
多執行緒比單線線快,是真的嗎?

- coldplay.xixi轉載
- 2020-11-09 17:11:403398瀏覽
pyrhon影片教學欄位介紹多執行緒是否真的比單一執行緒快。

事實上,Python 多執行緒另一個很重要的話題叫,GIL(Global Interpreter Lock,即全域解釋器鎖定)。
多執行緒不一定比單執行緒快
在Python中,可以透過多行程、多執行緒和多協程來實現多任務。難道多執行緒一定比單線線快?
下面我用一段程式碼證明我自己得觀點。
'''
@Author: Runsen
@微信公众号: Python之王
@博客: https://blog.csdn.net/weixin_44510615
@Date: 2020/6/4
'''import threading, timedef my_counter():
i = 0
for _ in range(100000000):
i = i+1
return Truedef main1():
start_time = time.time() for tid in range(2):
t = threading.Thread(target=my_counter)
t.start()
t.join() # 第一次循环的时候join方法引起主线程阻塞,但第二个线程并没有启动,所以两个线程是顺序执行的
print("单线程顺序执行total_time: {}".format(time.time() - start_time))def main2():
thread_ary = {}
start_time = time.time() for tid in range(2):
t = threading.Thread(target=my_counter)
t.start()
thread_ary[tid] = t for i in range(2):
thread_ary[i].join() # 两个线程均已启动,所以两个线程是并发的
print("多线程执行total_time: {}".format(time.time() - start_time))if __name__ == "__main__":
main1()
main2()复制代码
運行結果
单线程顺序执行total_time: 17.754502773284912多线程执行total_time: 20.01178550720215复制代码
我怕你說我亂得出來得結果,我還是截張圖看清楚點

Pthread(全稱為POSIX Thread),而在Windows 系統裡是Windows Thread。另外,Python 的線程,也完全受作業系統管理,例如協調何時執行、管理記憶體資源、管理中斷等等。
任一時刻,無論線程多少,單一CPython 解釋器只能執行一條位元組碼。這個定義需要注意的點:
首先需要明確的一點是GIL並不是Python的特性,它是在實作Python解析器(CPython)時所引入的概念。
C 是一套語言(語法)標準,但可以用不同的編譯器來編譯成執行程式碼。有名的編譯器例如GCC,INTEL C ,Visual C 等。 Python也是一樣,同樣一段程式碼可以透過CPython,PyPy,Psyco等不同的Python執行環境來執行。其他 Python 解釋器不一定有 GIL。例如 Jython (JVM) 和 IronPython (CLR) 沒有 GIL,而 CPython,PyPy 有 GIL;
因為CPython是大部分環境下預設的Python執行環境。所以在很多人的概念裡CPython就是Python,也就想當然的把GIL歸結為Python語言的缺陷。所以這裡要先明確一點:GIL並不是Python的特性,Python完全可以不依賴GIL
GIL本質就是一把互斥鎖##GIL本質就是一把互斥鎖,既然是互斥鎖,所有互斥鎖的本質都一樣,都是將並發運行變成串行,以此來控制同一時間內共享資料只能被一個任務所修改,進而保證資料安全。
可以肯定的一點是:保護不同的資料的安全,就應該加上不同的鎖。
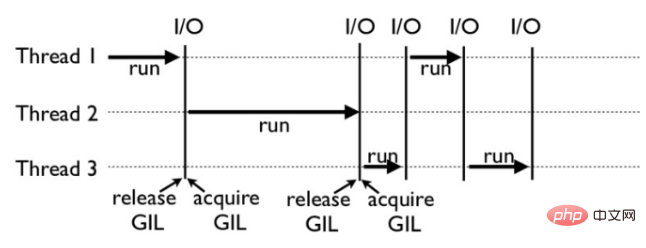
GIL 的工作原理:例如下面這張圖,就是一個 GIL 在 Python 程式的工作範例。其中,Thread 1、2、3 輪流執行,每一個執行緒在開始執行時,都會鎖住GIL,以阻止別的執行緒執行;同樣的,每一個執行緒執行完一段後,會釋放GIL,以允許別的線程開始利用資源。
 計算密集型
計算密集型
計算密集型任務的特性是要進行大量的運算,消耗CPU資源。
我們先來看一個簡單的計算密集型範例:
'''
@Author: Runsen
@微信公众号: Python之王
@博客: https://blog.csdn.net/weixin_44510615
@Date: 2020/6/4
'''import time
COUNT = 50_000_000def count_down():
global COUNT while COUNT > 0:
COUNT -= 1s = time.perf_counter()
count_down()
c = time.perf_counter() - s
print('time taken in seconds - >:', c)
time taken in seconds - >: 9.2957003复制代码
這個是單線程, 時間是9s, 下面我們用兩個線程看看結果又如何:
'''
@Author: Runsen
@微信公众号: Python之王
@博客: https://blog.csdn.net/weixin_44510615
@Date: 2020/6/4
'''import timefrom threading import Thread
COUNT = 50_000_000def count_down():
global COUNT while COUNT > 0:
COUNT -= 1s = time.perf_counter()
t1 = Thread(target=count_down)
t2 = Thread(target=count_down)
t1.start()
t2.start()
t1.join()
t2.join()
c = time.perf_counter() - s
print('time taken in seconds - >:', c)
time taken in seconds - >: 17.110625复制代码 我們程式主要的操作就是在計算, CPU沒有等待, 而改為多執行緒後, 增加了執行緒後, 在執行緒之間頻繁的切換,增大了時間開銷, 時間當然會增加了。
還有一種類型是IO密集型,涉及到網路、磁碟IO的任務都是IO密集型任務,這類任務的特點是CPU消耗很少,任務的大部分時間都在等待IO操作完成(因為IO的速度遠低於CPU和記憶體的速度)。對於IO密集型任務,任務越多,CPU效率越高,但也有一個限度。常見的任務大多是IO密集型任務,例如Web應用。
總結:對於io密集型工作(Python爬蟲),多執行緒可以大幅提高程式碼效率。對CPU運算密集(Python資料分析,機器學習,深度學習),多執行緒的效率可能比單執行緒還略低。所以,資料領域沒有多執行緒提高效率之說,只有將CPU提升到GPU,TPU來提升運算能力。相關免費學習推薦:
python影片教學
以上是多執行緒比單線線快,是真的嗎?的詳細內容。更多資訊請關注PHP中文網其他相關文章!