
Java中JVM字節碼的詳細介紹

- 不言轉載
- 2018-10-10 11:43:243559瀏覽
這篇文章帶給大家的內容是關於Java中JVM字節碼的詳細介紹,有一定的參考價值,有需要的朋友可以參考一下,希望對你有幫助。
這是Java基礎篇(JVM)的文章,本來想先說說Java類別載入機制的,後來想想,JVM的作用是載入編譯器編譯好的字節碼,並解釋成機器碼,那麼首先應該了解字節碼,然後再談加載字節碼的類別加載機制似乎會好些,所以這篇改成詳解字節碼。
由於Java純粹物件導向的特性,字節碼只要能表示一個類別的訊息,就可以表示整個Java程式了,JVM只要能載入一個類別的信息,就能載入整個程式了。所以,不管是字節碼,還是JVM載入機制,關注點都是在類別中。我關注的點主要在於:
1. 由於字節碼不是一次性全部加載進入內存,那麼JVM是如何知道自己要加載的類信息在.class文件的哪個位置的?
2. 字節碼是如何表示類別資訊的?
3. 字節碼會進行程式的最佳化嗎?
第一個問題很簡單,因為即使一個原始檔案有很多個類別(只有一個public類別),編譯器也會為其中每個類別產生一個.class文件,JVM載入時依照需要載入的類別名稱載入即可。
要解決後面的問題,首先我們來看字節碼的組成(Mac下用Hex Fiend開啟)。
對這樣一段程式碼:
package com.test.main1;
public class ByteCodeTest {
int num1 = 1;
int num2 = 2;
public int getAdd() {
return num1 + num2;
}
}
class Extend extends ByteCodeTest {
public int getSubstract() {
return num1 - num2;
}
}我們來分析其中的Extend類別。
用Hex Fiend開啟編譯後的.class檔案是這樣的(16進位代碼):
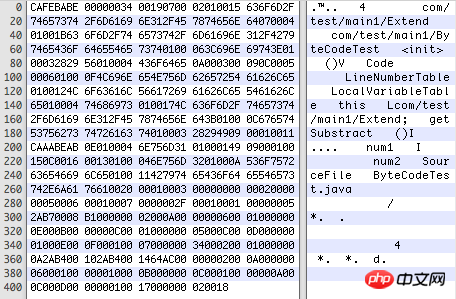
由於class檔案沒有分隔符,所以每個位置代表什麼、各部分的長度等格式是嚴格規定死的,見下表:
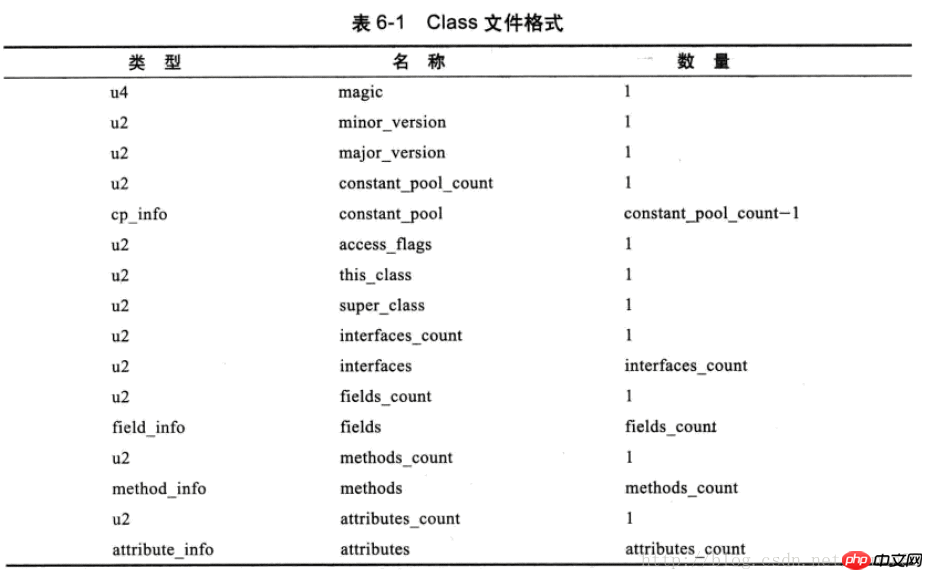
其中u1、u2、u4、u8代表幾個位元組的無符號數,在反編譯出來的16進位檔案中,兩個數字代表一個位元組,也就是u1。
從頭到尾一項一項地看:
(1)magic:u4,魔數,代表本檔案是.class檔案。 .jpg等也會有這種魔數,正因為魔數存在,即使將*.jpg改成*.123,也能照常打開。
(2)minor version、major version:各u2,版本號,向下相容,即高版本JDK可以使用低版本的.class文件,反之不行。
(3)constant_pool_count:u2,常數池中常數的數量,0019代表有24個。
(4)接下來就是具體的常數,共constant_pool_count-1個。
常數池通常存兩種類型的資料:
字面量:如字串、final修飾的常數等;
符號引用:如類別/介面的全限定名、方法的名稱和描述、欄位的名稱和描述等。
根據反編譯出來的數字,先查下表得到該常數的型別和長度,接下來的與查得的長度相等的數字則表示該常數具體的值。
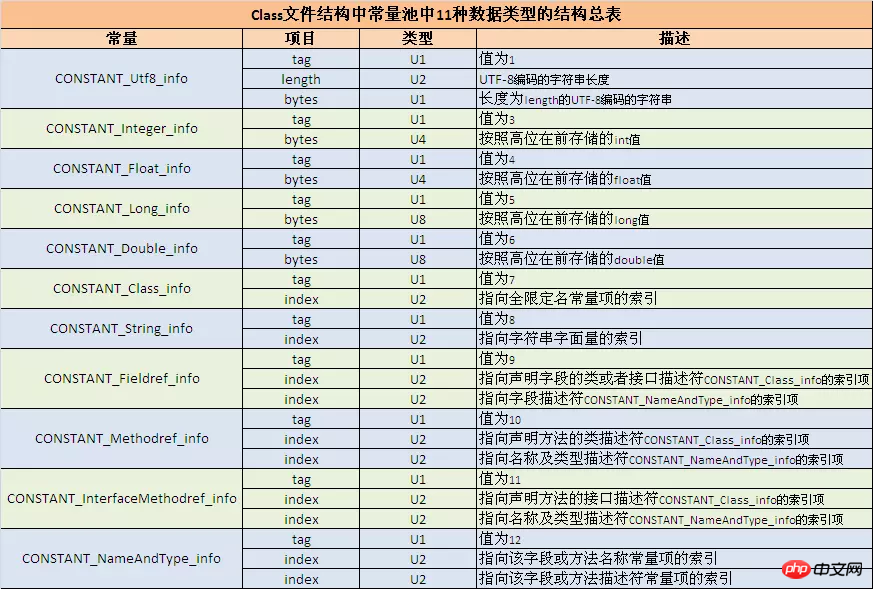
如070002,就表示該種型別為CONSTANT_Class_info,它的tag為u1,且接下來u2長度為index指向全限定名常數項的索引。這個索引還要結合javap -verbose打開的class檔案一起看,這裡清楚地列出了常數池中的內容和順序:
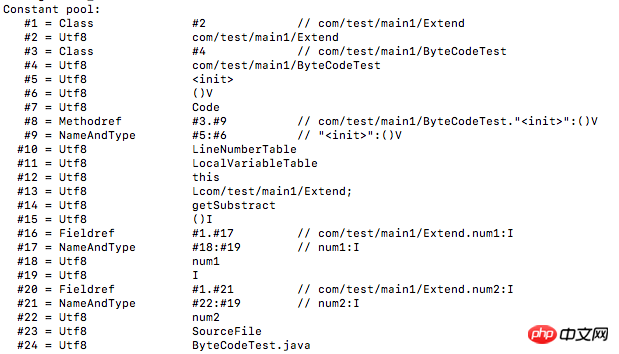
在這裡可以看到0002索引項的常數為:com/test/main1/Extend,是類別的全限定名稱。如果是值是字串,那麼就需要根據該值轉換成十進位並查ASCII碼表得到具體的字元。接下來的常數都照此分析:
01001563 6F6D2F74 6573742F 6D61696E 312F4578 74656E64:com/test/main1/Extend
#070004:com/# 01001B63 6F6D2F74 6573742F 6D61696E 312F4279 7465436F 64655465 7374:com/test/main1/ByteCodeTest
#1010096301096; 01000328 2956:()V#01000443 6F6465 :Code0A000300 09:com/test/main1/ByteCodeTest、"7e51f00a783d7eb8f68358439dee7daf":()V#0C000500 06:7e51f00a783d7eb8f68358439dee7daf、()V0C000500 06:7e51f00a783d7eb8f68358439dee7daf、()V
##01000F4C 696E654E 756D6265 72546162 6C65:LineNumberTable
0100124C 6F63616C 56617269 61626C65 563616C 56617269 61626C65 5636126006467260000 86973:this
0100174C 636F6D2F 74657374 2F6D6169 6E312F45 7874656E 643B:Lcom/test /main1/Extend;
01000C67 65745375 62737472 616374:getSubstract
01000328 2949:()I
09000100 111:com/#1890001
##0C001200 13:num1、I0100046E 756D31:num101000149:I09000100 15:com/test/main1/Extend、num2:I 0C001600 13:num2、I0100046E 756D32:num201000A53 6F757263 6546696C 65:SourceFile01001142 79746543 6F646554 6573742E 6A617661:ByteCodeTest.java
至此,常數池中的常數全數解析完畢。
(5)再接下來是u2的access_flags:access_flags存取標誌的主要目的是標記該類別是類別還是接口,如果是類,存取權限是否為public,是否是abstract,是否被標誌為final等,請見下表:
| Flag_name | Value | ##Interpretation |
| ACC_PUBLIC | 0x0001 | |
| 表示存取權限為public,可以從本包外存取 | ||
| #ACC_FINAL | 0x0010 | 表示由final修飾,不允許有子類別 |
| #ACC_SUPER | ||
| # #0x0020 | 較為特殊,表示動態綁定直接父類,請參閱下方的解釋 | |
| 0x0200 | 表示接口,非類別 | ACC_ABSTRACT |
| 0x0400 | 表示抽象類,不能實例化 | ACC_SYNTHETIC |
| 0x1000 | 表示由synthetic修飾,不在原始碼中出現,見附錄[2] |
所以,本类中的access_flags是0020,表示这个Extend类调用父类的方法时,并非是编译时绑定,而是在运行时搜索类层次,找到最近的父类进行调用。这样可以保证调用的结果是一定是调用最近的父类,而不是编译时绑定的父类,保证结果的正确性。
(6)this_class:u2的类索引,用于确定类的全限定名。本类的this_class是0001,表示在常量池中#1索引,是com/test/main1/Extend
(7)super_class:u2的父类索引,用于确定直接父类的全限定名。本类是0003,#3是com/test/main1/ByteCodeTest
(8)interfaces_count:u2,表示当前类实现的接口数量,注意是直接实现的接口数量。本类中是0000,表示没有实现接口。
(9)Interfaces:表示接口的全限定名索引。每个接口u2,共interfaces_count个。本类为空。
(10)fields_count:u2,表示类变量和实例变量总的个数。本类中是0000,无。
(11)fields:fileds的长度为filed_info,filed_info是一个复合结构,组成如下:
filed_info: {
u2 access_flags;
u2 name_index;
u2 descriptor_index;
u2 attributes_count;
attribute_info attributes[attributes_count];
}由于本类无类变量和实例变量,故本字段为空。
(12)methods_count:u2,表示方法个数。本类中是0002,表示有2个。
(13)methods:methods的长度为一个method_info结构:
method_info {
u2 access_flags; 0000 ?
u2 name_index; 0005 <init>
u2 descriptor_index; 0006 ()V
u2 attributes_count; 0001 1个
attribute_info attributes[attributes_count]; 0007 Code
}其中attribute_info结构如下:
attribute_info {
u2 attribute_name_index; 0007 Code
u1 attribute_length;
u1 info[attribute_length];
}上面是通用的attribute_info的定义,另外,JVM里预定义了几种attribute,Code即是其中一种(注意,如果使用的是JVM预定义的attribute,则attribute_info的结构就按照预定义的来),其结构如下:
Code_attribute { //Code_attribute包含某个方法、实例初始化方法、类或接口初始化方法的Java虚拟机指令及相关辅助信息
u2 attribute_name_index; 0007 Code
u4 attribute_length; 0000002F 47
u2 max_stack; 0001 1 //用来给出当前方法的操作数栈在方法执行的任何时间点的最大深度
u2 max_locals; 0001 1 //用来给出分配在当前方法引用的局部变量表中的局部变量个数
u4 code_length; 00000005 5 //给出当前方法code[]数组的字节数
u1 code[code_length]; 2AB70008 B1 42、183、0、8、177
//给出了实现当前方法的Java虚拟机代码的实际字节内容 (这些数字代码实际对应一些Java虚拟机的指令)
u2 exception_table_lentgh; 0000 0 //异常的信息
{
u2 start_pc; //这两项的值表明了异常处理器在code[]中的有效范围,即异常处理器x应满足:start_pc≤x≤end_pc
u2 end_pc; //start_pc必须在code[]中取值,end_pc要么在code[]中取值,要么等于code_length的值
u2 handler_pc; //表示一个异常处理器的起点
u2 catch_type; //表示当前异常处理器需要捕捉的异常类型。为0,则都调用该异常处理器,可用来实现finally。
} exception_table[exception_table_lentgh]; 在本类中大括号里的结构为空
u2 attribute_count; 0002 2 表示该方法的其它附加属性,本类有1个
attribute_info attributes[attributes_count]; 000A、000B LineNumberTable、LocalVariableTable
}LineNumberTable和LocalVariableTable又是两个预定义的attribute,其结构如下:
LineNumberTable_attribute { //被调试器用来确定源文件中由给定的行号所表示的内容,对应于Java虚拟机code[]数组的哪部分
u2 attribute_name_index; 000A
u4 attribute_length; 00000006
u2 line_number_table_length; 0001
{ u2 start_pc; 0000
u2 line_number; 000E //该值必须与源文件中对应的行号相匹配
} line_number_table[line_number_table_length];
}以及:
LocalVariableTable_attribute {
u2 attribute_name_index; 000B
u4 attribute_length; 0000000C
u2 local_variable_table_length; 0001
{ u2 start_pc; 0000
u2 length; 0005
u2 name_index; 000C
u2 descriptor_index; 000D //用来表示源程序中局部变量类型的字段描述符
u2 index; 0000
} local_variable_table[local_variable_table_length];然后就是第二个方法,具体略过。
(14)attributes_count:u2,这里的attribute表示整个class文件的附加属性,和前面方法的attribute结构相同。本类中为0001。
(15)attributes:class文件附加属性,本类中为0017,指向常量池#17,为SourceFile,SourceFile的结构如下:
SourceFile_attribute {
u2 attribute_name_index; 0017 SourceFile
u4 attribute_length; 00000002 2
u2 sourcefile_index; 0018 ByteCodeTest.java //表示本class文件是由ByteCodeTest.java编译来的
}嗯,字节码的内容大概就写这么多。可以看到通篇文章基本都是在分析字节码文件的16进制代码,所以可以这么说,字节码的核心在于其16进制代码,利用规范中的规则去解析这些代码,可以得出关于这个类的全部信息,包括:
1. 这个类的版本号;
2. 这个类的常量池大小,以及常量池中的常量;
3. 这个类的访问权限;
4. 这个类的全限定名、直接父类全限定名、类的直接实现的接口信息;
5. 这个类的类变量和实例变量的信息;
6. 这个类的方法信息;
7. 其它的这个类的附加信息,如来自哪个源文件等。
解析完字节码,回头再来看开始提出的问题,也就迎刃而解了。由于字节码文件格式严格按照规定,可以用来表示类的全部信息;字节码只是用来表示类信息的,不会进行程序的优化。
那么在编译期间,编译器会对程序进行优化吗?运行期间JVM会吗?什么时候进行的,按照什么原则呢?这个留作以后再表。
最后,值得注意的是,字节码不仅是平台无关的(任何平台生成的字节码都可以在任何的JRE环境运行),还是语言无关的,不仅Java可以生成字节码,其它语言如Groovy、Jython、Scala等也能生成字节码,运行在JRE环境中。
以上是Java中JVM字節碼的詳細介紹的詳細內容。更多資訊請關注PHP中文網其他相關文章!