
MySQL索引能讓查詢效率提高這麼多原因是?

- coldplay.xixi轉載
- 2020-09-28 17:08:072657瀏覽

背景
我相信大家在資料庫優化的時候都會說到索引,我也不例外,大家也基本上能對資料結構的優化回答個一二三,以及頁緩存之類的都能扯上幾句,但是有一次阿里P9的一個面試問我:你能從計算機層面開始說一下一個索引數據加載的流程麼? (就是想讓我聊IO)
我當場就過世了....因為電腦網路和作業系統的基礎知識真的是我的盲區,不過後面我惡補了,廢話不多說,我們就從電腦載入資料聊起,講一下換個角度聊索引。
正文
MySQL的索引本質上是一種資料結構
#讓我們先來了解電腦的資料載入。
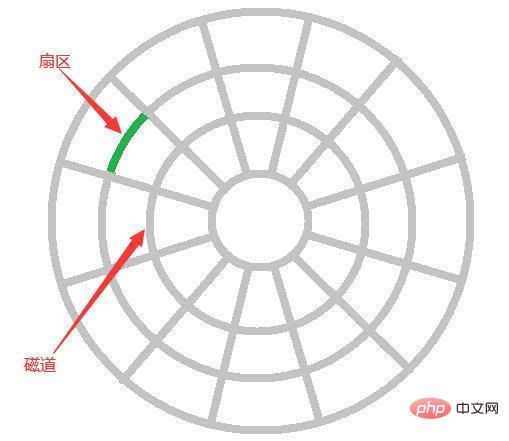
磁碟IO與預讀:

#先說一下磁碟IO,磁碟讀取資料靠的是機械運動,每一次讀取資料需要尋道、尋點、拷貝到記憶體三步驟操作。
尋道時間是磁臂移動到指定磁軌所需的時間,一般在5ms以下;
尋點是從磁軌中找到資料存在的那個點,平均時間是半圈時間,如果是一個7200轉/min的磁碟,尋點時間平均是600000/7200/2=4.17ms;
拷貝到內存的時間很快,和前面兩個時間比起來可以忽略不計,所以一次IO的時間平均是在9ms左右。聽起來很快,但資料庫百萬層級的資料過一遍就達到了9000s,顯然就是災難等級的了。
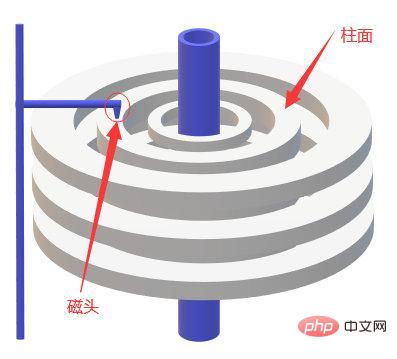
考慮到磁碟IO是非常高昂的操作,電腦作業系統做了預讀的最佳化,當一次IO時,不光把當前磁碟位址的數據,而是把相鄰的數據也都讀取到記憶體緩衝區內,因為當電腦存取一個位址的數據的時候,與其相鄰的數據也會很快被存取。
每一次IO讀取的資料我們稱為一頁(page),具體一頁有多大數據跟作業系統有關,一般為4k或8k,也就是我們讀取一頁內的數據時候,實際上才發生了一次IO。
(突然想到我剛畢業被問過的問題,在64位元的作業系統中,Java中的int型別佔幾個位元組?最大是多少?為什麼?)
#那我們想要優化資料庫查詢,就要盡量減少磁碟的IO操作,所以就出現了索引。
索引是什麼?
MySQL官方對索引的定義為:索引(Index)是幫助MySQL有效率地取得資料的資料結構。
MySQL 中常用的索引在物理上分成兩類,B-樹索引和哈希索引。
本次主要講BTree索引。
BTree索引
BTree又叫多路平衡查找樹,一顆m叉的BTree特性如下:
- 樹中每個節點最多包含m個孩子。
- 除根節點與葉子節點外,每個節點至少有[ceil(m/2)]個孩子(ceil()為向上取整)。
- 若根節點不是葉子節點,則至少有兩個孩子。
- 所有的葉子節點都在同一層。
- 每個非葉子節點由n個key與n 1個指標組成,其中[ceil(m/2)-1] <= n <= m-1 。
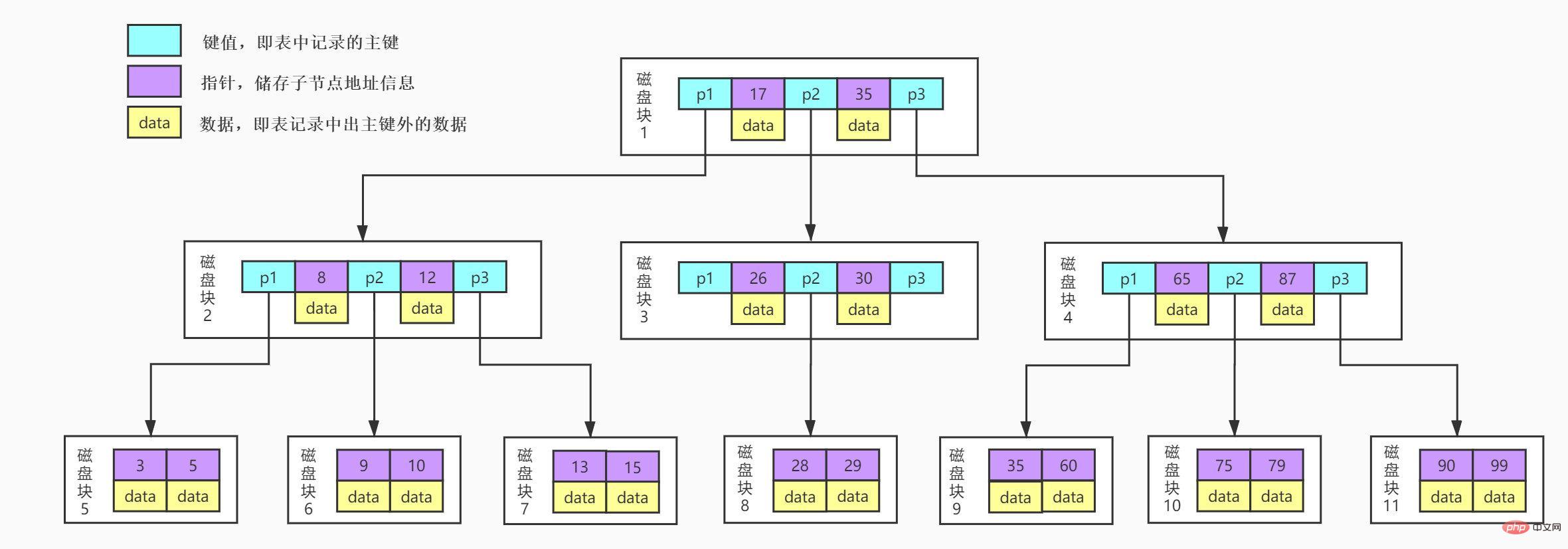
這是一個3叉(只是舉例,真實會有很多叉)的BTree結構圖,每一個方框區塊我們稱之為一個磁碟區塊或叫做一個block區塊,這是作業系統一次IO往記憶體中讀的內容,一個區塊對應四個磁區,紫色代表的是磁碟區塊中的資料key,黃色代表的是資料data,藍色代表的是指標p,指向下一個磁碟區塊的位置。
來模擬下查找key為29的data的過程:
1、根據根結點指標讀取檔案目錄的根磁碟區塊1。 【磁碟IO操作1次】
2、磁碟區塊1儲存17,35和三個指標資料。我們發現17<29<35,因此我們找到指針p2。
3、根據p2指針,我們定位並讀取磁碟區塊3。 【磁碟IO操作2次】
4、磁碟區塊3儲存26,30和三個指標資料。我們發現26<29<30,因此我們找到指針p2。
5、根據p2指針,我們定位並讀取磁碟區塊8。 【磁碟IO操作3次】
6、磁碟區塊8中儲存28,29。我們找到29,取得29所對應的資料data。
由此可見,BTree索引使每次磁碟I/O取到記憶體的資料都發揮了作用,從而提高了查詢效率。
但是有沒有什麼好優化的地方呢?
我們可以從圖上看到,每個節點中不只包含資料的key值,還有data值。而每一個頁的儲存空間是有限的,如果data資料較大時將會導致每個節點(即一個頁)能儲存的key的數量很小,當儲存的資料量很大時同樣會導致B- Tree的深度較大,增加查詢時的磁碟I/O次數,進而影響查詢效率。
B Tree索引
B Tree是在B-Tree基礎上的最佳化,使其更適合實現外儲存索引結構。在B Tree中,所有資料記錄節點都是按照鍵值大小順序存放在同一層的葉子節點上,而非葉子節點上只存儲key值信息,這樣可以大大加大每個節點存儲的key值數量,降低B Tree的高度。
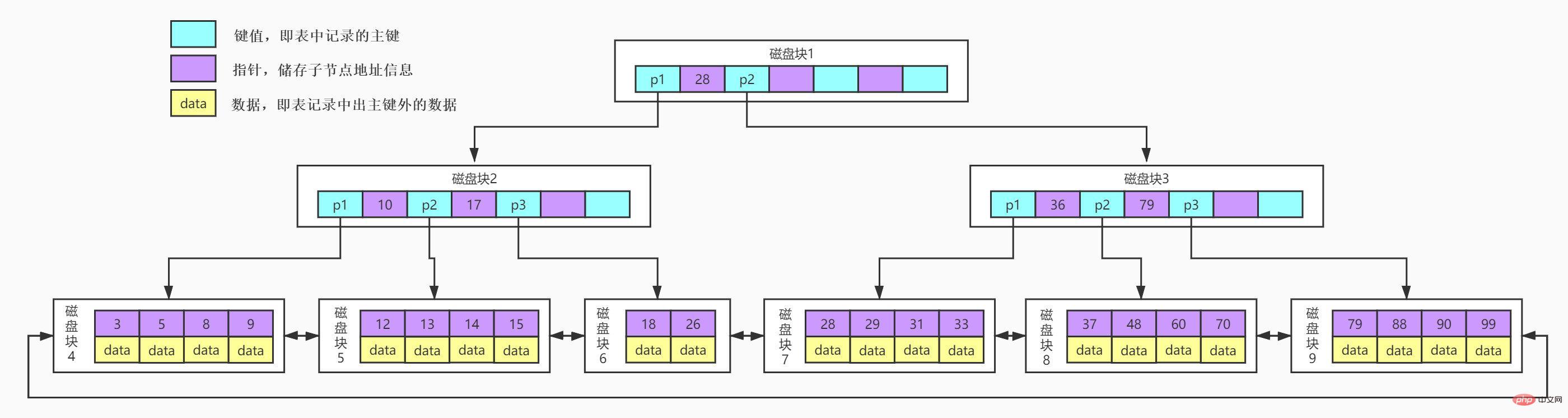
B Tree相對於B-Tree有幾點不同:
非葉子節點只儲存鍵值信息, 資料記錄都存放在葉子節點中, 將上一節中的B-Tree優化,由於B Tree的非葉子節點只存儲鍵值信息,所以B Tree的高度可以被壓縮到特別的低。
具體的資料如下:
InnoDB儲存引擎中頁的大小為16KB,一般表的主鍵類型為INT(佔用4個位元組)或BIGINT(佔用8個位元組),指標型別也一般為4或8個字節,也就是說一個頁(B Tree中的一個節點)中大概儲存16KB/(8B 8B)=1K個鍵值(因為是估值,為方便計算,這裡的K取值為〖10〗^3)。
也就是說一個深度為3的B Tree索引可以維護10^3 10^3 10^3 = 10億 筆記錄。 (這種計算方式存在誤差,而且沒有計算葉子節點,如果計算葉子節點其實是深度為4了)
我們只需要進行三次的IO操作就可以從10億條數據中找到我們想要的數據,比起最開始的百萬數據9000秒不知道好了多少個華萊士了。
而且在B Tree上通常有兩個頭指針,一個指向根節點,另一個指向關鍵字最小的葉子節點,而且所有葉子節點(即資料節點)之間是一種鍊式環結構。所以我們除了可以對B Tree進行主鍵的範圍查找和分頁查找,還可以從根節點開始,進行隨機查找。
資料庫中的B Tree索引可以分為聚集索引(clustered index)和輔助索引(secondary index)。
上面的B Tree範例圖在資料庫中的實作即為聚集索引,聚集索引的B Tree中的葉子節點存放的是整張表的行記錄數據,輔助索引與聚集索引的區別在於輔助索引的葉子節點並不包含行記錄的全部數據,而是儲存相應行數據的聚集索引鍵,即主鍵。
當透過輔助索引來查詢資料時,InnoDB儲存引擎會遍歷輔助索引找到主鍵,然後再透過主鍵在聚集索引中找到完整的行記錄資料。
不過,雖然索引可以加快查詢速度,提高MySQL 的處理效能,但過度使用索引也會造成以下弊端:
- 建立索引和維護索引要耗費時間,這種時間隨著資料量的增加而增加。
- 除了資料表佔資料空間之外,每一個索引還要佔一定的實體空間。如果要建立叢集索引,那麼需要的空間就會更大。
- 當資料表中的資料增加、刪除和修改的時候,索引也要動態地維護,這樣就降低了資料的維護速度。
注意:索引可以在某些情況下加速查詢,但是在某些情況下,會降低效率。
索引只是提高效率的一個因素,因此在建立索引的時候應該遵循以下原則:
- 在經常需要搜尋的列上建立索引,可以加快搜尋的速度。
- 在作為主鍵的列上建立索引,強制該列的唯一性,並組織表中資料的排列結構。
- 在經常使用表連接的列上建立索引,這些列主要是一些外鍵,可以加快表連接的速度。
- 在經常需要根據範圍進行搜尋的列上建立索引,因為索引已經排序,所以其指定的範圍是連續的。
- 在經常需要排序的欄位上建立索引,因為索引已經排序,所以查詢時可以利用索引的排序,加快排序查詢。
- 在經常使用 WHERE 子句的欄位上建立索引,加快條件的判斷速度。
現在大家知道索引為啥能這麼快了吧,其實就是一句話,透過索引的結構最大化的減少資料庫的IO次數,畢竟,一次IO的時間真的是太久了。 。 。
總結
就面試而言很多知識其實我們可以很容易就掌握了,但是要以學習為目的,你會發現很多東西我們得深入到計算機基礎上才能發現其中奧秘,很多人問我怎麼記住這麼多東西,其實學習本身就是一個很無奈的東西,既然我們不能不學那為啥不好好學?去學會享受呢?最近我也在惡補基礎,後面我會開始更新電腦基礎和網路相關的知識的。
我是敖丙,你知道的越多,你不知道的越多,我們下期見!
人才們的 【三連】 就是敖丙創作的最大動力,如果本篇部落格有任何錯誤和建議,歡迎人才留言!
更多相關免費學習推薦:mysql教學##(影片)
#
以上是MySQL索引能讓查詢效率提高這麼多原因是?的詳細內容。更多資訊請關注PHP中文網其他相關文章!