
介紹python 資料抓取三種方法

- coldplay.xixi轉載
- 2021-02-13 10:30:074733瀏覽

#免費學習推薦:python影片教學
三種資料抓取的方法
- 正則表達式(re庫)
- BeautifulSoup(bs4)
- lxml
*利用先前建構的下載網頁函數,取得目標網頁的html,我們以https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/為例,取得html。
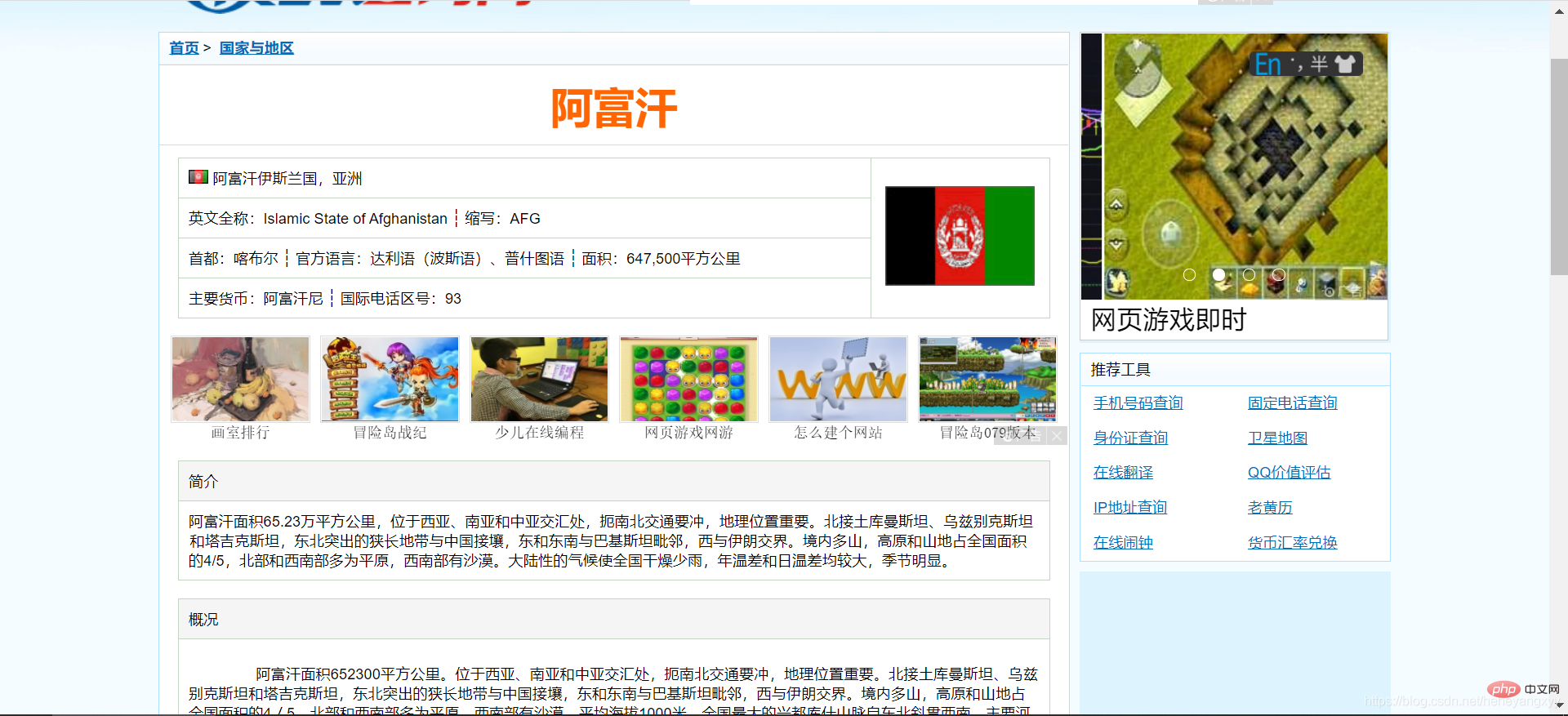
from get_html import download url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'page_content = download(url)
*假設我們需要爬取該網頁中的國家名稱和概況,我們依序使用這三種資料抓取的方法來實現資料抓取。
1.正規表示式
from get_html import downloadimport re
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'page_content = download(url)country = re.findall('class="h2dabiaoti">(.*?)', page_content) #注意返回的是listsurvey_data = re.findall('<tr><td>(.*?)</td></tr>', page_content)survey_info_list = re.findall('<p> (.*?)</p>', survey_data[0])survey_info = ''.join(survey_info_list)print(country[0],survey_info)
2.BeautifulSoup(bs4)
from get_html import downloadfrom bs4 import BeautifulSoup
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'html = download(url)#创建 beautifulsoup 对象soup = BeautifulSoup(html,"html.parser")#搜索country = soup.find(attrs={'class':'h2dabiaoti'}).text
survey_info = soup.find(attrs={'id':'wzneirong'}).textprint(country,survey_info)
3.lxml
from get_html import downloadfrom lxml import etree #解析树url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'page_content = download(url)selector = etree.HTML(page_content)#可进行xpath解析country_select = selector.xpath('//*[@id="main_content"]/h2') #返回列表for country in country_select:
print(country.text)survey_select = selector.xpath('//*[@id="wzneirong"]/p')for survey_content in survey_select:
print(survey_content.text,end='')
執行結果:
最後,引用《用python寫網路爬蟲》中三種方法的效能對比,如下圖:
僅供參考。
#相關免費學習推薦:python教學(影片)
以上是介紹python 資料抓取三種方法的詳細內容。更多資訊請關注PHP中文網其他相關文章!
陳述:
本文轉載於:csdn.net。如有侵權,請聯絡admin@php.cn刪除
上一篇:介紹Python的抖音快手字符舞下一篇:介紹Python的抖音快手字符舞