
關於Linux的快取記憶體Cache Memory(圖文詳解)
- 烟雨青岚轉載
- 2020-06-20 13:20:146246瀏覽

關於Linux的快取記憶體Cache Memory(圖文詳解)
今天探究的主題是cache。我們圍繞著幾個問題展開。為什麼需要cache?如何判斷一個資料在cache中是否命中? cache的種類有哪些,差別是什麼?
為什麼需要cache memory
在思考cache是什麼之前我們先來思考第一個問題:我們的程式是如何運作起來的?我們應該知道程式是運作在 RAM之中,RAM 就是我們常說的DDR(例如 DDR3、DDR4等)。我們稱之為main memory(主記憶體)當我們需要執行一個程序的時候,首先會從Flash設備(例如,eMMC、UFS等)中將可執行程式load到main memory中,然後開始執行。在CPU內部存在一堆的通用寄存器(register)。若CPU需要將一個變數(假設位址是A)加1,一般分為以下3個步驟:
CPU 從主記憶體讀取位址A的資料到內部通用暫存器x0(ARM64架構的通用暫存器之一)。
通用暫存器 x0 加1。
CPU 將通用暫存器 x0 的值寫入主記憶體。
我們將這個過程可以表示如下:
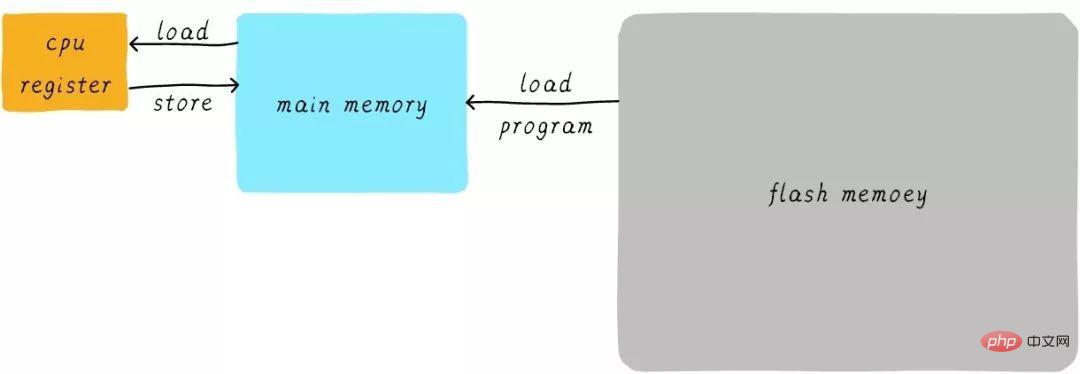
#其實實作中,CPU通用暫存器的速度和主記憶體之間存在著太大的差異。兩者之間的速度大致如下關係:
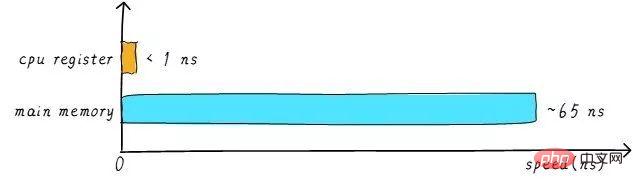
CPU register的速度一般小於1ns,主存的速度一般是65ns左右。速度差異近百倍。因此,上面舉例的3個步驟中,步驟1和步驟3其實速度很慢。當CPU試圖從主記憶體load/store 操作時,由於主記憶體的速度限制,CPU不得不等待這漫長的65ns時間。如果我們可以提升主記憶體的速度,那麼系統將會獲得很大的效能提升。
如今的DDR儲存設備,動不動就是幾個GB,容量很大。如果我們採用更快材料製作更快速度的主存,並且擁有幾乎差不多的容量。其成本將會大幅上升。我們試著提升主存的速度和容量,又期望其成本很低,這就有點難為人了。因此,我們有一種折衷的方法,那就是製作一塊速度極快但是容量極小的儲存設備。那麼其成本也不會太高。這塊儲存設備我們稱為cache memory。
在硬體上,我們將cache放置在CPU和主記憶體之間,作為主記憶體資料的快取。當CPU試圖從主記憶體中load/store資料的時候, CPU會先從cache中尋找對應位址的資料是否會快取在cache 中。如果其資料快取在cache中,直接從cache中拿到資料並傳回給CPU。當存在cache的時候,以上程式如何運作的範例的流程將會變成如下:
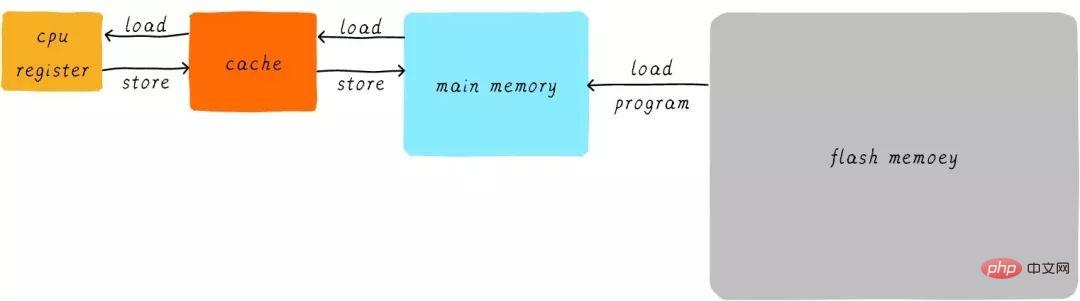
CPU和主記憶體之間直接資料傳輸的方式轉變成CPU和cache之間直接資料傳輸。 cache負責和主記憶體之間資料傳輸。
多層cache memory
cahe的速度在某種程度上同樣影響系統的效能。
一般情況cache的速度可以達到1ns,幾乎可以和CPU暫存器速度媲美。但是,這就滿足人們對性能的追求了嗎?並沒有。當cache中沒有快取我們想要的資料的時候,依然需要漫長的等待從主記憶體load資料。為了進一步提升效能,引入多層cache。
前面提到的cache,稱為L1 cache(第一級cache)。我們在L1 cache 後面連接L2 cache,在L2 cache 和主記憶體之間連接L3 cache。等級越高,速度越慢,容量越大。但是速度相比較主存而言,依然很快。不同等級cache速度之間關係如下:
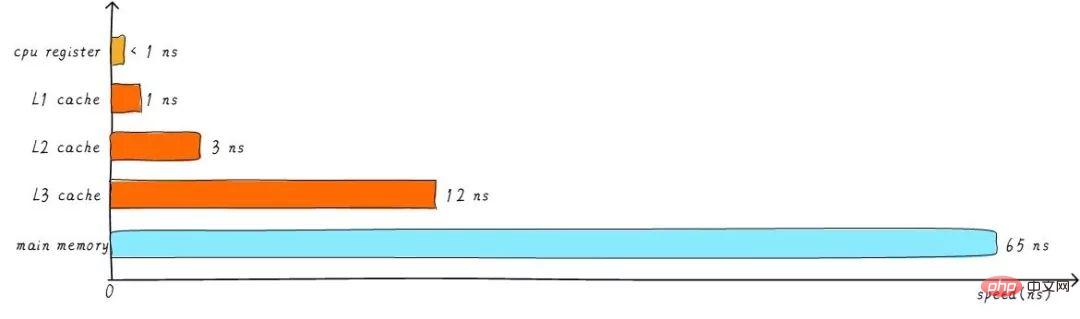
經過3級cache的緩衝,各級cache和主記憶體之間的速度最萌差也逐級減少。在一個真實的系統上,各級cache之間硬體上是如何關聯的呢?我們看下Cortex-A53架構上各級cache之間的硬體抽象框圖如下:
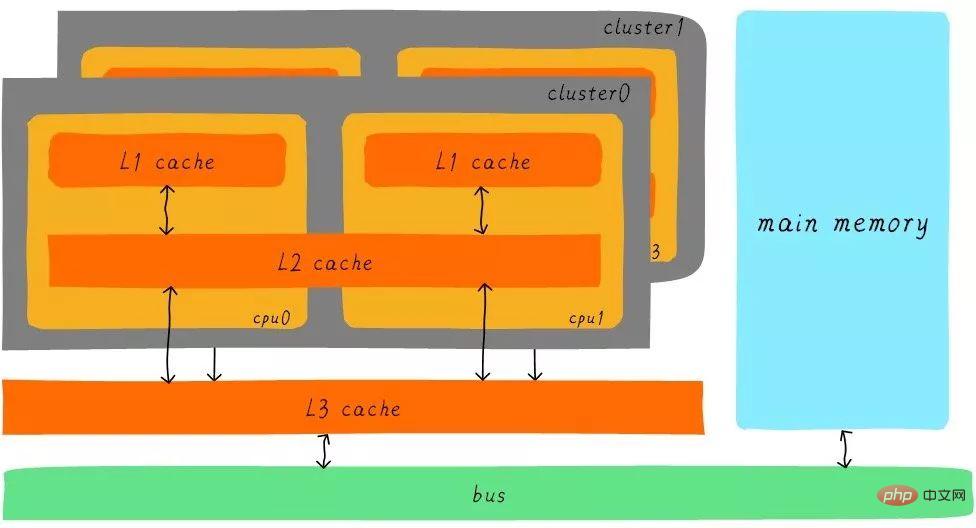
在Cortex-A53架構上,L1 cache分為單獨的instruction cache(ICache)和data cache(DCache)。 L1 cache是CPU私有的,每個CPU都有一個L1 cache。一個cluster 內的所有CPU共享一個L2 cache,L2 cache不區分指令和數據,都可以快取。所有cluster之間共用L3 cache。 L3 cache透過匯流排和主存相連。
多層cache之間的配合工作
首先引入兩個名詞概念,命中和缺失。 CPU要存取的資料在cache中有一個快取,稱為「命中」 (hit),反之則稱為「缺失」 (miss)。多層次cache之間是如何配合工作的呢?我們假設現在考慮的系統只有兩級cache。
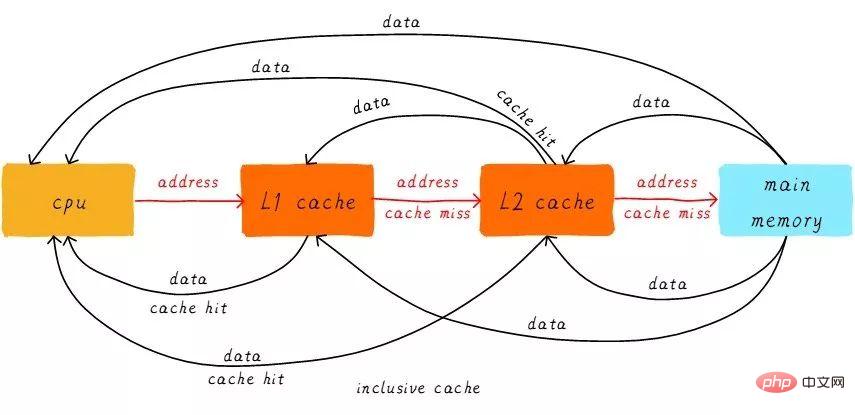
當CPU試圖從某個位址load資料時,先從L1 cache查詢是否命中,如果命中則把資料回傳給CPU。如果L1 cache缺失,則繼續從L2 cache中尋找。當L2 cache命中時,資料會傳回L1 cache以及CPU。如果L2 cache也缺失,很不幸,我們需要從主記憶體load數據,將數據回傳給L2 cache、L1 cache及CPU。這種多級cache的工作方式稱之為inclusive cache。
某一位址的資料可能存在多層快取中。與inclusive cache對應的是exclusive cache,這種cache保證某一位址的資料快取只會存在於多層cache其中一階。也就是說,任意位址的資料不可能同時在L1和L2 cache中快取。
直接映射快取(Direct mapped cache)
我們繼續引入一些cache相關的名詞。 cache的大小稱之為cahe size,代表cache可以快取最大資料的大小。我們將cache平均分成相等的許多區塊,每個區塊大小稱為cache line,其大小是cache line size。
例如一個64 Bytes大小的cache。如果我們將64 Bytes平均分成64塊,那麼cache line就是1字節,總共64行cache line。如果我們將64 Bytes平均分成8塊,那麼cache line就是8字節,總共8行cache line。現在的硬體設計中,一般cache line的大小是4-128 Byts。為什麼沒有1 byte呢?原因我們後面討論。
這裡有一點要注意,cache line是cache和主記憶體之間資料傳輸的最小單位。什麼意思呢?當CPU試圖load一個位元組資料的時候,如果cache缺失,那麼cache控制器就會從主記憶體中一次性的load cache line大小的資料到cache。例如,cache line大小是8位元組。 CPU即使讀取一個byte,在cache缺失後,cache會從主記憶體load 8位元組填入整個cache line。又是因為什麼呢?後面說完就懂了。
我們假設下面的解說都是針對64 Bytes大小的cache,而cache line大小是8位元組。我們可以類似把這塊cache想想成一個數組,數組總共8個元素,每個元素大小是8個位元組。就像下圖這樣。

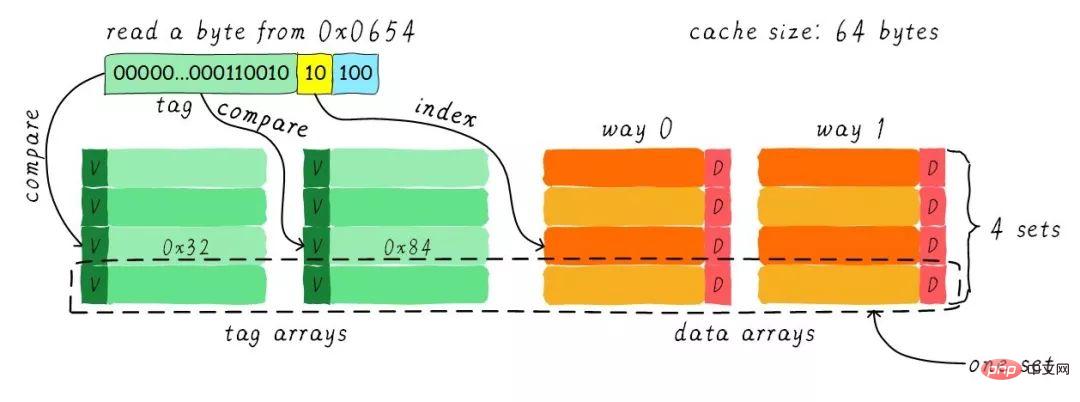
現在我們考慮一個問題,CPU從0x0654位址讀取一個位元組,cache控制器是如何判斷資料是否在cache中命中? cache大小相對於主存來說,可謂是小巫見大巫。所以cache肯定是只能快取主記憶體中極小一部分資料。我們如何根據位址在有限大小的cache中尋找資料呢?現在硬體採取的做法是對位址進行雜湊(可以理解成位址取模運算)。我們接下來看看是如何做到的?

我們一共有8行cache line,cache line大小是8 Bytes。所以我們可以利用位址低3 bits(如上圖位址藍色部分)用來尋址8 bytes中某一字節,我們稱這部分bit組合為offset。同理,8行cache line,為了涵蓋所有行。
我們需要3 bits(如上圖位址黃色部分)來找出某一行,這部分位址部分稱之為index。現在我們知道,如果兩個不同的位址,其位址的bit3-bit5如果完全一樣的話,那麼這兩個位址經過硬體雜湊之後都會找到同一個cache line。所以,當我們找到cache line之後,只代表我們存取的位址對應的資料可能存在這個cache line中,但也有可能是其他位址對應的資料。所以,我們又引入tag array區域,tag array和data array一一對應。
每一個cache line都對應唯一一個tag,tag中保存的是整個位址位寬去除index和offset使用的bit剩餘部分(如上圖位址綠色部分)。 tag、index和offset三者組合就可以唯一確定一個地址了。因此,當我們根據位址中index位找到cache line後,取出目前cache line對應的tag,然後和位址中的tag進行比較,如果相等,這表示cache命中。如果不相等,表示目前cache line儲存的是其他位址的數據,這就是cache缺失。
在上述圖中,我們看到tag的值是0x19,和位址中的tag部分相等,因此在本次造訪會命中。由於tag的引入,因此解答了我們之前的一個疑問「為什麼硬體cache line不做成一個位元組?」。這樣會導致硬體成本的上升,因為原本8個位元組對應一個tag,現在需要8個tag,佔用了很多記憶體。
我們可以從圖中看到tag旁邊還有一個valid bit,這個bit用來表示cache line中資料是否有效(例如:1代表有效;0代表無效)。當系統剛啟動時,cache中的資料都應該是無效的,因為還沒有快取任何資料。 cache控制器可以根據valid bit確認目前cache line資料是否有效。所以,上述比較tag確認cache line是否命中之前還會檢查valid bit是否有效。只有在有效的情況下,比較tag才有意義。如果無效,直接判定cache缺失。
上面的範例中,cache size是64 Bytes且cache line size是8 bytes。 offset、index和tag分別使用3 bits、3 bits和42 bits(假設地址寬度是48 bits)。我們現在再看一個例子:512 Bytes cache size,64 Bytes cache line size。根據先前的地址分割方法,offset、index和tag分別使用6 bits、3 bits和39 bits。如下圖所示。

直接對應快取的優缺點
#直接對映快取在硬體設計上會比較簡單,因此成本上也會較低。根據直接映射快取的工作方式,我們可以畫出主記憶體0x00-0x88位址對應的cache分佈圖。
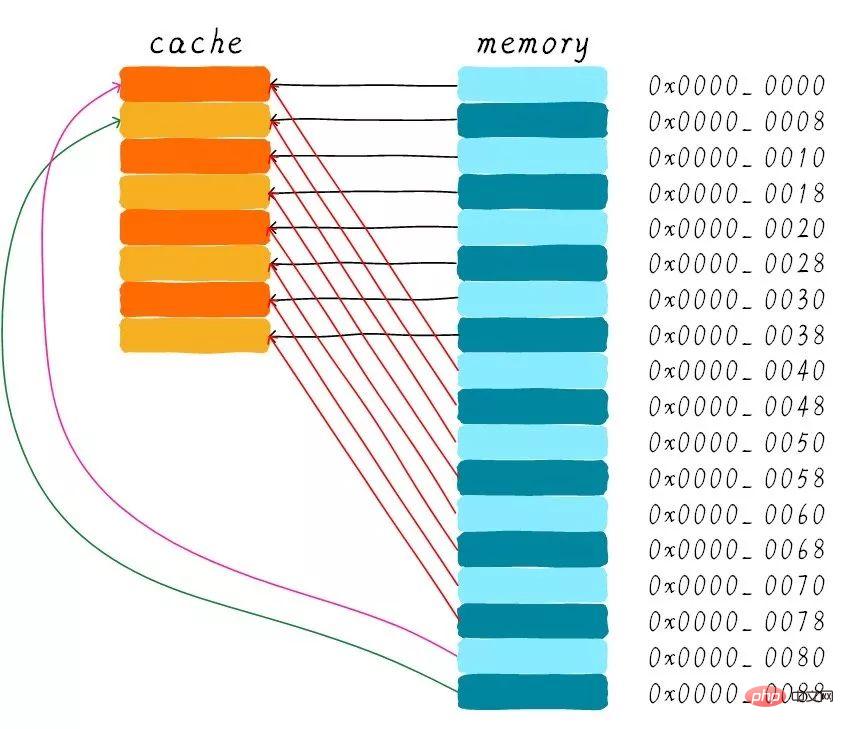
我們可以看到,在位址0x00-0x3f位址處對應的資料可以覆寫整個cache。 0x40-0x7f位址的資料也同樣是覆蓋整個cache。我們現在思考一個問題,如果一個程式試圖依序存取位址0x00、0x40、0x80,cache中的資料會發生什麼事呢?
首先我們應該要明白0x00、0x40、0x80位址中index部分是一樣的。因此,這3個位址對應的cache line是同一個。所以,當我們存取0x00位址時,cache會缺失,然後資料會從主記憶體載入到cache中第0行cache line。當我們存取0x40位址時,依然索引到cache中第0行cache line,由於此時cache line中儲存的是位址0x00位址對應的數據,所以此時仍會cache缺失。然後從主記憶體載入0x40位址資料到第一行cache line。同理,繼續訪問0x80地址,依然會cache缺失。
這等於是每次存取資料都要從主記憶體讀取,所以cache的存在並沒有對效能有什麼提升。存取0x40位址時,就會把0x00位址快取的資料替換。這種現象叫做cache顛簸(cache thrashing)。針對這個問題,我們引入多路組相連快取。我們首先研究下最簡單的兩路組相連快取的工作原理。
兩路組相連快取(Two-way set associative cache)
我們依然假設64 Bytes cache size,cache line size是8 Bytes。什麼是路(way)的概念。我們將cache平均分成多份,每份就是一路。因此,兩路組相連快取就是將cache平均分成2份,每份32 Bytes。如下圖所示。
cache分成2路,每路包含4行cache line。我們將所有索引一樣的cache line組合在一起稱之為組。例如,上圖一個組有兩個cache line,總共4個組。我們依然假設從位址0x0654位址讀取一個位元組資料。由於cache line size是8 Bytes,因此offset需要3 bits,這和之前直接映射快取一樣。不一樣的地方是index,在兩路組相連快取中,index只需要2 bits,因為一路只有4行cache line。
上面的範例根據index找到第2行cache line(從0開始計算),第2行對應2個cache line,分別對應way 0和way 1。因此index也可以稱作set index(群組索引)。先根據index找到set,然後將群組內的所有cache line對應的tag取出來和地址中的tag部分對比,如果其中一個相等就意味著命中。
因此,兩路組相連快取較直接對映快取最大的差異就是:第一個位址對應的資料可以對應2個cache line,而直接對應快取一個位址只對應一個cache line。那麼這究竟有什麼好處呢?
兩路組相連快取優缺點
兩路組相連快取的硬體成本相對於直接對映快取較高。因為其每次比較tag的時候需要比較多個cache line對應的tag(某些硬體可能還會做並行比較,增加比較速度,這就增加了硬體設計複雜度)。
為什麼我們還需要兩路組相連快取呢?因為其可以有助於降低cache顛簸可能性。那麼是如何降低的呢?根據兩路組相連快取的工作方式,我們可以畫出主記憶體位址0x00-0x4f位址對應的cache分佈圖。
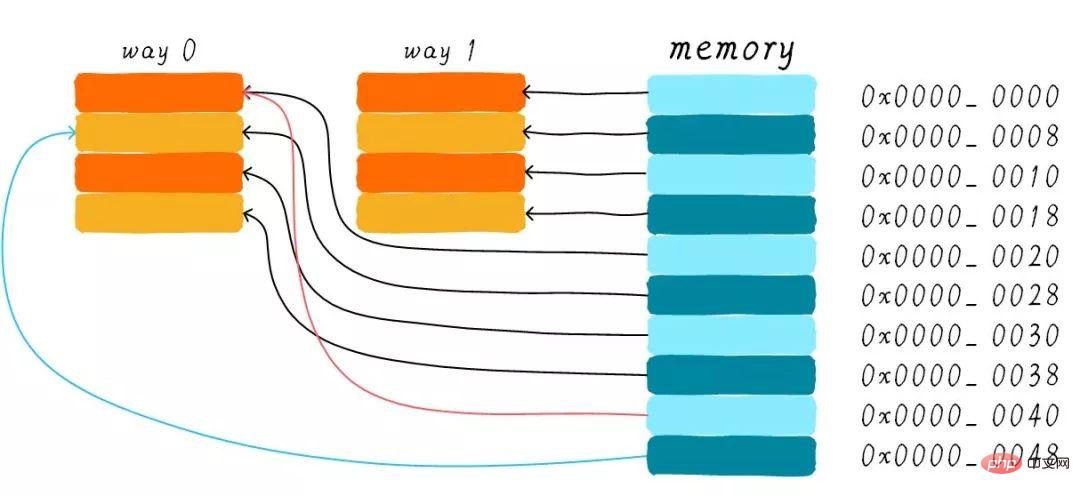
我們依然考慮直接對應快取一節的問題「如果一個程式試圖依序存取位址0x00、0x40、0x80,cache中的資料會發生什麼事呢?」。現在0x00位址的資料可以載入到way 1,0x40可以載入到way 0。這樣是不是就在某種程度上避免了直接映射快取的尷尬境地呢?在兩路組相連快取的情況下,0x00和0x40位址的資料都會快取在cache。試想一下,如果我們是4路組相連緩存,後面繼續訪問0x80,也可能被緩存。
因此,當cache size一定的情況下,群組相連快取對效能的提升最差情況下也和直接映射快取一樣,在大部分情況下群組相連快取效果比直接映射快取好。同時,其降低了cache顛簸的頻率。從某種程度上來說,直接映射快取是群組相連快取的特殊情況,每組只有一個cache line而已。因此,直接映射快取也可以稱作單路組連接快取。
全相連快取(Full associative cache)
#既然群組相連快取那麼好,如果所有的cache line都在一個群組內。豈不是性能更好。是的,這種快取就是全相連快取。我們依然以64 Byts大小cache為例說明。
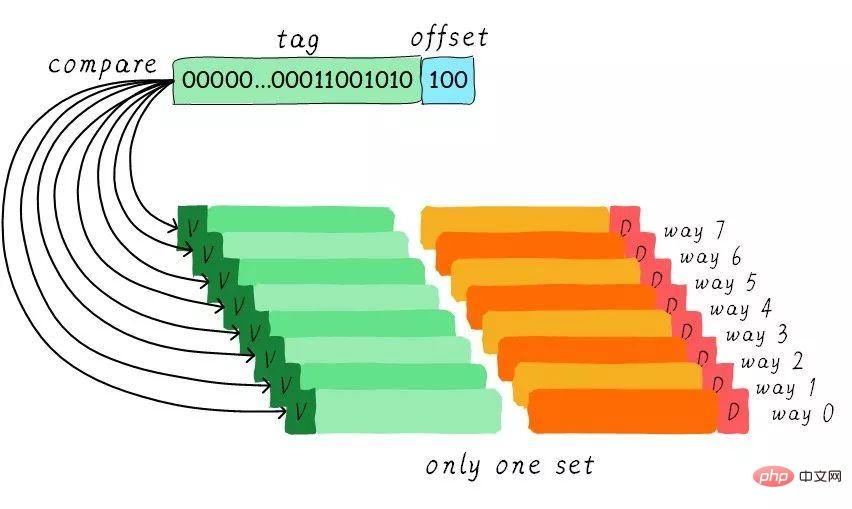
由於所有的cache line都在一個群組內,因此位址中不需要set index部分。因為,只有一個組讓你選擇,間接來說就是你沒得選。我們根據位址中的tag部分和所有的cache line對應的tag進行比較(硬體上可能並行比較也可能串行比較)。哪個tag比較相等,就意味著命中某個cache line。因此,在全相連快取中,任意位址的資料可以快取在任意的cache line中。所以,這可以最大程度的降低cache顛簸的頻率。但是硬體成本上也是更高。
一個四路組相連快取實例問題
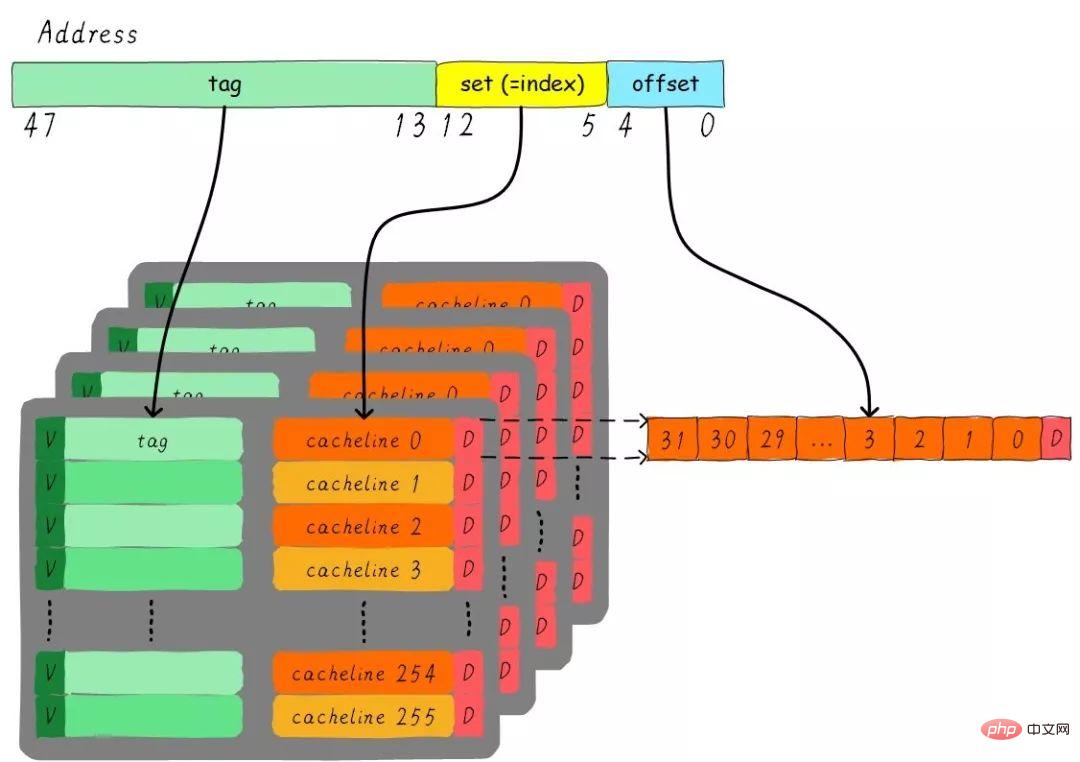
考慮這麼一個問題,32 KB大小4路組相連cache,cache line大小是32 Bytes。請思考一下問題:
1). 多少組? 2). 假設地址寬度是48 bits,index、offset以及tag分別佔用幾個bit?
總共4路,因此每路大小是8 KB。 cache line size是32 Bytes,因此總共有256組(8 KB / 32 Bytes)。由於cache line size是32 Bytes,所以offset需要5位元。一共256組,所以index需要8位,剩下的就是tag部分,佔用35位。這個cache可以繪製下圖表示。
Cache分配策略(Cache allocationpolicy)
cache的分配策略是指我們在什麼情況下應該為資料指派cache line。 cache分配策略分為讀取和寫入兩種情況。
讀取分配(read allocation):
當CPU讀取資料時,發生cache缺失,這種情況會分配一個cache line快取從主記憶體讀取的數據。預設情況下,cache都支援讀取分配。
寫入分配(write allocation):
#當CPU寫入資料發生cache缺失時,才會考慮寫入分配策略。當我們不支援寫入分配的情況下,寫指令只會更新主存數據,然後就結束了。當支援寫入分配的時候,我們先從主記憶體載入資料到cache line(相當於先做個讀取分配動作),然後會更新cache line中的資料。
Cache更新政策(Cache update policy)
cache更新政策是指發生cache命中時,寫入作業應該如何更新資料。 cache更新策略分成兩種:寫直通和回寫。
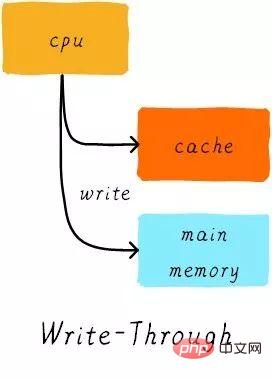
寫入直通(write through):
當CPU執行store指令並在cache命中時,我們更新cache中的資料並且更新主記憶體中的資料。 cache和主記憶體的資料始終保持一致。
寫回(write back):
當CPU執行store指令並在cache命中時,我們只更新cache中的數據。而每個cache line中會有一個bit位元記錄資料是否被修改過,稱為dirty bit(翻翻前面的圖片,cache line旁邊有一個D就是dirty bit)。我們會將dirty bit置位。主記憶體中的資料只會在cache line被取代或顯示clean操作時更新。因此,主記憶體中的數據可能是未修改的數據,而修改的數據躺在cache line中。
同時,為什麼cache line大小是cache控制器和主記憶體之間資料傳輸的最小單位呢?這也是因為每個cache line只有一個dirty bit。這一個dirty bit代表整個cache line時候被修改的狀態。
實例
假設我們有一個64 Bytes大小直接映射緩存,cache line大小是8 Bytes,採用寫分配和寫回機制。當CPU從位址0x2a讀取一個位元組,cache中的資料會如何改變呢?假設當前cache狀態如下圖所示。
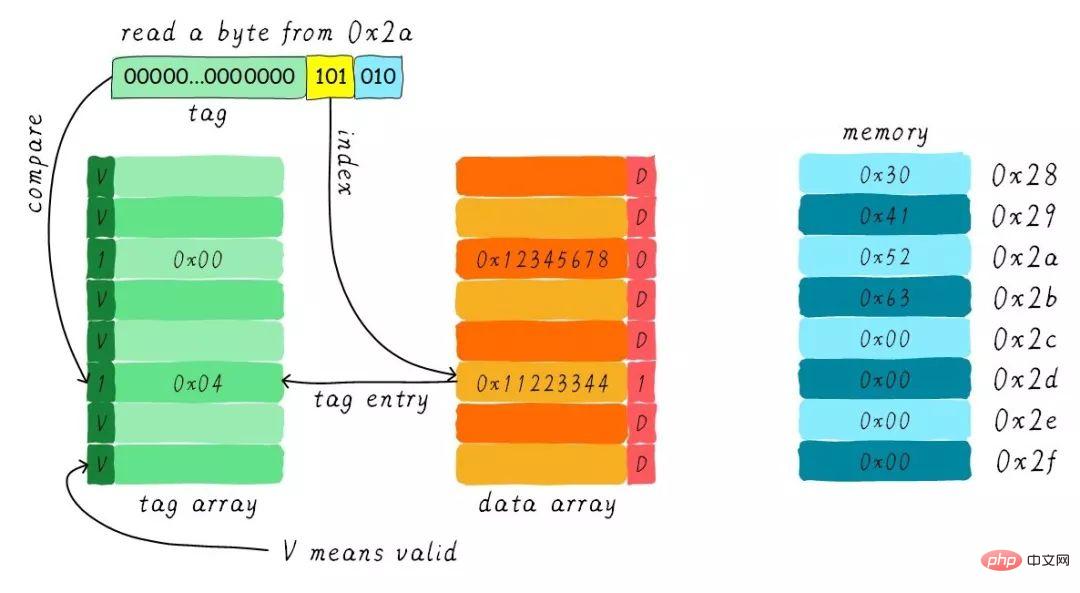
根據index找到對應的cache line,對應的tag部分valid bit是合法的,但tag的值不相等,因此發生缺失。此時我們需要從位址0x28位址載入8位元組資料到該cache line。但是,我們發現目前cache line的dirty bit置位。因此,cache line裡面的資料不能被簡單的丟棄,由於採用寫回機制,所以我們需要將cache中的資料0x11223344寫到位址0x0128位址(這個位址根據tag中的值及所處的cache line行計算得到)。這個過程如下圖所示。
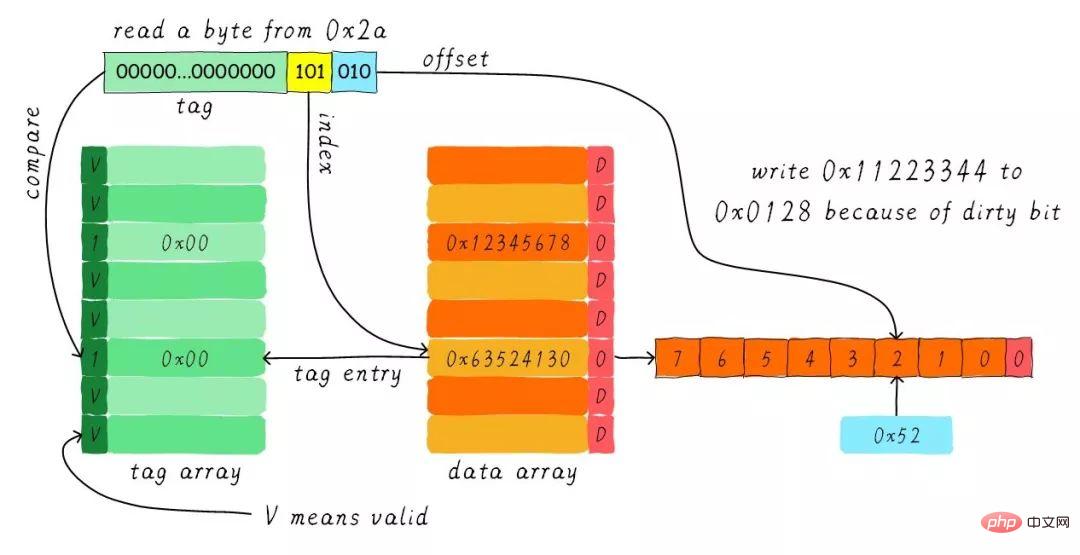
當寫回操作完成,我們將主記憶體中0x28位址開始的8個位元組載入到該cache line中,並清除dirty bit。然後根據offset找到0x52回傳給CPU。
感謝您的耐心閱讀,希望您能有所收穫。
本文轉載自蝸窩科技:http://www.wowotech.net/memory_management/458.html
推薦教學:《Linux運維》
以上是關於Linux的快取記憶體Cache Memory(圖文詳解)的詳細內容。更多資訊請關注PHP中文網其他相關文章!