
一起來聊聊如何使用Redis實現分散式鎖

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2022-03-02 18:10:522378瀏覽
本篇文章為大家帶來了關於Redis中的相關知識,其中主要介紹了分散式鎖的相關問題,我們通常說的線程調用加鎖和釋放鎖的操作,實際上,一個執行緒呼叫加鎖操作,其實就是檢查鎖變數值是否為0,希望對大家有幫助。

推薦學習:Redis學習教學
#單機上的鎖定與分散式鎖定的連結與差異
我們先來看下單機上的鎖。
對於在單機上執行的多執行緒程式來說,鎖本身可以用一個變數表示。
- 變數值為 0 時,表示沒有執行緒取得鎖定;
- 變數值為 1 時,表示已經有執行緒取得到鎖定了。
我們通常說的執行緒呼叫加鎖和釋放鎖的操作,實際上,一個執行緒呼叫加鎖操作,其實就是檢查鎖變數值是否為 0。如果是 0,就把鎖的變數值設為 1,表示取得到鎖,如果不是 0,就回傳錯誤訊息,表示加鎖失敗,已經有別的執行緒取得到鎖了。而一個執行緒呼叫釋放鎖定操作,其實就是將鎖變數的值置為 0,以便其它執行緒可以來取得鎖。
我用一段程式碼來展示下方加鎖和釋放鎖的操作,其中,lock 為鎖定變數。
acquire_lock(){
if lock == 0
lock = 1
return 1
else
return 0
}
release_lock(){
lock = 0
return 1
}
和單機上的鎖類似,分散式鎖同樣可以用一個變數來實作。客戶端加鎖和釋放鎖的操作邏輯,也和單機上的加鎖和釋放鎖操作邏輯一致:加鎖時同樣需要判斷鎖變數的值,根據鎖變數值來判斷能否加鎖成功;釋放鎖時需要把鎖變數值設為0,表示客戶端不再持有鎖。
但是,和執行緒在單機上操作鎖不同的是,在分散式場景下,鎖定變數需要由一個共享儲存系統來維護,只有這樣,多個客戶端才可以透過存取共享儲存系統來存取鎖變數。對應的,加鎖和釋放鎖的操作就變成了讀取、判斷和設定共享儲存系統中的鎖定變數值。
這樣一來,我們就可以得到實作分散式鎖定的兩個要求。
要求一:分散式鎖的加鎖和釋放鎖的過程,涉及多個操作。所以,在實現分散式鎖定時,我們需要確保這些鎖定操作的原子性;
要求二:共享儲存系統保存了鎖定變量,如果共享儲存系統發生故障或宕機,那麼客戶端也就無法進行鎖操作了。在實現分散式鎖時,我們需要考慮確保共享儲存系統的可靠性,進而確保鎖的可靠性。
好了,知道了具體的要求,接下來,我們就來學習下 Redis 是怎麼實現分散式鎖定的。
其實,我們既可以基於單一 Redis 節點來實現,也可以使用多個 Redis 節點實現。在這兩種情況下,鎖的可靠性是不一樣的。我們先來看基於單一 Redis 節點的實作方法。
基於單一Redis 節點實現分散式鎖定
作為分散式鎖定實作過程中的共享儲存系統,Redis 可以使用鍵值對來保存鎖定變量,然後接收和處理不同客戶端發送的加鎖和釋放鎖的操作請求。那麼,鍵值對的鍵和值具體是怎麼定的呢?
我們要賦予鎖變數一個變數名,把這個變數名當作鍵值對的鍵,而鎖變數的值,則是鍵值對的值,這樣一來,Redis 就能保存鎖變數了,客戶端也就可以透過Redis 的命令操作來實現鎖定操作。
為了幫助你理解,我畫了一張圖片,它展示 Redis 使用鍵值對保存鎖定變量,以及兩個客戶端同時請求加鎖的操作過程。 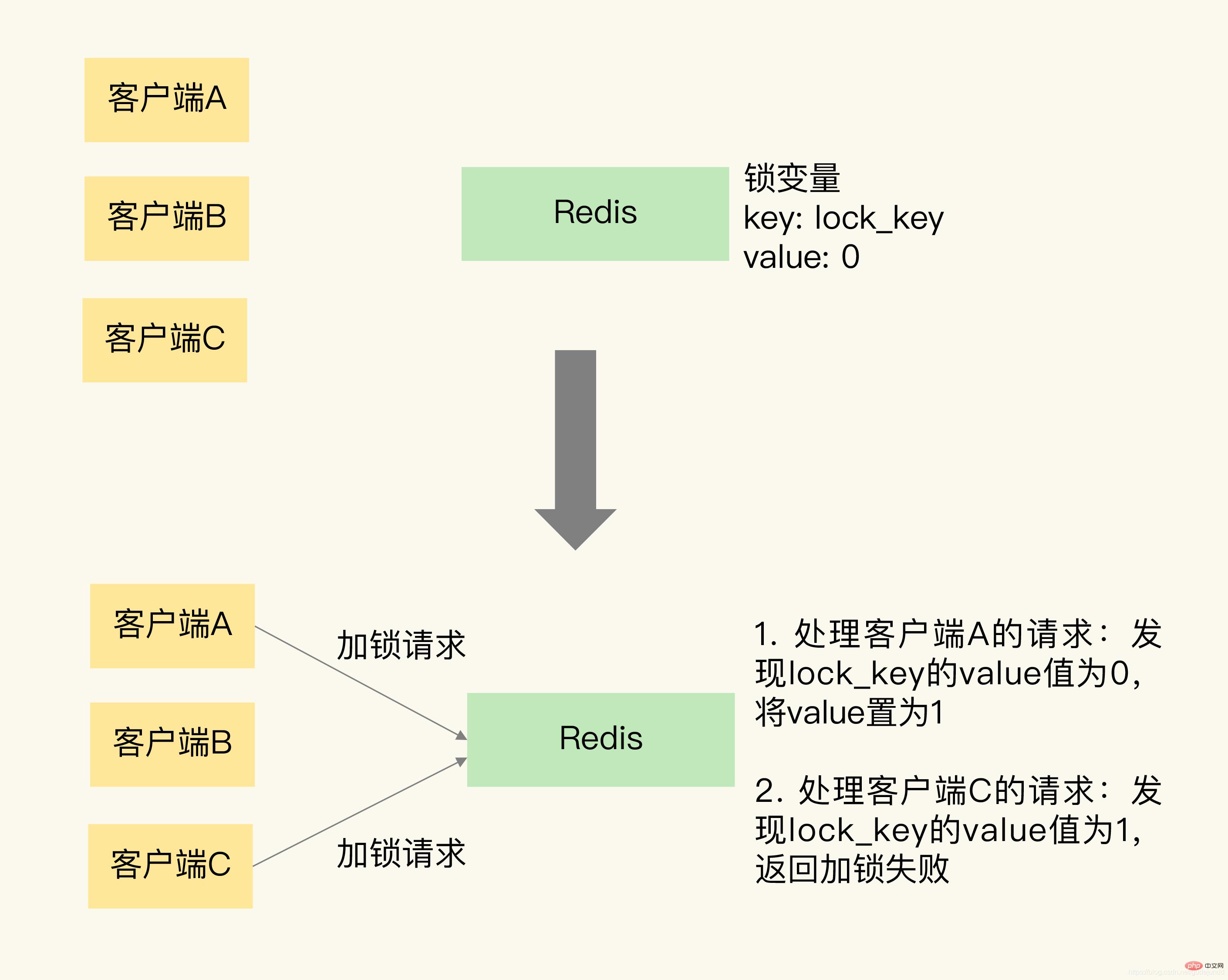
可以看到,Redis 可以使用一個鍵值對lock_key:0 來保存鎖定變量,其中,鍵是lock_key,也是鎖定變數的名稱,鎖定變數的初始值是0 。
我們再來分析下加鎖操作。
在圖中,客戶端 A 和 C 同時請求加鎖。因為 Redis 使用單執行緒處理請求,所以,即使客戶端 A 和 C 同時把加鎖請求發給了 Redis,Redis 也會串列處理它們的請求。
我們假設 Redis 先處理客戶端 A 的請求,讀取 lock_key 的值,發現 lock_key 為 0,所以,Redis 就把 lock_key 的 value 置為 1,表示已經加鎖了。緊接著,Redis 處理客戶端 C 的請求,此時,Redis 會發現 lock_key 的值已經為 1 了,所以就傳回加鎖失敗的訊息。
剛剛說的是加鎖的操作,那釋放鎖該怎麼操作呢?其實,釋放鎖定就是直接把鎖定變數值設為 0。
我还是借助一张图片来解释一下。这张图片展示了客户端 A 请求释放锁的过程。当客户端 A 持有锁时,锁变量 lock_key 的值为 1。客户端 A 执行释放锁操作后,Redis 将 lock_key 的值置为 0,表明已经没有客户端持有锁了。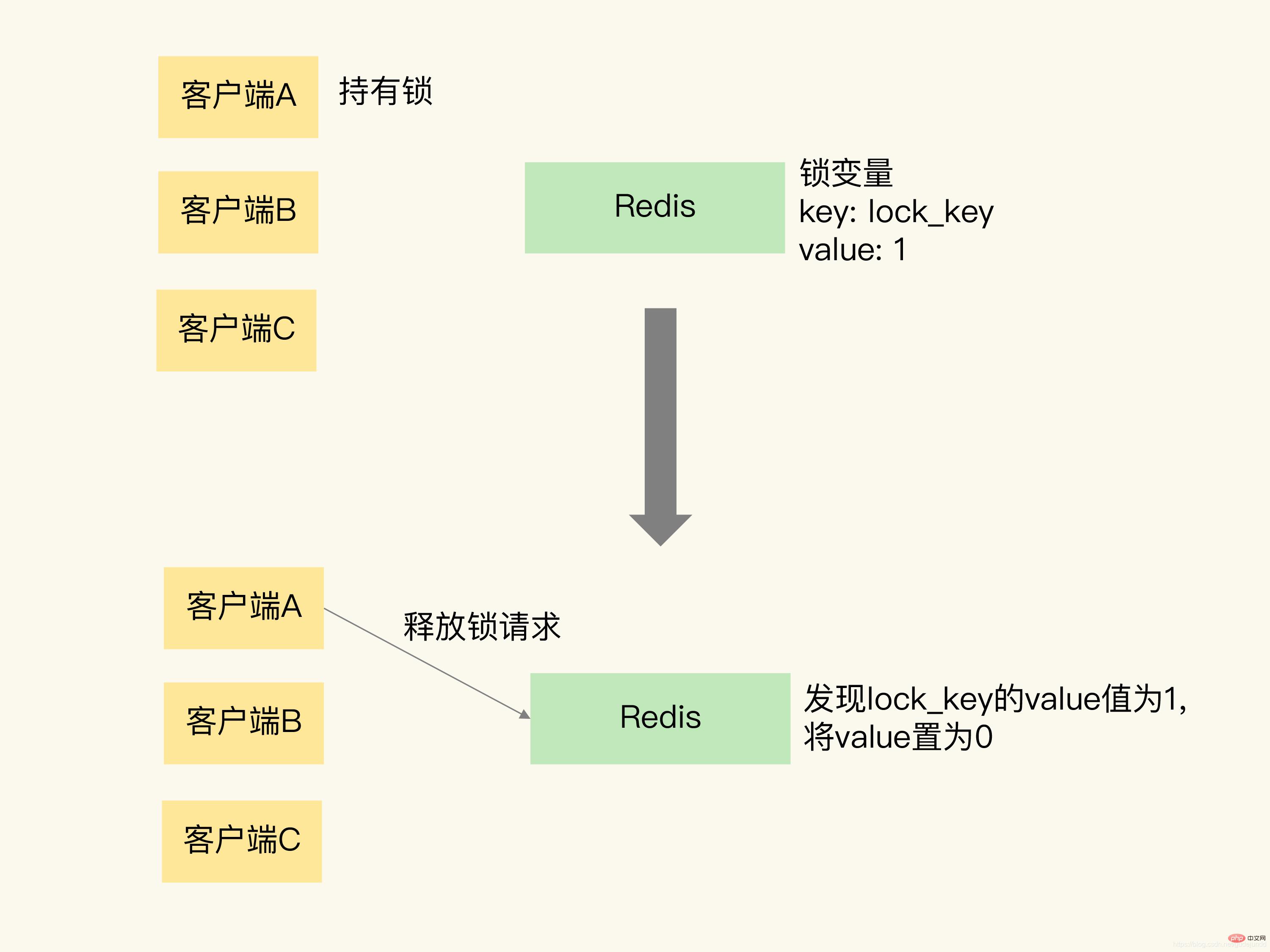
因为加锁包含了三个操作(读取锁变量、判断锁变量值以及把锁变量值设置为 1),而这三个操作在执行时需要保证原子性。那怎么保证原子性呢?
要想保证操作的原子性,有两种通用的方法,分别是使用 Redis 的单命令操作和使用 Lua 脚本。那么,在分布式加锁场景下,该怎么应用这两个方法呢?
我们先来看下,Redis 可以用哪些单命令操作实现加锁操作。
首先是 SETNX 命令,它用于设置键值对的值。具体来说,就是这个命令在执行时会判断键值对是否存在,如果不存在,就设置键值对的值,如果存在,就不做任何设置。
举个例子,如果执行下面的命令时,key 不存在,那么 key 会被创建,并且值会被设置为 value;如果 key 已经存在,SETNX 不做任何赋值操作。
SETNX key value
对于释放锁操作来说,我们可以在执行完业务逻辑后,使用 DEL 命令删除锁变量。不过,你不用担心锁变量被删除后,其他客户端无法请求加锁了。因为 SETNX 命令在执行时,如果要设置的键值对(也就是锁变量)不存在,SETNX 命令会先创建键值对,然后设置它的值。所以,释放锁之后,再有客户端请求加锁时,SETNX 命令会创建保存锁变量的键值对,并设置锁变量的值,完成加锁。
总结来说,我们就可以用 SETNX 和 DEL 命令组合来实现加锁和释放锁操作。下面的伪代码示例显示了锁操作的过程,你可以看下。
// 加锁 SETNX lock_key 1 // 业务逻辑 DO THINGS // 释放锁 DEL lock_key
不过,使用 SETNX 和 DEL 命令组合实现分布锁,存在两个潜在的风险。
第一个风险是,假如某个客户端在执行了 SETNX 命令、加锁之后,紧接着却在操作共享数据时发生了异常,结果一直没有执行最后的 DEL 命令释放锁。因此,锁就一直被这个客户端持有,其它客户端无法拿到锁,也无法访问共享数据和执行后续操作,这会给业务应用带来影响。
针对这个问题,一个有效的解决方法是,给锁变量设置一个过期时间。这样一来,即使持有锁的客户端发生了异常,无法主动地释放锁,Redis 也会根据锁变量的过期时间,在锁变量过期后,把它删除。其它客户端在锁变量过期后,就可以重新请求加锁,这就不会出现无法加锁的问题了。
我们再来看第二个风险。如果客户端 A 执行了 SETNX 命令加锁后,假设客户端 B 执行了 DEL 命令释放锁,此时,客户端 A 的锁就被误释放了。如果客户端 C 正好也在申请加锁,就可以成功获得锁,进而开始操作共享数据。这样一来,客户端 A 和 C 同时在对共享数据进行操作,数据就会被修改错误,这也是业务层不能接受的。
为了应对这个问题,我们需要能区分来自不同客户端的锁操作,具体咋做呢?其实,我们可以在锁变量的值上想想办法。
在使用 SETNX 命令进行加锁的方法中,我们通过把锁变量值设置为 1 或 0,表示是否加锁成功。1 和 0 只有两种状态,无法表示究竟是哪个客户端进行的锁操作。所以,我们在加锁操作时,可以让每个客户端给锁变量设置一个唯一值,这里的唯一值就可以用来标识当前操作的客户端。在释放锁操作时,客户端需要判断,当前锁变量的值是否和自己的唯一标识相等,只有在相等的情况下,才能释放锁。这样一来,就不会出现误释放锁的问题了。
知道了解决方案,那么,在 Redis 中,具体是怎么实现的呢?我们再来了解下。
在查看具体的代码前,我要先带你学习下 Redis 的 SET 命令。
我们刚刚在说 SETNX 命令的时候提到,对于不存在的键值对,它会先创建再设置值(也就是“不存在即设置”),为了能达到和 SETNX 命令一样的效果,Redis 给 SET 命令提供了类似的选项 NX,用来实现“不存在即设置”。如果使用了 NX 选项,SET 命令只有在键值对不存在时,才会进行设置,否则不做赋值操作。此外,SET 命令在执行时还可以带上 EX 或 PX 选项,用来设置键值对的过期时间。
举个例子,执行下面的命令时,只有 key 不存在时,SET 才会创建 key,并对 key 进行赋值。另外,key 的存活时间由 seconds 或者 milliseconds 选项值来决定。
SET key value [EX seconds | PX milliseconds] [NX]
有了 SET 命令的 NX 和 EX/PX 选项后,我们就可以用下面的命令来实现加锁操作了。
// 加锁, unique_value作为客户端唯一性的标识
SET lock_key unique_value NX PX 10000
其中,unique_value 是客户端的唯一标识,可以用一个随机生成的字符串来表示,PX 10000 则表示 lock_key 会在 10s 后过期,以免客户端在这期间发生异常而无法释放锁。
因为在加锁操作中,每个客户端都使用了一个唯一标识,所以在释放锁操作时,我们需要判断锁变量的值,是否等于执行释放锁操作的客户端的唯一标识,如下所示:
//释放锁 比较unique_value是否相等,避免误释放
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
这是使用 Lua 脚本(unlock.script)实现的释放锁操作的伪代码,其中,KEYS[1]表示 lock_key,ARGV[1]是当前客户端的唯一标识,这两个值都是我们在执行 Lua 脚本时作为参数传入的。
最后,我们执行下面的命令,就可以完成锁释放操作了。
redis-cli --eval unlock.script lock_key , unique_value
你可能也注意到了,在释放锁操作中,我们使用了 Lua 脚本,这是因为,释放锁操作的逻辑也包含了读取锁变量、判断值、删除锁变量的多个操作,而 Redis 在执行 Lua 脚本时,可以以原子性的方式执行,从而保证了锁释放操作的原子性。
好了,到这里,你了解了如何使用 SET 命令和 Lua 脚本在 Redis 单节点上实现分布式锁。但是,我们现在只用了一个 Redis 实例来保存锁变量,如果这个 Redis 实例发生故障宕机了,那么锁变量就没有了。此时,客户端也无法进行锁操作了,这就会影响到业务的正常执行。所以,我们在实现分布式锁时,还需要保证锁的可靠性。那怎么提高呢?这就要提到基于多个 Redis 节点实现分布式锁的方式了。
基于多个 Redis 节点实现高可靠的分布式锁
当我们要实现高可靠的分布式锁时,就不能只依赖单个的命令操作了,我们需要按照一定的步骤和规则进行加解锁操作,否则,就可能会出现锁无法工作的情况。“一定的步骤和规则”是指啥呢?其实就是分布式锁的算法。
为了避免 Redis 实例故障而导致的锁无法工作的问题,Redis 的开发者 Antirez 提出了分布式锁算法 Redlock。
Redlock 算法的基本思路,是让客户端和多个独立的 Redis 实例依次请求加锁,如果客户端能够和半数以上的实例成功地完成加锁操作,那么我们就认为,客户端成功地获得分布式锁了,否则加锁失败。这样一来,即使有单个 Redis 实例发生故障,因为锁变量在其它实例上也有保存,所以,客户端仍然可以正常地进行锁操作,锁变量并不会丢失。
我们来具体看下 Redlock 算法的执行步骤。Redlock 算法的实现需要有 N 个独立的 Redis 实例。接下来,我们可以分成 3 步来完成加锁操作。
第一步是,客户端获取当前时间。
第二步是,客户端按顺序依次向 N 个 Redis 实例执行加锁操作。
这里的加锁操作和在单实例上执行的加锁操作一样,使用 SET 命令,带上 NX,EX/PX 选项,以及带上客户端的唯一标识。当然,如果某个 Redis 实例发生故障了,为了保证在这种情况下,Redlock 算法能够继续运行,我们需要给加锁操作设置一个超时时间。
如果客户端在和一个 Redis 实例请求加锁时,一直到超时都没有成功,那么此时,客户端会和下一个 Redis 实例继续请求加锁。加锁操作的超时时间需要远远地小于锁的有效时间,一般也就是设置为几十毫秒。
第三步是,一旦客户端完成了和所有 Redis 实例的加锁操作,客户端就要计算整个加锁过程的总耗时。
客户端只有在满足下面的这两个条件时,才能认为是加锁成功。
- 条件一:客户端从超过半数(大于等于 N/2+1)的 Redis 实例上成功获取到了锁;
- 条件二:客户端获取锁的总耗时没有超过锁的有效时间。
在满足了这两个条件后,我们需要重新计算这把锁的有效时间,计算的结果是锁的最初有效时间减去客户端为获取锁的总耗时。如果锁的有效时间已经来不及完成共享数据的操作了,我们可以释放锁,以免出现还没完成数据操作,锁就过期了的情况。
当然,如果客户端在和所有实例执行完加锁操作后,没能同时满足这两个条件,那么,客户端向所有 Redis 节点发起释放锁的操作。
在 Redlock 演算法中,釋放鎖的操作和在單一實例上釋放鎖的操作一樣,只要執行釋放鎖的 Lua 腳本就可以了。這樣一來,只要 N 個 Redis 實例中的半數以上實例能正常運作,就能保證分散式鎖的正常運作了。
所以,在實際的業務應用中,如果你想要提升分散式鎖定的可靠性,就可以透過 Redlock 演算法來實現。
推薦學習:Redis學習教學
以上是一起來聊聊如何使用Redis實現分散式鎖的詳細內容。更多資訊請關注PHP中文網其他相關文章!