
boosting和bootstrap差別

- (*-*)浩原創
- 2019-07-12 09:46:233420瀏覽
bootstrap、boosting是機器學習中幾種常用的重採樣方法。其中bootstrap重採樣方法主要用於統計量的估計,boosting方法則主要用於多個子分類器的組合。

bootstrap:估計統計量的重採樣方法(建議學習:Python影片教學)
bootstrap方法是從大小為n的原始訓練資料集DD中隨機選擇n個樣本點組成一個新的訓練集,這個選擇過程獨立重複B次,然後用這B個資料集對模型統計量進行估計(如平均值、變異數等)。由於原始資料集的大小就是n,所以這B個新的訓練集中不可避免的會存在重複的樣本。
統計量的估計值定義為獨立的B個訓練集上的估計值θbθb的平均值:
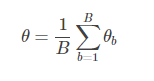
##boosting:
boosting依序訓練k個子分類器,最終的分類結果由這些子分類器投票決定。 先從大小為n的原始訓練資料集中隨機選取n1n1個樣本訓練出第一個分類器,記為C1C1,然後建構第二個分類器C2C2的訓練集D2D2,要求:D2D2中一半樣本能被C1C1正確分類,另一半樣本則被C1C1錯分。 接著繼續建構第三個分類器C3C3的訓練集D3D3,要求:C1C1、C2C2對D3D3中樣本的分類結果不同。剩餘的子分類器依照類似的思路進行訓練。 boosting建構新訓練集的主要原則是使用最豐富資訊的樣本。Python教學欄位進行學習!
以上是boosting和bootstrap差別的詳細內容。更多資訊請關注PHP中文網其他相關文章!
陳述:
本文內容由網友自願投稿,版權歸原作者所有。本站不承擔相應的法律責任。如發現涉嫌抄襲或侵權的內容,請聯絡admin@php.cn
上一篇:python函式庫是什麼意思下一篇:python函式庫是什麼意思