回收計劃,可以自由選擇任意多個Region 構成回收集,然後把決定回收的那一部分Region的存活對象複製到空的Region中,再清理掉整個舊Region的全部空間。這裡的操作涉及存活物件的移動,是必須暫停使用者線程,由多個收集器線程並行 完成的。
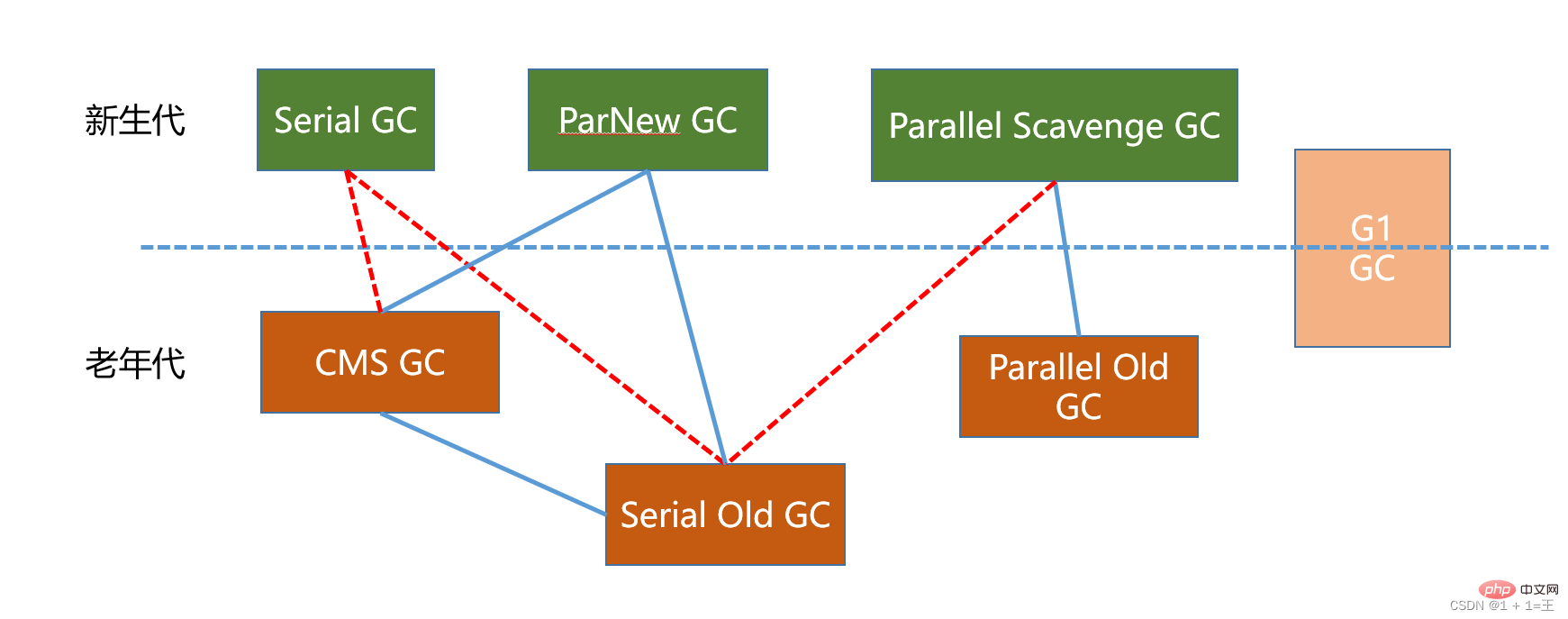
7種經典垃圾回收器的比較
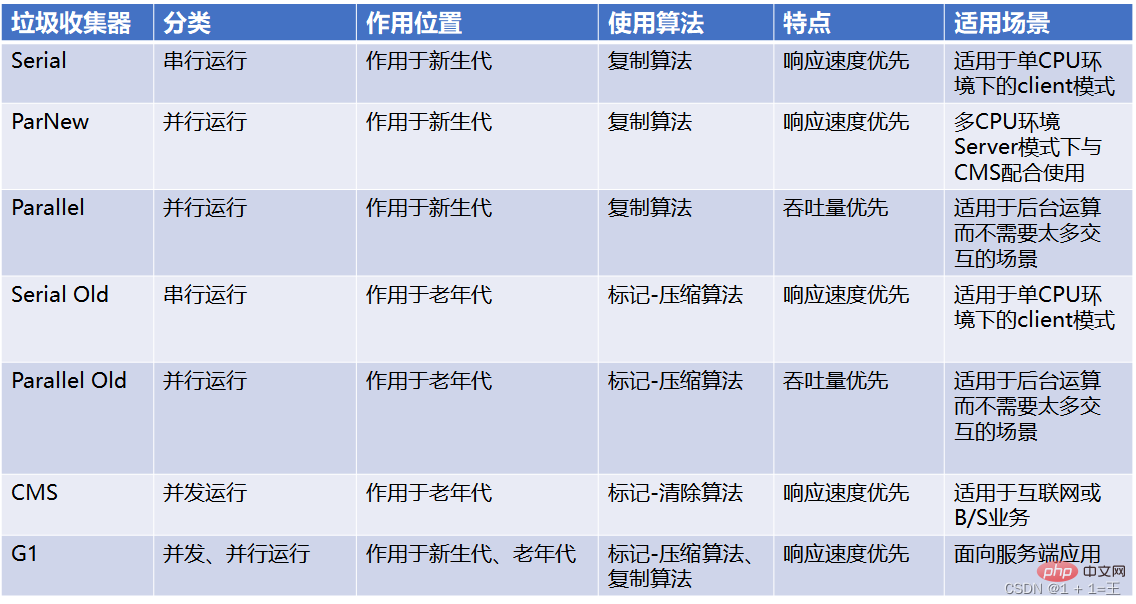
垃圾回收器組合
低延遲垃圾收集器
Shenandoah收集器
Shenandoah也是使用基於Region的堆記憶體佈局,同樣有著用於存放大物件的Humongous Region,預設的回收策略也同樣是優先處理回收價值最大的Region……但在管理堆記憶體方面,它與G1至少有三個明顯的不同之處。
- G1的回收階段是可以多執行緒並行的,但卻不能與使用者執行緒並發,Shenandoah支援並發的整理演算法。
- 預設不使用分代收集的,換言之,不會有專門的新生代Region或者老年代Region的存在,沒有實現分代,並不是說分代對Shenandoah沒有價值, 這更多是出於性價比的權衡,基於工作量上的考慮而將其放到優先順序較低的位置。
- Shenandoah摒棄了在G1中耗費大量記憶體和運算資源去維護的記憶集,改用名為「連接矩陣」的全域資料結構來記錄跨Region的引用關係,降低了處理跨代指針時的記憶集維護消耗,也降低了偽共享問題的發生機率。連接矩陣可以簡單理解為一張二維表格,如果Region N有物件指向Region M,就在表格的N行M列中打上一個標記,在回收時透過這張表格就可以得出哪些Region之間產生了跨代引用。
Shenandoah收集器的工作過程大致可以分割為以下九個階段:
- 初始標記:與G1一樣,先標記與GC Roots直接關聯的對象,這個階段仍是「Stop The World」的,但停頓時間與堆大小無關,只與GC Roots的數量相關。
- 並發標記:與G1一樣,遍歷對象圖,標記出全部可達的對象,這個階段是與用戶線程一起並發的,時間長短取決於堆中存活對象的數量以及物件圖的結構複雜程度。
- 最終標記:與G1一樣,處理剩餘的SATB掃描,並在這個階段統計出回收價值 最高的Region,將這些Region構成一組回收集。最終標記階段也會有一小段短暫的停頓。
- 並發清理:這個階段用來清理那些整個區域內連一個存活物件都沒有找到 的Region。
- 並發回收:在這個階段,Shenandoah要把回收集裡面的存活物件先複製一份到其他未被使用的Region之 中。並發回收階段運作的時間長短取決於回收集的大小。
- 初始引用更新:並發回收階段複製物件結束後,還需要把堆中所有指 向舊物件的參考修正到複製後的新位址,這個操作稱為引用更新。引用更新的初始化階段實際上並未 做什麼具體的處理,設立這個階段只是為了建立一個線程集合點,確保所有並發回收階段中進行的收 集器線程都已完成分配給它們的對象移動任務而已。初始引用更新時間很短,會產生一個非常短暫的 停頓。
- 並發引用更新:真正開始進行引用更新操作,這個階段是與使用者 執行緒一起並發的,時間長短取決於記憶體中涉及的引用數量的多少。並發引用更新與並發標記不同,它 不再需要沿著對象圖來搜索,只需要按照內存物理地址的順序,線性地搜索出引用類型,把舊值改為 新值即可。
- 最終引用更新:解決了堆中的引用更新後,也要修正存在於GC Roots 中的參考。這個階段是Shenandoah的最後一次停頓,停頓時間只與GC Roots的數量有關。
- 並發清理:經過並發回收和引用更新之後,整個回收集中所有的Region已再無存活對象,這些Region都變成Immediate Garbage Regions了,最後再調用一次並發清理過程來回收這些Region的記憶體空間,以供日後新物件分配使用。
ZGC收集器
ZGC和Shenandoah的目標是高度相似的,都希望在盡可能對吞吐量影響不太大的前提下,實現在任意堆內存大小下都可以把垃圾收集的停頓時間限制在十毫秒以內的低延遲。
ZGC收集器是一款基於Region記憶體佈局的,(暫時) 不設分代的,使用了讀取屏障、染色指針和內存多重映射等技術來實現可並發的標記-整理演算法的,以低延遲為首要目標的一款垃圾收集器。
ZGC也採用基於Region的堆記憶體佈局,但 與它們不同的是,ZGC的Region具有動態性-動態建立和銷毀,以及動態的區域容量大小。
ZGC的運作過程可分為四個階段:
- 並發標記(:與G1、Shenandoah一樣,並發標記是遍歷物件圖做可達性分析的階段,前後也要經過類似G1、Shenandoah的初始標記、最終標記(儘管ZGC中的名字不叫這些)的短暫停頓,而且這些停頓階段所做的事情在目標上也是相類似的。與G1、Shenandoah不同的是,ZGC 的標記是在指針上而不是在對象上進行的,標記階段會更新染色指針中的Marked 0、Marked 1標誌位。
- #並發預備重分配:這個階段需要根據特定的查詢條件統計得出本次收集過程要清理哪些Region,將這些Region組成重分配集。
- 並發重分配:重新分配是ZGC執行過程中的核心階段,這個過程要把重分配集中的存活物件複製到新的Region上,並為重分配集中的每個Region維護一個轉發表,記錄從舊物件到新物件的轉向關係。
- 並發重映射:重新映射所做的就是修正整個堆中指向重分配集中舊物件的所有引用。ZGC很巧妙地把並發重映射階段要做的工作,合併到了下一次垃圾收集循環中的並發標記階段裡去完成,反正它們都是要遍歷所有物件的,這樣合併就節省了一次遍歷物件圖的開銷。一旦所有指標都被修正之後,原來記錄新舊物件關係的轉發表就可以釋放掉了。
選擇合適的垃圾收集器
考慮以下三個問題:
應用程式的主要關注點是什麼?
- 如果是資料分析、科學計算類的任務,目標是能盡快算出結果, 那吞吐量就是主要關注點;
- 如果是SLA應用,那停頓時間直接影響服務質量,嚴重的甚至會導致事務超時,這樣延遲就是主要關注點;
- 而如果是客戶端應用或嵌入式應用,那垃圾收集的記憶體佔用則是不可忽視的。
運行應用程式的基礎設施如何?
- 硬體規格,要涉及的系統架構是x86-32/64、SPARC還是ARM/Aarch64;
- 處理器的數量多少,分配記憶體的大小;
- 選擇的作業系統是Linux、Solaris還是Windows 等。
使用JDK的發行商是什麼?版本號碼是多少?
是ZingJDK/Zulu、OracleJDK、 Open-JDK、OpenJ9抑或是其他公司的發行版?該JDK對應了《Java虛擬機規範》的哪個版本?
怎麼選擇垃圾回收器
- 優先調整堆的大小讓JVM自適應完成。
- 如果記憶體小於100M,使用串列收集器
- 如果是單核心、單機程序,且沒有停頓時間的要求,串列收集器
- 如果是多CPU、需要高吞吐量、允許停頓時間超過1秒,選擇並行或JVM自己選擇
- 如果是多CPU、追求低停頓時間,需快速反應(例如延遲不能超過1秒網路應用),使用並發收集器
推薦學習:《java影片教學》
以上是詳細介紹Java虛擬機器:JVM垃圾回收器的詳細內容。更多資訊請關注PHP中文網其他相關文章!