
一文搞懂MySQL索引所有知識點(建議收藏)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2021-12-20 14:25:112056瀏覽
這篇文章為大家帶來了mysql資料庫中索引的相關知識,其中幾乎包含了索引的全部知識點,希望對大家有幫助。

Mysql索引
索引介紹
#索引是什麼
官方介紹索引是幫助MySQL有效率地取得資料的資料結構。更通俗的說,資料庫索引好比是一本書前面的目錄,能加快資料庫的查詢速度。
一般來說索引本身也很大,不可能全部儲存在記憶體中,因此索引往往是儲存在磁碟上的檔案中的(可能存儲在單獨的索引檔案中,也可能和資料一起儲存在資料檔案中)。
我們通常所說的索引,包括聚集索引、覆蓋索引、組合索引、前綴索引、唯一索引等,沒有特別說明,預設都是使用B 樹結構組織(多路搜尋樹,不一定是二元的)的索引。
索引的優點和缺點
優點:
##可以提高資料檢索的效率,降低資料庫的IO成本,類似書的目錄。
- 透過
索引列對資料進行排序,降低資料排序的成本,降低了CPU的消耗。
- 被索引的欄位會自動進行排序,包括【單列索引】和【組合索引】,只是組合索引的排序比較複雜一些。
- 如果按照索引列的順序進行排序,對應order by語句來說,效率就會提高很多。
劣勢:
#索引會佔據磁碟空間
索引雖然會提高查詢效率,但是會降低更新表的效率。例如每次對錶進行增刪改操作,MySQL不僅要保存數據,還有保存或更新對應的索引檔。
- 單一列索引
- 組合索引#組合索引的使用,需要遵循
最左前綴匹配原則(最左匹配原則)。一般情況下在條件允許的情況下使用組合索引取代多個單列索引使用。
顯然這種並不適合作為經常需要查找和範圍查找的資料庫索引使用。
二元找樹二元樹,我想大家都會在心裡有個圖。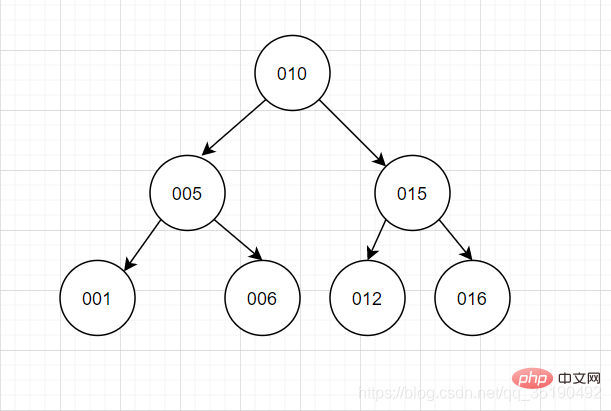
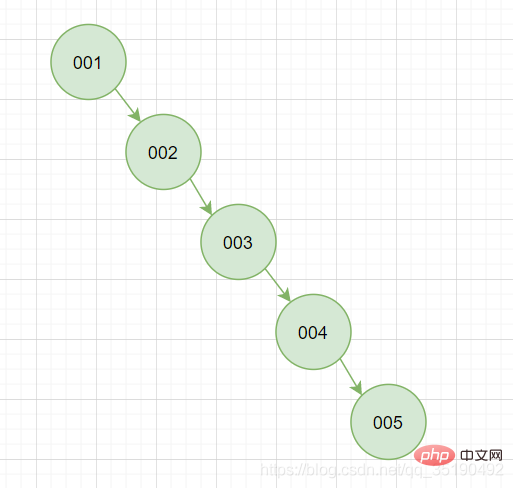
顯然這種情況不穩定的我們再選擇設計上必然會避免這種情況的
平衡二元樹平衡二元樹是採用二分法思維,平衡二元查找樹除了具備二元樹的特點,最主要的特徵是樹的左右兩個子樹的層級最多相差1。在插入刪除資料時透過左旋/右旋操作保持二元樹的平衡,不會出現左子樹很高、右子樹很矮的情況。使用平衡二元查找樹查詢的效能接近二分查找法,時間複雜度是 O(log2n)。查詢id=6,只需要兩次IO。
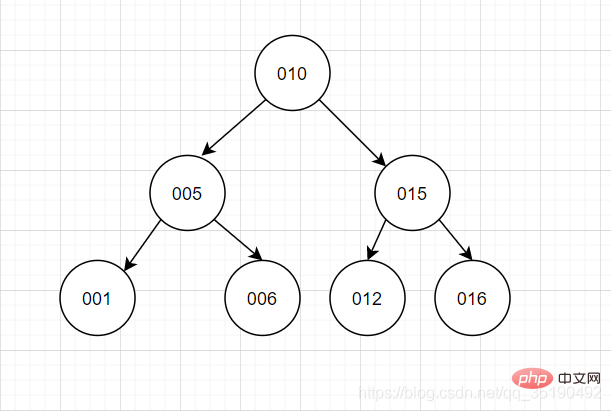
就這個特點來看,可能各位會覺得這樣就很好,可以達到二元樹的理想的情況了。然而依然存在一些問題:
時間複雜度和樹高相關。樹有多高就需要檢索多少次,每個節點的讀取,都對應一次磁碟 IO 操作。樹的高度等於每次查詢資料時磁碟 IO 操作的次數。磁碟每次尋道時間為10ms,在表格資料量大時,查詢效能就會很差。 (1百萬的資料量,log2n約等於20次磁碟IO,時間20*10=0.2s)
平衡二叉樹不支援範圍查詢快速查找,範圍查詢時需要從根節點多次遍歷,查詢效率不高。
B樹:改造二元樹
MySQL的資料是儲存在磁碟檔案中的,當查詢處理資料時,需要先將磁碟中的資料載入記憶體中,磁碟IO 操作非常耗時,所以我們優化的重點就是盡量減少磁碟IO 操作。存取二元樹的每個節點就會發生一次IO,如果想要減少磁碟IO操作,就需要盡量降低樹的高度。那要如何降低樹的高度呢?
假如key為bigint=8字節,每個節點有兩個指針,每個指針為4個字節,一個節點佔用的空間16個字節(8 4*2=16)。
因為在MySQL的InnoDB儲存引擎一次IO會讀取的一頁(預設一頁16K)的資料量,而二元樹一次IO有效資料量只有16字節,空間利用率極低。為了最大化利用一次IO空間,一個簡單的想法是在每個節點中儲存多個元素,在每個節點盡可能多的儲存資料。每個節點可以儲存1000個索引(16k/16=1000),這樣就將二元樹改造成了多叉樹,透過增加樹的叉樹,將樹從高瘦變為矮胖。建構1百萬個數據,樹的高度只需要2層就可以(1000*1000=1百萬),也就是說只需要2次磁碟IO就可以查詢到數據。磁碟IO次數變少了,查詢資料的效率也提高了。
這種資料結構我們稱為B樹,B樹是一種多叉平衡查找樹,如下圖主要特點:
B樹的節點中存儲著多個元素,每個內節點有多個分叉。
節點中的元素包含鍵值和數據,節點中的鍵值從大到小排列。也就是說,在所有的節點都儲存資料。
父節點當中的元素不會出現在子節點中。
所有的葉子結點都位於同一層,葉節點具有相同的深度,葉節點之間沒有指標連接。
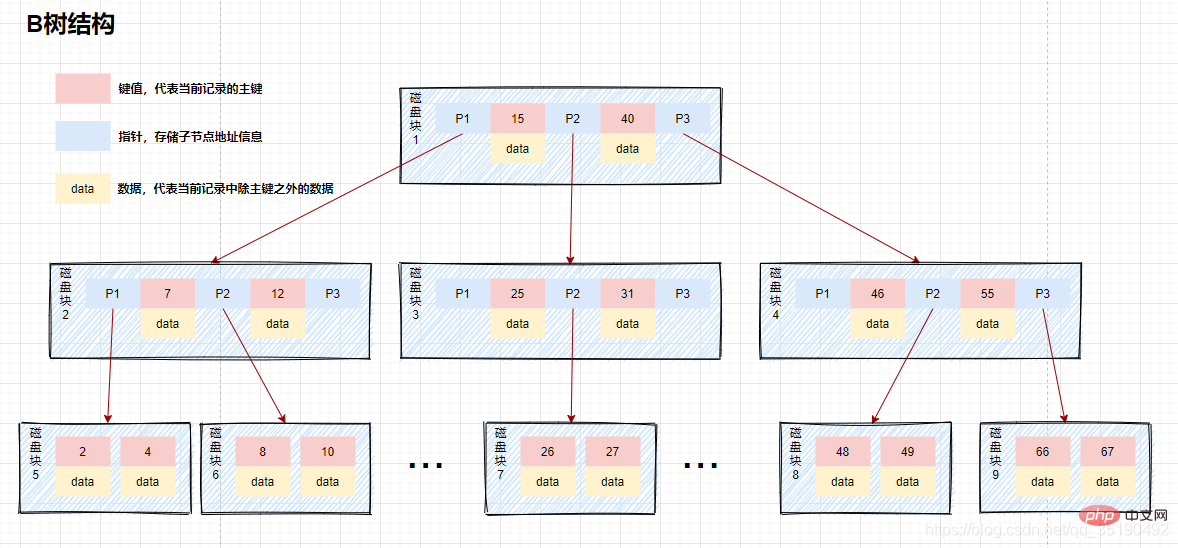
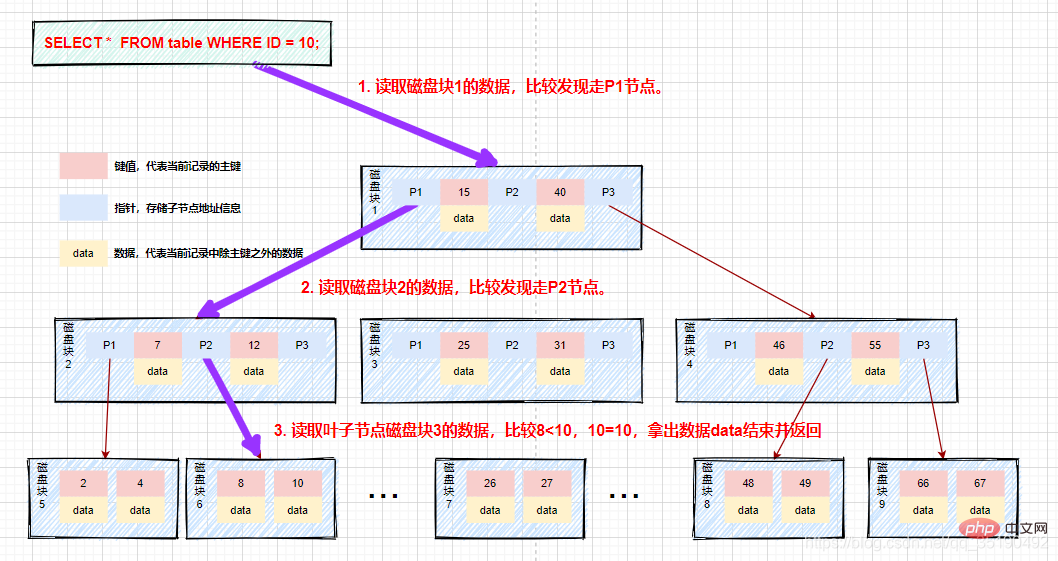
舉個例子,在b樹中查詢資料的情況:
假如我們查詢值等於10的數據。查詢路徑磁碟區塊1->磁碟區塊2->磁碟區塊5。
第一次磁碟IO:將磁碟區塊1載入到記憶體中,在記憶體中從頭遍歷比較,10
第二次磁碟IO:將磁碟區塊2載入到記憶體中,在記憶體中從頭遍歷比較,7
第三次磁碟IO:將磁碟區塊5載入到記憶體中,在記憶體中從頭遍歷比較,10=10,找到10,取出data,如果data儲存的行記錄,取出data,查詢結束。如果儲存的是磁碟位址,還需要根據磁碟位址到磁碟中取出數據,查詢終止。
相比二元平衡查找樹,在整個查找過程中,雖然資料的比較次數並沒有明顯減少,但是磁碟IO次數會大大減少。同時,由於我們的比較是在記憶體中進行的,比較的耗時可以忽略不計。 B樹的高度一般2至3層就能滿足大部分的應用場景,所以使用B樹建立索引可以很好的提升查詢的效率。
流程如圖:
看到這裡一定覺得B樹就很理想了,但前輩們會告訴你依然存在可以優化的地方:
B樹不支援範圍查詢的快速查找,你想想這麼一個情況如果我們想要查找10和35之間的數據,查找到15之後,需要回到根節點重新遍歷查找,需要從根節點進行多次遍歷,查詢效率有待提升。
如果data儲存的是行記錄,行的大小隨著列數的增多,所佔空間會變大。這時,一個頁中可儲存的資料量就會變少,樹對應就會變高,磁碟IO次數就會變大。
B 樹:改造B樹
B 樹,作為B樹的升級版,在B樹基礎上,MySQL在B樹的基礎上繼續改造,使用B 樹建立索引。 B 樹和B樹最主要的差異在於非葉子節點是否儲存資料的問題
- #B樹:非葉子節點和葉子節點都會儲存資料。
- B 樹:只有葉子節點才會儲存數據,非葉子節點至儲存鍵值。葉子節點之間使用雙向指標連接,最底層的葉子節點形成了一個雙向有序鍊錶。
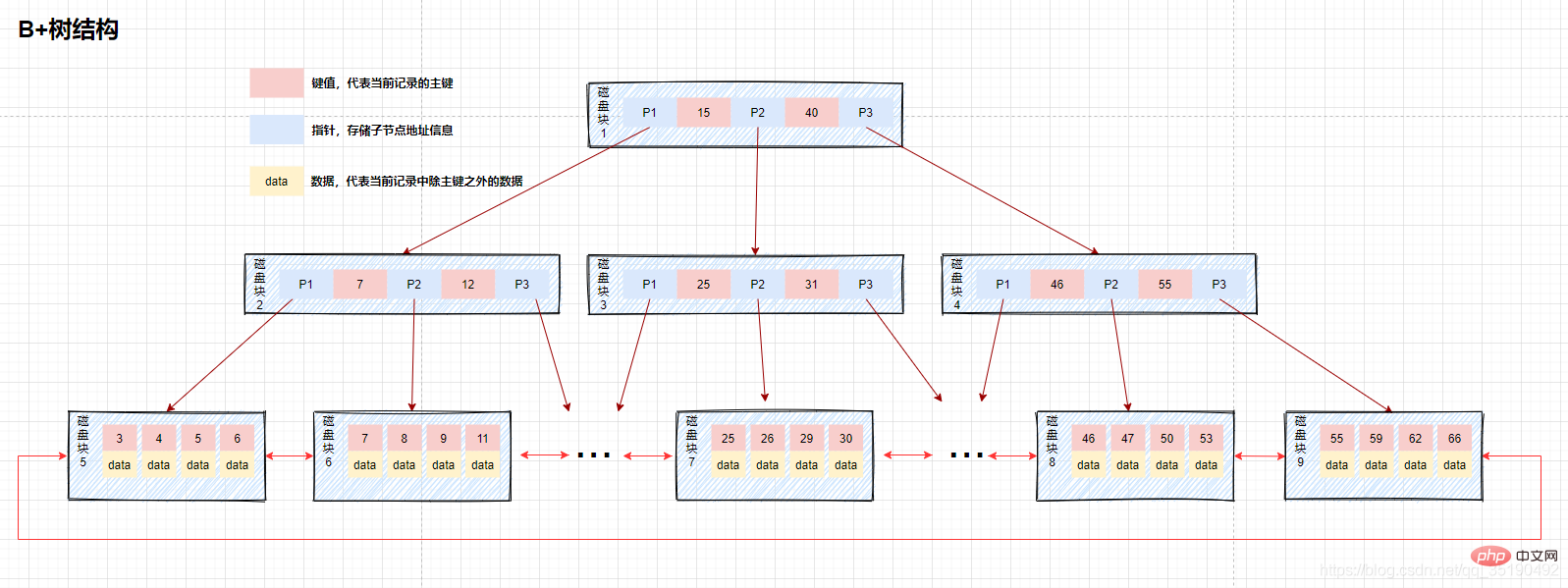
B 樹的最底層葉子節點包含了所有的索引項目。從圖上可以看到,B 樹在查找資料的時候,由於資料都存放在最底層的葉子節點上,所以每次查找都需要檢索到葉子節點才能查詢到資料。所以在需要查詢資料的情況下每次的磁碟的IO跟樹高有直接的關係,但是從另一方面來說,由於資料都被放到了葉子節點,所以放索引的磁碟區塊鎖存放的索引數量是會跟著這增加的,所以相對於B樹來說,B 樹的樹高理論上情況下是比B樹矮的。也存在索引覆蓋查詢的情況,在索引中數據滿足了當前查詢語句所需的全部數據,此時只需要找到索引即可立刻返回,不需要檢索到最底層的葉子節點。
舉例:
- 等值查詢:
假如我們查詢值等於9的數據。查詢路徑磁碟區塊1->磁碟區塊2->磁碟區塊6。
##流程如圖:
第一次磁碟IO:將磁碟區塊1載入到記憶體中,在記憶體中從頭遍歷比較,9
第二次磁碟IO:將磁碟區塊2載入到記憶體中,在記憶體中從頭遍歷比較,7
第三次磁碟IO:將磁碟區塊6載入到記憶體中,在記憶體中從頭遍歷比較,在第三個索引中找到9,取出data,如果data儲存的行記錄,取出data,查詢結束。如果儲存的是磁碟位址,還需要根據磁碟位址到磁碟中取出數據,查詢終止。 (這裡需要區分的是在InnoDB中Data儲存的為行數據,而MyIsam中儲存的是磁碟位址。)
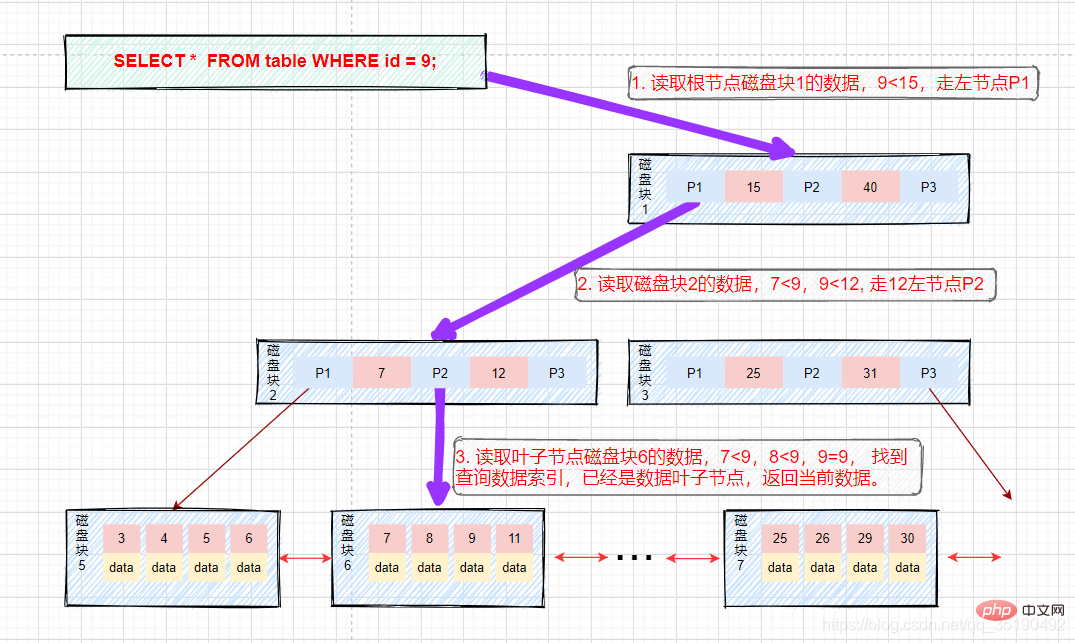
可以看到B 樹可以保證等值和範圍查詢的快速查找,MySQL的索引就採用了B樹的資料結構。##範圍查詢:
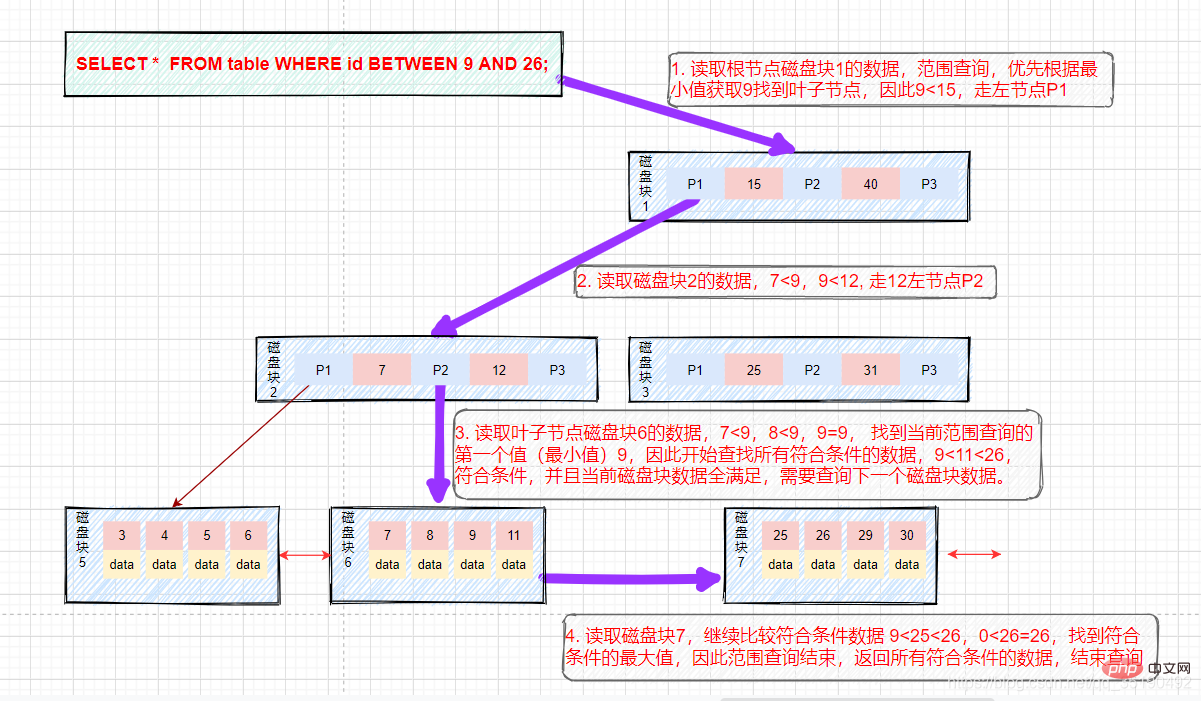
- #假如我們想要尋找9和26之間的資料。查找路徑是磁碟區塊1->磁碟區塊2->磁碟區塊6->磁碟區塊7。
先找出值等於9的數據,將值等於9的數據快取到結果集。這一步和前面等值查詢流程一樣,發生了三次磁碟IO。
- 查找到15之後,底層的葉子節點是一個有序列表,我們從磁碟區塊6,鍵值9開始向後遍歷篩選所有符合篩選條件的資料。
- 第四次磁碟IO:根據磁碟6後繼指標到磁碟中尋址定位到磁碟區塊7,將磁碟7載入到記憶體中,在記憶體中從頭遍歷比較,9< ;25主鍵具備唯一性(後面不會有
Mysql的索引實作
介紹了索引資料結構,那肯定是要帶入到Mysql裡面看看真實的使用場景的,所以這裡分析Mysql的兩種存儲引擎的索引實作:
MyISAM索引和InnoDB索引#MyIsam索引
以簡單的user表為例。 user表存在兩個索引,id列為主鍵索引,age列為普通索引
CREATE TABLE `user`( `id` int(11) NOT NULL AUTO_INCREMENT, `username` varchar(20) DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE, KEY `idx_age` (`age`) USING BTREE) ENGINE = MyISAM AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8;
 #MyISAM的資料檔案和索引檔案是分開儲存的。 MyISAM使用B 樹建立索引樹時,葉子節點中儲存的鍵值為索引列的值,資料為索引所在行的磁碟位址。
#MyISAM的資料檔案和索引檔案是分開儲存的。 MyISAM使用B 樹建立索引樹時,葉子節點中儲存的鍵值為索引列的值,資料為索引所在行的磁碟位址。
主鍵索引
 表user的索引儲存在索引檔案
表user的索引儲存在索引檔案
中,資料檔案儲存在資料檔案user.MYD中。 簡單分析下查詢時的磁碟IO情況:
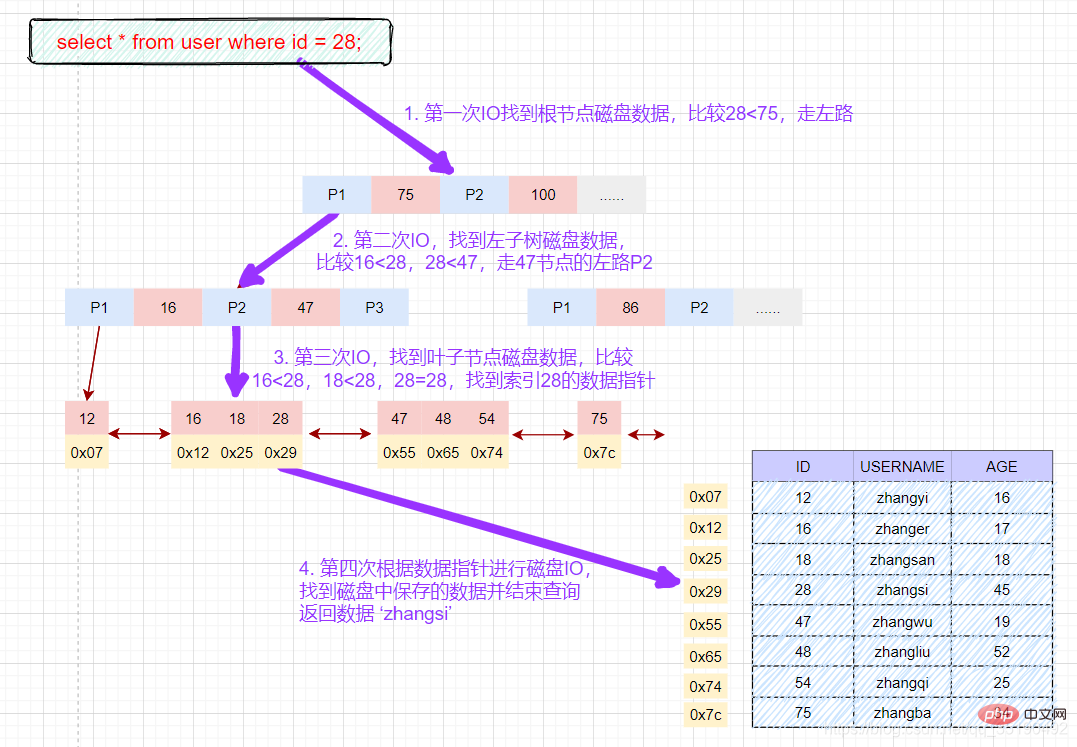
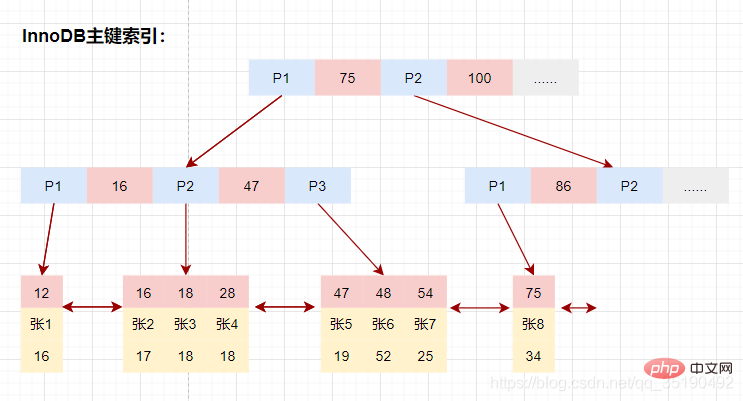
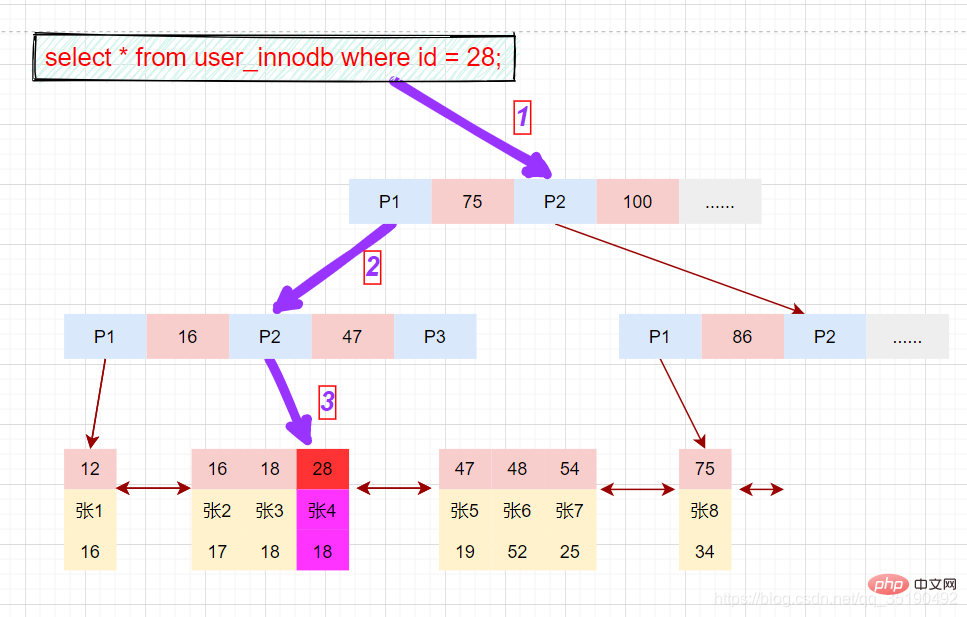
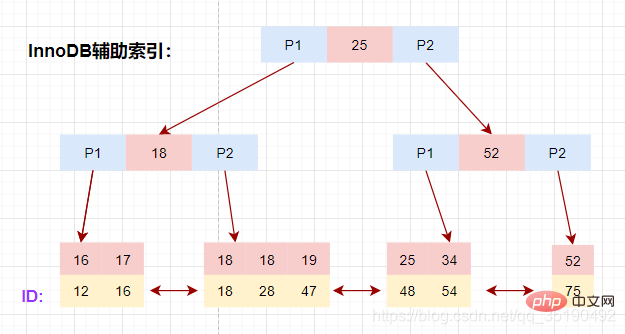
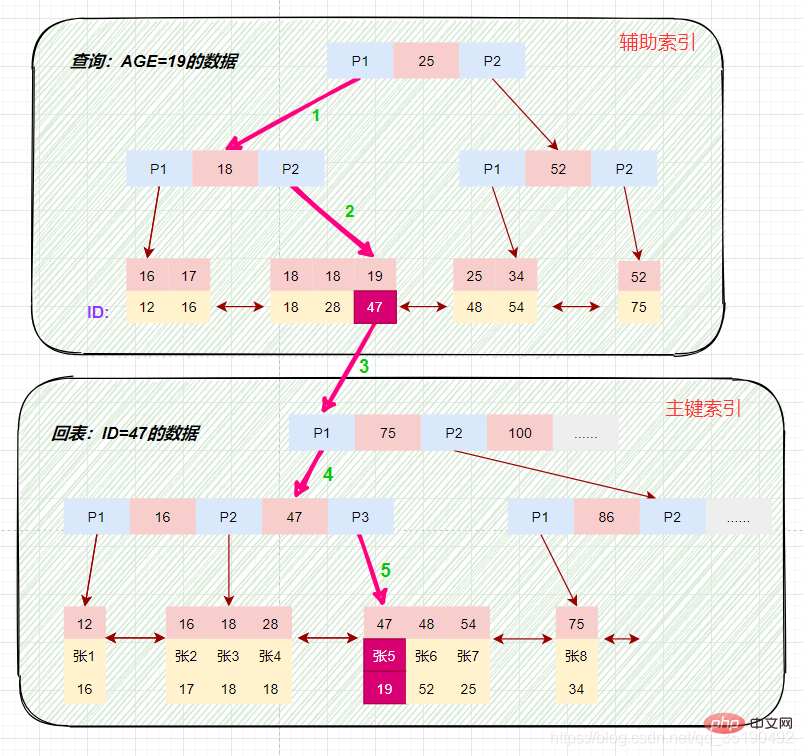
磁盘IO次数:3次索引检索+记录数据检索。 根据主键范围查询数据: 先在主键树中从根节点开始检索,将根节点加载到内存,比较28 将左子树节点加载到内存中,比较16 检索到叶节点,将节点加载到内存中遍历比较16 根据磁盘地址从数据文件中获取行记录缓存到结果集中。(1次磁盘IO) 我们的查询语句时范围查找,需要向后遍历底层叶子链表,直至到达最后一个不满足筛选条件。 向后遍历底层叶子链表,将下一个节点加载到内存中,遍历比较,28 最后得到两条符合筛选条件,将查询结果集返给客户端。 磁盘IO次数:4次索引检索+记录数据检索。 **备注:**以上分析仅供参考,MyISAM在查询时,会将索引节点缓存在MySQL缓存中,而数据缓存依赖于操作系统自身的缓存,所以并不是每次都是走的磁盘,这里只是为了分析索引的使用过程。 在 MyISAM 中,辅助索引和主键索引的结构是一样的,没有任何区别,叶子节点的数据存储的都是行记录的磁盘地址。只是主键索引的键值是唯一的,而辅助索引的键值可以重复。 查询数据时,由于辅助索引的键值不唯一,可能存在多个拥有相同的记录,所以即使是等值查询,也需要按照范围查询的方式在辅助索引树中检索数据。 每个InnoDB表都有一个聚簇索引 ,聚簇索引使用B+树构建,叶子节点存储的数据是整行记录。一般情况下,聚簇索引等同于主键索引,当一个表没有创建主键索引时,InnoDB会自动创建一个ROWID字段来构建聚簇索引。InnoDB创建索引的具体规则如下: 除聚簇索引之外的所有索引都称为辅助索引。在中InnoDB,辅助索引中的叶子节点存储的数据是该行的主键值都。 在检索时,InnoDB使用此主键值在聚簇索引中搜索行记录。 这里以user_innodb为例,user_innodb的id列为主键,age列为普通索引。 InnoDB的数据和索引存储在一个文件t_user_innodb.ibd中。InnoDB的数据组织方式,是聚簇索引。 主键索引的叶子节点会存储数据行,辅助索引只会存储主键值。 等值查询数据: 先在主键树中从根节点开始检索,将根节点加载到内存,比较28 将左子树节点加载到内存中,比较16 检索到叶节点,将节点加载到内存中遍历,比较16 磁盘IO数量:3次。 除聚簇索引之外的所有索引都称为辅助索引,InnoDB的辅助索引只会存储主键值而非磁盘地址。 以表user_innodb的age列为例,age索引的索引结果如下图。 底层叶子节点的按照(age,id)的顺序排序,先按照age列从小到大排序,age列相同时按照id列从小到大排序。 使用辅助索引需要检索两遍索引:首先检索辅助索引获得主键,然后使用主键到主索引中检索获得记录。 画图分析等值查询的情况: 根据在辅助索引树中获取的主键id,到主键索引树检索数据的过程称为回表查询。 磁盘IO数:辅助索引3次+获取记录回表3次 还是以自己创建的一个表为例:表 abc_innodb,id为主键索引,创建了一个联合索引idx_abc(a,b,c)。 组合索引的数据结构: 组合索引的查询过程: 最左匹配原则: 最左前缀匹配原则和联合索引的索引存储结构和检索方式是有关系的。 在组合索引树中,最底层的叶子节点按照第一列a列从左到右递增排列,但是b列和c列是无序的,b列只有在a列值相等的情况下小范围内递增有序,而c列只能在a,b两列相等的情况下小范围内递增有序。 就像上面的查询,B+树会先比较a列来确定下一步应该搜索的方向,往左还是往右。如果a列相同再比较b列。但是如果查询条件没有a列,B+树就不知道第一步应该从哪个节点查起。 可以说创建的idx_abc(a,b,c)索引,相当于创建了(a)、(a,b)(a,b,c)三个索引。、 组合索引的最左前缀匹配原则:使用组合索引查询时,mysql会一直向右匹配直至遇到范围查询(>、 覆盖索引并不是说是索引结构,覆盖索引是一种很常用的优化手段。因为在使用辅助索引的时候,我们只可以拿到主键值,相当于获取数据还需要再根据主键查询主键索引再获取到数据。但是试想下这么一种情况,在上面abc_innodb表中的组合索引查询时,如果我只需要abc字段的,那是不是意味着我们查询到组合索引的叶子节点就可以直接返回了,而不需要回表。这种情况就是覆盖索引。 可以看一下执行计划: 覆盖索引的情况: 未使用到覆盖索引: 看到这里,你是不是对于自己的sql语句里面的索引的有了更多优化想法呢。比如: 在InnoDB的存储引擎中,使用辅助索引查询的时候,因为辅助索引叶子节点保存的数据不是当前记录的数据而是当前记录的主键索引,索引如果需要获取当前记录完整数据就必然需要根据主键值从主键索引继续查询。这个过程我们成位回表。想想回表必然是会消耗性能影响性能。那如何避免呢? 使用索引覆盖,举个例子:现有User表(id(PK),name(key),sex,address,hobby…) 如果在一個場景下, 這裡就是一個典型的使用覆蓋索引的最佳化策略減少回表的情況。 聯合索引,在建立索引的時候,盡量在多個單列索引上判斷下是否可以使用聯合索引。聯合索引的使用不僅可以節省空間,還可以更容易的使用到索引覆蓋。試想一下,索引的欄位越多,是不是更容易滿足查詢需要傳回的資料呢。例如聯合索引(a_b_c),是不是等於有了索引:a,a_b,a_b_c三個索引,這樣是不是節省了空間,當然節省的空間並不是三倍於(a,a_b,a_b_c)三個索引,因為索引樹的資料沒變,但是索引data欄位的資料確實真實的節省了。 聯合索引的創建原則,在創建聯合索引的時候因該把頻繁使用的列、區分度高的列放在前面,頻繁使用代表索引利用率高,區分度高代表篩選粒度大,這些都是在索引創建的需要考慮到的優化場景,也可以在常需要作為查詢返回的字段上增加到聯合索引中,如果在聯合索引上增加一個字段而使用到了覆蓋索引,那我建議這種情況下使用聯合索引。 聯合索引的使用 目前索引存在頻繁使用作為傳回欄位的資料列,這個時候就可以考慮目前列是否可以加入到目前已經存在索引上,使其查詢語句可以使用到覆寫索引。 【推薦:mysql影片教學】select * from user where id = 28;
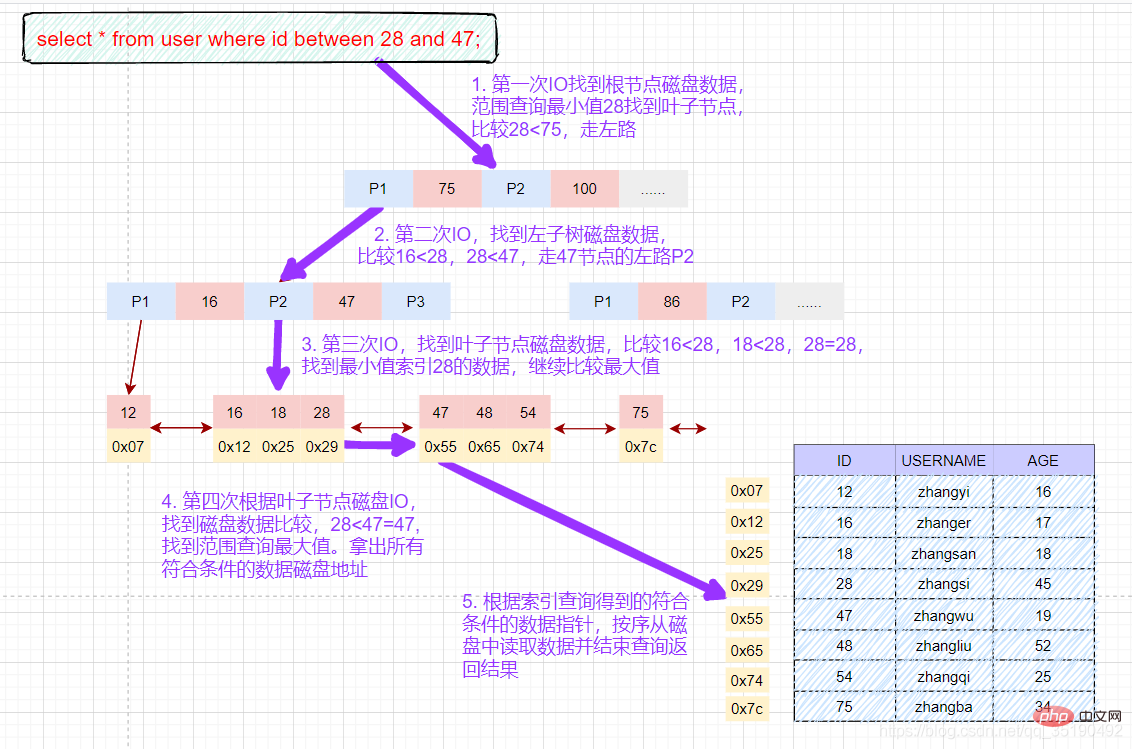
select * from user where id between 28 and 47;
辅助索引
InnoDB索引
主键索引(聚簇索引)
CREATE TABLE `user_innodb`(
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(20) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
KEY `idx_age` (`age`) USING BTREE) ENGINE = InnoDB;
select * from user_innodb where id = 28;
辅助索引
select * from t_user_innodb where age=19;
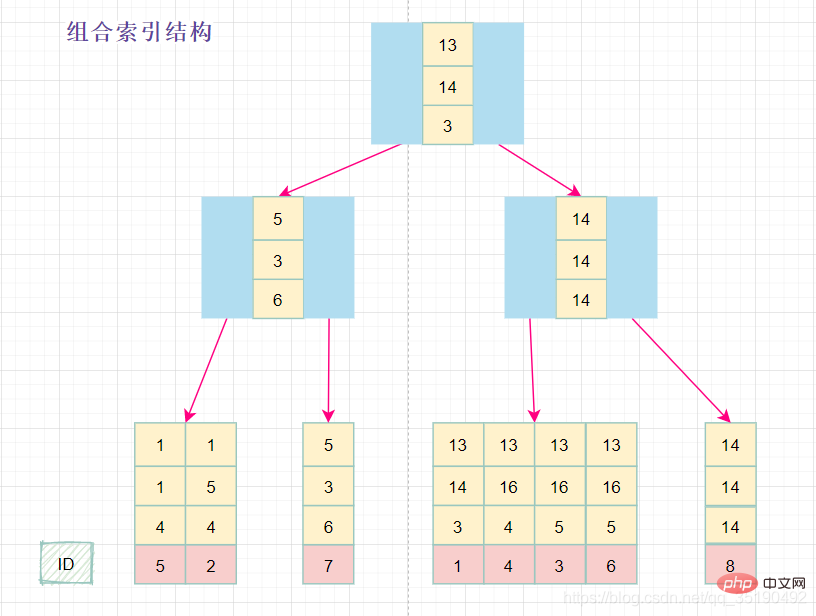
组合索引
CREATE TABLE `abc_innodb`(
`id` int(11) NOT NULL AUTO_INCREMENT,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
`c` varchar(10) DEFAULT NULL,
`d` varchar(10) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
KEY `idx_abc` (`a`, `b`, `c`)) ENGINE = InnoDB;
select * from abc_innodb order by a, b, c, id;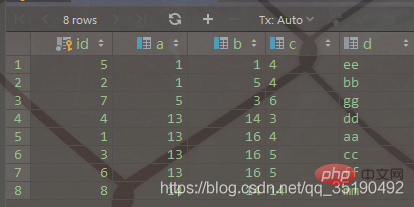
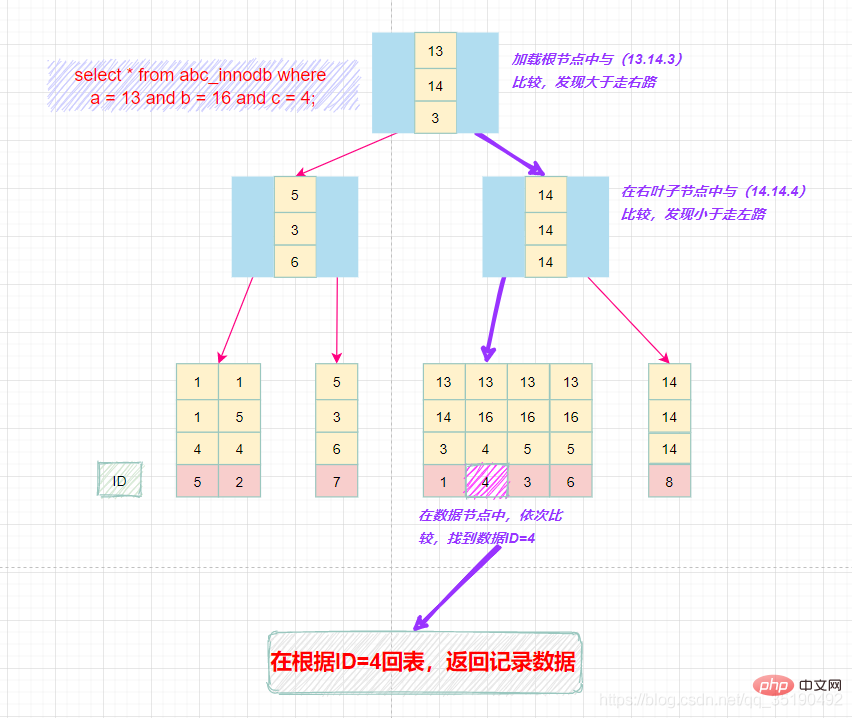
select * from abc_innodb where a = 13 and b = 16 and c = 4;
覆盖索引


总结
避免回表
select id,name,sex from user where name ='zhangsan';這個語句在業務上頻繁使用到,而user表的其他欄位使用頻率遠低於它,在這種情況下,如果我們在建立name 欄位的索引的時候,不是使用單一索引,而是使用聯合索引(name,sex)這樣的話再執行這個查詢語句是不是根據輔助索引查詢到的結果就可以獲得當前語句的完整資料。這樣就可以有效地避免了回表再取得sex的資料。 聯合索引的使用
以上是一文搞懂MySQL索引所有知識點(建議收藏)的詳細內容。更多資訊請關注PHP中文網其他相關文章!