


理解關聯規則apriori演算法:Apriori演算法是第一個關聯規則挖掘演算法,也是最經典的演算法,它利用逐層搜尋的迭代方法找出資料庫中項集的關係,以形成規則,其過程由連接【類矩陣運算】與剪枝【去掉那些沒必要的中間結果】組成。

瞭解關聯規則apriori演算法:
一、概念
# #表1 某超市的交易資料庫
交易號碼TID |
顧客購買的商品 |
交易號碼TID |
#顧客購買的商品 |
T1 |
bread, cream, milk, tea |
#T6 |
bread, tea |
#T2 |
bread, cream, milk |
T7 |
beer, milk, tea |
T3 |
cake, milk |
#T8 |
bread, tea |
#T4 |
milk, tea |
T9 |
#bread, cream, milk, tea |
| #T5 |
bread, cake, milk |
T10 |
bread,milk , tea |
定義一:設I={i1,i2,…,im},是m個不同的項目的集合,每個ik稱為一個專案。項目的集合I稱為項集。其元素的個數稱為項集的長度,長度為k的項集稱為k-項集。引例中每個商品就是一個項目,項集為I={bread, beer, cake,cream, milk, tea},I的長度為6。
定義二:每筆#交易T是項集I的一個子集。對應每一個交易有一個唯一識別交易號,記作TID。交易全體構成了交易資料庫D,|D|等於D中交易的數量。引例中包含10筆交易,因此|D|=10。
定義三:對於項集X,設定count(X⊆T)為交易集D中包含X的交易的數量,則項集X的支持度為:
#support(X)=count(X⊆T)/|D|
引例中X={bread, milk}出現在T1,T2,T5,T9和T10中,所以支持度為0.5。
定義四:#最小支持度是項集的最小支援閥值,記為SUPmin,代表了使用者關心的關聯規則的最低重要性。 支持度不小於SUPmin 的項集稱為頻繁集合,長度為k的頻繁集合稱為k-頻繁集合。如果設定SUPmin為0.3,引例中{bread, milk}的支持度是0.5,所以是2-頻繁集。
定義五:#關聯規則是一個蘊含式:
R:X⇒Y
其中X⊂I,Y⊂I,且X∩Y=⌀。表示項集X在某一交易中出現,則導致Y以某一機率也會出現。使用者關心的關聯規則,可以用兩個標準來衡量:支持度和可信度。
定義六:關聯規則R的支援度##是交易集同時包含X和Y的交易數與|D|之比。即:
support(X⇒Y)=count(X⋃Y)/|D|支持度反映了X、Y同時出現的機率。關聯規則的支持度等於頻繁集的支持度。
定義七:對於關聯規則R,##可信度是指包含X和Y的交易數與包含X的交易數之比。即:confidence(X⇒Y)=support(X⇒Y)/support(X)
可信度反映瞭如果交易中包含X,則交易包含Y的機率。一般來說,只有支持度和可信度較高的關聯規則才是使用者感興趣的。
定義八:設定關聯規則的最小支持度和最小可信度為SUPmin和CONFmin。規則R的支持度和可信度均不小於SUPmin和CONFmin ,則稱為強關聯規則。關聯規則挖掘的目的是找出強關聯規則,以指導商家的決策。 這八個定義包含了關聯規則相關的幾個重要基本概念,關聯規則挖掘主要有兩個問題:
- 找出交易資料庫中所有大於或等於使用者指定的最小支持度的頻繁項集。
- 利用頻繁項集產生所需的關聯規則,根據使用者設定的最小可信度篩選出強關聯規則。
目前研究者主要針對第一個問題進行研究,找出頻繁集合是比較困難的,而有了頻繁集再產生強關聯規則就相對容易了。
二、理論基礎
首先來看一個頻繁集合的性質。
定理:如果項目集X是頻繁集,那麼它的非空子集都是頻繁集合# 。
根據定理,已知一個k-頻繁集的項集X,X的所有k-1階子集都肯定是頻繁集,也就肯定可以找到兩個k-1頻繁集合的項集,它們只有一項不同,且連接後等於X。這證明了透過連接k-1頻繁集產生的k-候選集覆蓋了k-頻繁集。同時,如果k-候選集中的項集Y,包含有某個k-1階子集不屬於k-1頻繁集,那麼Y就不可能是頻繁集,應該從候選集中裁剪掉。 Apriori演算法就是利用了頻繁集的這個性質。
三、演算法步驟:
首先是測試資料:
##交易ID |
|
| #商品 ##ID |
|
| #T100 | #I1,I2,I5 |
| I2,I4 | |
| ## I2,I3 | T400 |
| I1,I2,I4 | T500 |
| I1,I3 | T600 |
| #I2,I3 | T700 |
演算法的步驟圖:
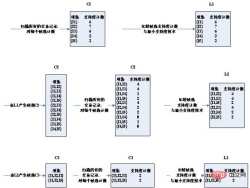
#可以看到,第三輪的候選集合發生了明顯的縮小,這是為什麼呢?
請注意取候選集的兩個條件:
1.兩個K項集能夠連接的兩個條件是,它們有K- 1項是相同的。所以,(I2,I4)和(I3,I5)這種是不能夠進行連接的。縮小了候選集。
2.如果一個項集是頻繁集,那麼它不存在不是子集的頻繁集。例如(I1,I2)和(I1,I4)得到(I1,I2,I4),而(I1,I2,I4)存在子集(I1,I4)不是頻繁集合。縮小了候選集。
第三輪得到的2個候選集,剛好支持度等於最小支持度。所以,都算入頻繁集。
這時再看第四輪的候選集與頻繁集結果為空
#可以看到,候選集和頻繁集居然為空了!因為透過第三輪得到的頻繁集自連接得到{I1,I2,I3,I5},它擁有子集{I2,I3,I5},而{I2,I3,I5}不是頻繁集,不滿足:頻繁集的子集也是頻繁集這一條件,所以被剪枝剪掉了。所以整個演算法終止,取最後一次計算得到的頻繁集合作為最終的頻繁集結果:
也就是:['I1,I2,I3', 'I1,I2,I5 ']
四、程式碼:
編寫Python程式碼實作Apriori演算法。程式碼需要注意如下兩點:
- 由於Apriori演算法假定項目集中的項是依字典序排序的,而集合本身是無序的,所以我們在必要時需要進行set和list的轉換;
- 由於要使用字典(support_data)記錄項集的支持度,需要以項集作為key,而可變集合無法作為字典的key,因此在適當時機應將項集轉為固定集合frozenset。
def local_data(file_path): import pandas as pd
dt = pd.read_excel(file_path)
data = dt['con']
locdata = [] for i in data:
locdata.append(str(i).split(",")) # print(locdata) # change to [[1,2,3],[1,2,3]]
length = [] for i in locdata:
length.append(len(i)) # 计算长度并存储
# print(length)
ki = length[length.index(max(length))] # print(length[length.index(max(length))]) # length.index(max(length)读取最大值的位置,然后再定位取出最大值
return locdata,kidef create_C1(data_set): """
Create frequent candidate 1-itemset C1 by scaning data set.
Args:
data_set: A list of transactions. Each transaction contains several items.
Returns:
C1: A set which contains all frequent candidate 1-itemsets """
C1 = set() for t in data_set: for item in t:
item_set = frozenset([item])
C1.add(item_set) return C1def is_apriori(Ck_item, Lksub1): """
Judge whether a frequent candidate k-itemset satisfy Apriori property.
Args:
Ck_item: a frequent candidate k-itemset in Ck which contains all frequent
candidate k-itemsets.
Lksub1: Lk-1, a set which contains all frequent candidate (k-1)-itemsets.
Returns:
True: satisfying Apriori property.
False: Not satisfying Apriori property. """
for item in Ck_item:
sub_Ck = Ck_item - frozenset([item]) if sub_Ck not in Lksub1: return False return Truedef create_Ck(Lksub1, k): """
Create Ck, a set which contains all all frequent candidate k-itemsets
by Lk-1's own connection operation.
Args:
Lksub1: Lk-1, a set which contains all frequent candidate (k-1)-itemsets.
k: the item number of a frequent itemset.
Return:
Ck: a set which contains all all frequent candidate k-itemsets. """
Ck = set()
len_Lksub1 = len(Lksub1)
list_Lksub1 = list(Lksub1) for i in range(len_Lksub1): for j in range(1, len_Lksub1):
l1 = list(list_Lksub1[i])
l2 = list(list_Lksub1[j])
l1.sort()
l2.sort() if l1[0:k-2] == l2[0:k-2]:
Ck_item = list_Lksub1[i] | list_Lksub1[j] # pruning
if is_apriori(Ck_item, Lksub1):
Ck.add(Ck_item) return Ckdef generate_Lk_by_Ck(data_set, Ck, min_support, support_data): """
Generate Lk by executing a delete policy from Ck.
Args:
data_set: A list of transactions. Each transaction contains several items.
Ck: A set which contains all all frequent candidate k-itemsets.
min_support: The minimum support.
support_data: A dictionary. The key is frequent itemset and the value is support.
Returns:
Lk: A set which contains all all frequent k-itemsets. """
Lk = set()
item_count = {} for t in data_set: for item in Ck: if item.issubset(t): if item not in item_count:
item_count[item] = 1 else:
item_count[item] += 1
t_num = float(len(data_set)) for item in item_count: if (item_count[item] / t_num) >= min_support:
Lk.add(item)
support_data[item] = item_count[item] / t_num return Lkdef generate_L(data_set, k, min_support): """
Generate all frequent itemsets.
Args:
data_set: A list of transactions. Each transaction contains several items.
k: Maximum number of items for all frequent itemsets.
min_support: The minimum support.
Returns:
L: The list of Lk.
support_data: A dictionary. The key is frequent itemset and the value is support. """
support_data = {}
C1 = create_C1(data_set)
L1 = generate_Lk_by_Ck(data_set, C1, min_support, support_data)
Lksub1 = L1.copy()
L = []
L.append(Lksub1) for i in range(2, k+1):
Ci = create_Ck(Lksub1, i)
Li = generate_Lk_by_Ck(data_set, Ci, min_support, support_data)
Lksub1 = Li.copy()
L.append(Lksub1) return L, support_datadef generate_big_rules(L, support_data, min_conf): """
Generate big rules from frequent itemsets.
Args:
L: The list of Lk.
support_data: A dictionary. The key is frequent itemset and the value is support.
min_conf: Minimal confidence.
Returns:
big_rule_list: A list which contains all big rules. Each big rule is represented
as a 3-tuple. """
big_rule_list = []
sub_set_list = [] for i in range(0, len(L)): for freq_set in L[i]: for sub_set in sub_set_list: if sub_set.issubset(freq_set):
conf = support_data[freq_set] / support_data[freq_set - sub_set]
big_rule = (freq_set - sub_set, sub_set, conf) if conf >= min_conf and big_rule not in big_rule_list: # print freq_set-sub_set, " => ", sub_set, "conf: ", conf big_rule_list.append(big_rule)
sub_set_list.append(freq_set) return big_rule_listif __name__ == "__main__": """
Test """
file_path = "test_aa.xlsx"
data_set,k = local_data(file_path)
L, support_data = generate_L(data_set, k, min_support=0.2)
big_rules_list = generate_big_rules(L, support_data, min_conf=0.4) print(L) for Lk in L: if len(list(Lk)) == 0: break
print("="*50) print("frequent " + str(len(list(Lk)[0])) + "-itemsets\t\tsupport") print("="*50) for freq_set in Lk: print(freq_set, support_data[freq_set]) print() print("Big Rules") for item in big_rules_list: print(item[0], "=>", item[1], "conf: ", item[2])
檔案格式:
test_aa.xlsx
name con T1 2,3,5T2 1,2,4T3 3,5T5 2,3,4T6 2,3,5T7 1,2,4T8 3,5T9 2,3,4T10 1,2,3,4,5
#相關免費學習推薦:#python影片教學
以上是如何理解關聯規則apriori演算法的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 Python:深入研究彙編和解釋May 12, 2025 am 12:14 AM
Python:深入研究彙編和解釋May 12, 2025 am 12:14 AMpythonisehybridmodeLofCompilation和interpretation:1)thepythoninterpretercompilesourcecececodeintoplatform- interpententbybytecode.2)thepythonvirtualmachine(pvm)thenexecutecutestestestestestesthisbytecode,ballancingEaseofuseEfuseWithPerformance。
 Python是一種解釋或編譯語言,為什麼重要?May 12, 2025 am 12:09 AM
Python是一種解釋或編譯語言,為什麼重要?May 12, 2025 am 12:09 AMpythonisbothinterpretedAndCompiled.1)它的compiledTobyTecodeForportabilityAcrosplatforms.2)bytecodeisthenInterpreted,允許fordingfordforderynamictynamictymictymictymictyandrapiddefupment,儘管Ititmaybeslowerthananeflowerthanancompiledcompiledlanguages。
 對於python中的循環時循環與循環:解釋了關鍵差異May 12, 2025 am 12:08 AM
對於python中的循環時循環與循環:解釋了關鍵差異May 12, 2025 am 12:08 AM在您的知識之際,而foroopsareideal insinAdvance中,而WhileLoopSareBetterForsituations則youneedtoloopuntilaconditionismet
 循環時:實用指南May 12, 2025 am 12:07 AM
循環時:實用指南May 12, 2025 am 12:07 AMForboopSareSusedwhenthentheneMberofiterationsiskNownInAdvance,而WhileLoopSareSareDestrationsDepportonAcondition.1)ForloopSareIdealForiteratingOverSequencesLikelistSorarrays.2)whileLeleLooleSuitableApeableableableableableableforscenarioscenarioswhereTheLeTheLeTheLeTeLoopContinusunuesuntilaspecificiccificcificCondond
 Python:它是真正的解釋嗎?揭穿神話May 12, 2025 am 12:05 AM
Python:它是真正的解釋嗎?揭穿神話May 12, 2025 am 12:05 AMpythonisnotpuroly interpred; itosisehybridablectofbytecodecompilationandruntimeinterpretation.1)PythonCompiLessourceceCeceDintobyTecode,whitsthenexecececected bytybytybythepythepythepythonvirtirtualmachine(pvm).2)
 與同一元素的Python串聯列表May 11, 2025 am 12:08 AM
與同一元素的Python串聯列表May 11, 2025 am 12:08 AMconcatenateListSinpythonWithTheSamelements,使用:1)operatoTotakeEpduplicates,2)asettoremavelemavphicates,or3)listcompreanspherensionforcontroloverduplicates,每個methodhasdhasdifferentperferentperferentperforentperforentperforentperfornceandordorimplications。
 解釋與編譯語言:Python的位置May 11, 2025 am 12:07 AM
解釋與編譯語言:Python的位置May 11, 2025 am 12:07 AMpythonisanterpretedlanguage,offeringosofuseandflexibilitybutfacingperformancelanceLimitationsInCricapplications.1)drightingedlanguageslikeLikeLikeLikeLikeLikeLikeLikeThonexecuteline-by-line,允許ImmediaMediaMediaMediaMediaMediateFeedBackAndBackAndRapidPrototypiD.2)compiledLanguagesLanguagesLagagesLikagesLikec/c thresst
 循環時:您什麼時候在Python中使用?May 11, 2025 am 12:05 AM
循環時:您什麼時候在Python中使用?May 11, 2025 am 12:05 AMUseforloopswhenthenumberofiterationsisknowninadvance,andwhileloopswheniterationsdependonacondition.1)Forloopsareidealforsequenceslikelistsorranges.2)Whileloopssuitscenarioswheretheloopcontinuesuntilaspecificconditionismet,usefulforuserinputsoralgorit


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

禪工作室 13.0.1
強大的PHP整合開發環境

MinGW - Minimalist GNU for Windows
這個專案正在遷移到osdn.net/projects/mingw的過程中,你可以繼續在那裡關注我們。 MinGW:GNU編譯器集合(GCC)的本機Windows移植版本,可自由分發的導入函式庫和用於建置本機Windows應用程式的頭檔;包括對MSVC執行時間的擴展,以支援C99功能。 MinGW的所有軟體都可以在64位元Windows平台上運作。

記事本++7.3.1
好用且免費的程式碼編輯器

mPDF
mPDF是一個PHP庫,可以從UTF-8編碼的HTML產生PDF檔案。原作者Ian Back編寫mPDF以從他的網站上「即時」輸出PDF文件,並處理不同的語言。與原始腳本如HTML2FPDF相比,它的速度較慢,並且在使用Unicode字體時產生的檔案較大,但支援CSS樣式等,並進行了大量增強。支援幾乎所有語言,包括RTL(阿拉伯語和希伯來語)和CJK(中日韓)。支援嵌套的區塊級元素(如P、DIV),

Atom編輯器mac版下載
最受歡迎的的開源編輯器

