
MySQL學習之explain用法詳解

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2022-03-07 16:56:132661瀏覽
本篇文章為大家帶來了關於mysql中的相關知識,其中主要介紹了關於explain的相關問題,explain指令主要來查看SQL語句的執行計劃,查看該SQL語句有沒有使用索引,有沒有做全表掃描,希望對大家有幫助。

推薦學習:mysql教學
# explain指令主要來查看SQL語句的執行計劃,查看該SQL語句有沒有使用索引,有沒有做全表掃描等。它可以模擬最佳化器執行SQL查詢語句,從而知道MySQL是如何處理使用者的SQL語句。
一、explain能做什麼
透過explain語句,我們可以分析出以下結果
| 表的讀取順序 | 資料讀取操作的操作類型 |
|---|---|
| 表之間的參考 | 哪些索引可以使用 |
| #每張表有多少行被最佳化器查詢 | 哪些索引被實際使用 |
#二、如何使用explain
用法:explain SQL 語句;
MariaDB [class_info]> explain select * from student; +--+-----------+-------+----+-------------+-----+-------+-----+----+-----+ |id|select_type| table |type|possible_keys| key |key_len| ref |rows|Extra| +--+-----------+-------+----+-------------+-----+-------+-----+----+-----+ | 1| SIMPLE |student| ALL| NULL | NULL| NULL | NULL| 1 | | +--+-----------+-------+----+-------------+-----+-------+-----+----+-----+ 1 row in set (0.00 sec)
expain出來10個字段,分別是id、select_type、table、 type、possible_keys、key、key_len、ref、rows、Extra
概要描述:
| 選擇標識符 | ##select_type |
| table | |
| type | |
| possible_keys | |
| key | ##實際使用的索引|
| key_len | 索引欄位的長度 |
三、explain各字段的含義
3.1 id
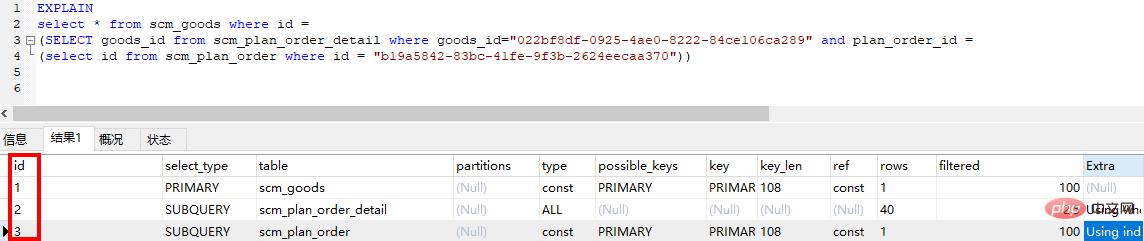
id是select查詢的序號,包含一組數字,表示查詢中執行select子句或操作表的順序。 id的結果有以下三種情況:
● id 相同,執行順序由上至下,與sql中順序無關

3.2 select_type#
select_type顯示示查詢中每個select子句的類型,常用的select_type的類型有simple、primary、subquery、derived、union、union result
simple (簡單select,不使用union或子查詢等任何複雜查詢)

primary (子查詢中最外層查詢,查詢中若包含任何複雜的子部分,最外層的select被標記為primary)

subquery (在select或where清單中包含了子查詢)
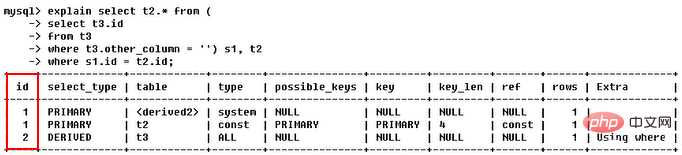
(4)derived (from清單中包含的子查詢被標記為derived(衍生),MySQL會遞歸執行這些子查詢,把結果放在臨時表中)
(5)union (union中的第二個或後面的select語句)
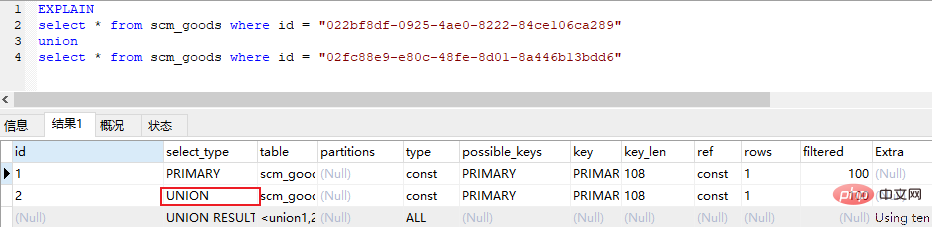
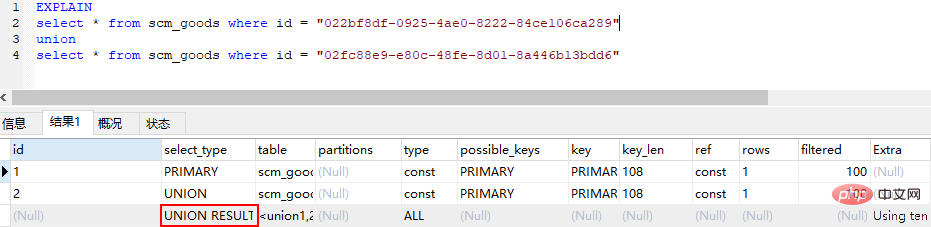
union result (union的結果,union語句中第二個select開始後面所有select)
3.3 table
table顯示這一步所存取資料庫中表名稱(顯示這一行的數據是關於哪張表的)。
3.4 type
type所顯示的是查詢使用了哪一種類型,type包含的類型有all、index、range、ref、eq_ref、 const、system、NULL,它的效能依序遞增。
all :Full Table Scan, MySQL將遍歷全表以找到符合的行

index : Full Index Scan,index與ALL區別為index類型只遍歷索引樹

range:只檢索給定範圍的行,使用一個索引來選擇行
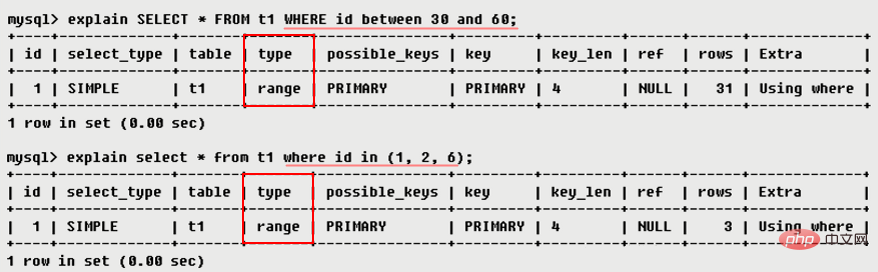
ref: 表示上述表的連接匹配條件,即哪些列或常數被用來尋找索引列上的值
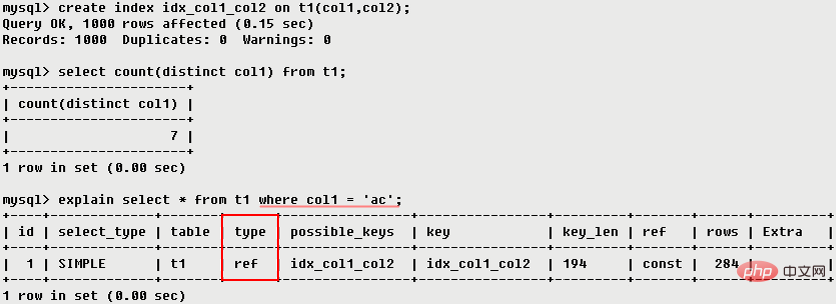
eq_ref : 類似ref,區別就在使用的索引是唯一索引,對於每個索引鍵值,表中只有一條記錄匹配,簡單來說,就是多表連接中使用primary key或unique key作為關聯條件
●const、system : 當MySQL對查詢某部分進行優化,並轉換為一個常數時,使用這些類型存取。如將主鍵置於where清單中,MySQL就能將該查詢轉換為一個常數,system是const類型的特例,當查詢的表只有一行的情況下使用system。

NULL : MySQL在最佳化過程中分解語句,執行時甚至不用存取資料表或索引,例如從索引列選取最小值可以透過單獨索引查找完成。
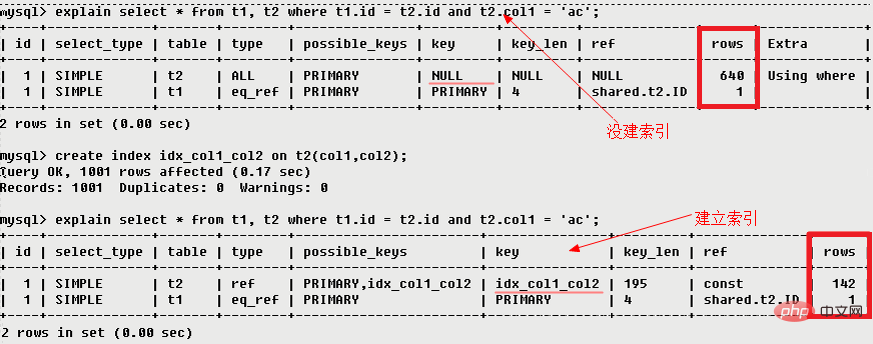
3.5 possible_keys
possible_keys顯示可能套用在這張表中的索引,一個或多個。查詢所涉及的欄位上若存在索引,則該索引將會被列出,但不一定會被查詢實際使用。 (該查詢可以利用的索引,如果沒有任何索引顯示 null)
3.6 key
key顯示MySQL實際決定使用的鍵(索引),必然包含在possible_keys中。如果沒有選擇索引,則是NULL。若要強制MySQL使用或忽略possible_keys欄位中的索引,在查詢中使用force index、use index 或 ignore index。
3.7 key_len
key_len表示索引中使用的位元組數,可透過該列計算查詢中使用的索引的長度(key_len顯示的值為索引字段的最大可能長度,並非實際使用長度,即key_len是根據表定義計算而得,不是通過表內檢索出的),在不損失精確性的情況下,長度越短越好。
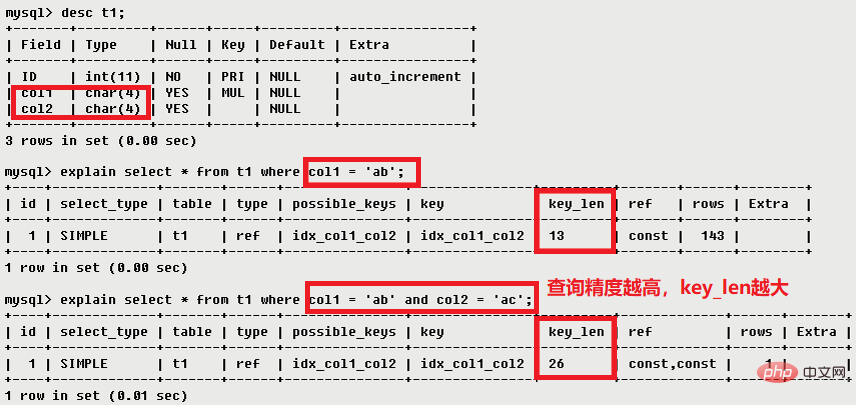
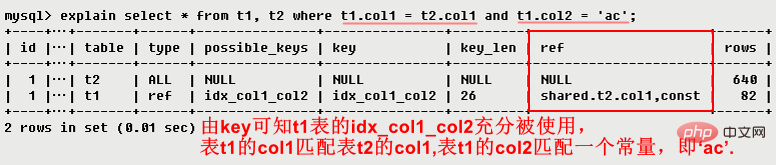
3.8 ref
ref顯示索引的那一列被使用,表示上述表格的連接符合條件,即哪些列或常數用來尋找索引列上的值
#3.9 rows
rows#估算出結果集的行數,表示MySQL根據表格統計資料及索引選用情況,估算的找到所需的記錄所需要讀取的行數。
3.10 Extra
Extra此列包含MySQL解決查詢的詳細資訊,有以下幾種情況:
的請求列都是同一個索引的部分的時候,表示mysql伺服器將在儲存引擎檢索行後再進行過濾
● Using temporary表示MySQL需要使用臨時表來儲存結果集,常見於排序和分組查詢,常見group by ; order by
● Using filesort當Query中包含order by 操作,而且無法利用索引完成的排序操作稱為「檔案排序」
● Using join buffer改值強調了在取得連接條件時沒有使用索引,並且需要連接緩衝區來儲存中間結果。如果出現了這個值,那麼應該要注意,根據查詢的具體情況可能需要添加索引來改進能。
● Impossible where 這個值強調了where語句會導致沒有符合條件的行(透過收集統計資料不可能有結果)。
● Select tables optimized away 這個值意味著僅透過使用索引,優化器可能只從聚合函數結果中傳回一行
● No tables used Query語句中使用from dual 或不含任何from子句
四、總結
● explain不會告訴你關於觸發器、預存程序的資訊或用戶自訂函數對查詢的影響情況
● explain不考慮各種Cache
● explain不能顯示MySQL在執行查詢時所作的最佳化工作
● explain解釋select操作,其他操作要重寫為select後查看執行計劃
● 部分統計資訊是估算的,並非精確值
推薦學習:mysql影片教學
以上是MySQL學習之explain用法詳解的詳細內容。更多資訊請關注PHP中文網其他相關文章!