
解決php字串一樣但長度不等的問題

- 藏色散人原創
- 2020-07-18 09:06:242973瀏覽
解決php字串長度不等的方法:先透過「mb_detect_encoding()」函式查看兩個字串的編碼方式;然後查看特定字元長度;最後剔除非中文字元即可。

問題:
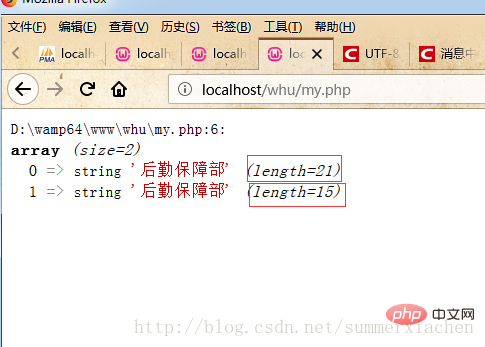
#如圖所示咋眼看去兩個一樣的中文字串“後勤支援部”,但一個長度為21 一個為15。
首先直覺可能會認為是編碼方式不一樣導致的,
透過mb_detect_encoding()函數查看兩個字串的編碼方式代碼如下
<?phpheader("Content-Type: text/html;charset=utf-8");
$data[0]=$str1="后勤保障部";$data[1]=$str2="后勤保障部";
var_dump($data);//查看编码方式$encode1 = mb_detect_encoding($str1, array("ASCII","UTF-8","GB2312","GBK","BIG5"));$encode2 = mb_detect_encoding($str2, array("ASCII","UTF-8","GB2312","GBK","BIG5"));echo "str1='".$str1."'"." 编码:".$encode1."</br>";echo "str2='".$str2."'"." 编码:".$encode2."</br>";?>但輸出結果都是UTF-8
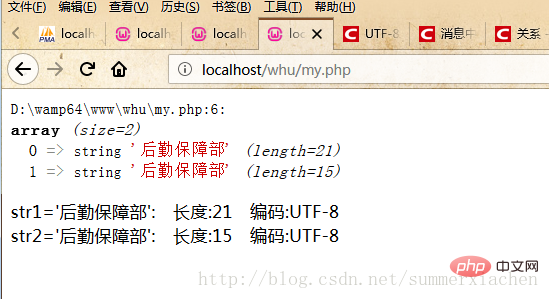
那麼是什麼原因呢,我們在輸出看下具體字元長度
<?phpheader("Content-Type: text/html;charset=utf-8");
$data[0]=$str1="后勤保障部";$data[1]=$str2="后勤保障部";
var_dump($data);//查看编码方式$encode1 = mb_detect_encoding($str1, array("ASCII","UTF-8","GB2312","GBK","BIG5"));$encode2 = mb_detect_encoding($str2, array("ASCII","UTF-8","GB2312","GBK","BIG5"));//当mb_strlen的内码选择为UTF-8的时候,则会将中文字符当成一个字符//strlen,得到的是字符串所占的字节数echo "str1='".$str1."'".": 字符长度:".mb_strlen($str1).": 字节长度:".strlen($str1)." 编码:".$encode1."</br>";echo "str2='".$str2."'".": 字符长度:".mb_strlen($str2).": 字节长度:".strlen($str2)." 编码:".$encode2."</br>";?>輸出結果如下:
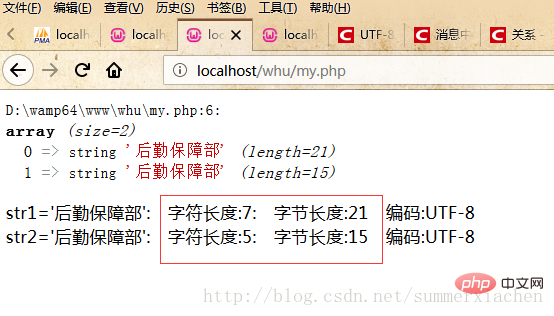
發現字串str1有7個中文字符,但實際上只顯示了5個,也就是「後勤支援部」
透過截取str1最後兩個字元查看
//截取str1后面两个未显示字符$res=mb_substr($str1, 5,2);echo "最后两字符:".$res."</br>";echo mb_strlen($res);
無法echo顯示,但確實佔有兩個字元
如果實際要求這看上去一樣的字串就相等的話,需要進行處理,處理就是剔除非中文字元:
//剔除str1字串中未显示的字符(非中文字符)preg_match_all('/[\x{4e00}-\x{9fff}]+/u', $str1, $matches);$str1 = join('', $matches[0]);最終程式碼如下
<?phpheader("Content-Type: text/html;charset=utf-8");
$data[0]=$str1="后勤保障部";$data[1]=$str2="后勤保障部";
var_dump($data);//查看编码方式$encode1 = mb_detect_encoding($str1, array("ASCII","UTF-8","GB2312","GBK","BIG5"));$encode2 = mb_detect_encoding($str2, array("ASCII","UTF-8","GB2312","GBK","BIG5"));//当mb_strlen的内码选择为UTF-8的时候,则会将中文字符当成一个字符//strlen,得到的是字符串所占的字节数echo "str1='".$str1."'".": 字符长度:".mb_strlen($str1).": 字节长度:".strlen($str1)." 编码:".$encode1."</br>";echo "str2='".$str2."'".": 字符长度:".mb_strlen($str2).": 字节长度:".strlen($str2)." 编码:".$encode2."</br>";//截取str1后面两个未显示字符echo "</br>------------------截取str1后面两个未显示字符---------------------</br>";$res=mb_substr($str1, 5,2);echo "str1最后两字符: ".$res."</br>";echo "str1长度: ".mb_strlen($res)."</br>";//比较echo "</br>--------------------------相等比较----------------------------------</br>";echo "str1 与 str2比较: ";echo strcomp($str1,$str2)."</br>";echo "str2 与 str2比较: ";echo strcomp($str2,$str2)."</br>";//剔除str1字串中非中文preg_match_all('/[\x{4e00}-\x{9fff}]+/u', $str1, $matches);$str1 = join('', $matches[0]);echo "</br>---------------------剔除str1字串中非中文后----------------------</br>";echo "str1='".$str1."'".": 字符长度:".mb_strlen($str1).": 字节长度:".strlen($str1)." 编码:".$encode1."</br>";echo "str1 与 str2比较: ";echo strcomp($str1,$str2)."</br>";function strcomp($str1,$str2){
if($str1 == $str2){
return "相等";
}else{
return "不等";
}
}
?>運行結果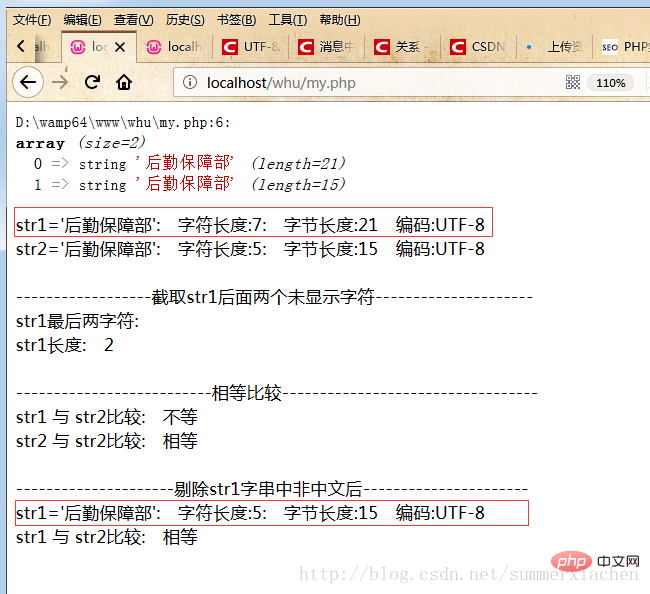
# 註:
將21位元組的str1複製到phpmyadmin的sql輸入框,顯示如下
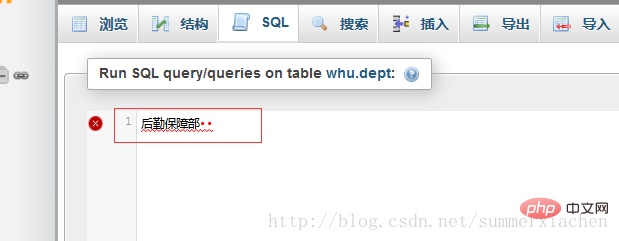
嗯就是多的那兩個字元
更多相關知識,請造訪 PHP中文網!
#以上是解決php字串一樣但長度不等的問題的詳細內容。更多資訊請關注PHP中文網其他相關文章!
陳述:
本文內容由網友自願投稿,版權歸原作者所有。本站不承擔相應的法律責任。如發現涉嫌抄襲或侵權的內容,請聯絡admin@php.cn