
python爬蟲中http和https協議的詳細講解(圖文)

- 不言原創
- 2018-09-15 15:02:443007瀏覽
這篇文章帶給大家的內容是關於python爬蟲中http和https協議的詳細講解(圖文) ,有一定的參考價值,有需要的朋友可以參考一下,希望對你有所幫助。
一.HTTP協定
1.官方概念:
HTTP協定是Hyper Text Transfer Protocol(超文本傳輸協定)的縮寫,是用於從萬維網(WWW:World Wide Web )伺服器傳輸超文本到本機瀏覽器的傳送協定。 (雖然童鞋們將這條概念都看爛了,但是也沒辦法,畢竟這就是HTTP的權威官方的概念解釋,要想徹底理解,請客觀目移下側......)
2.白話概念:
HTTP協定就是伺服器(Server)和客戶端(Client)之間進行資料互動(相互傳輸資料)的一種形式。我們可以將Server和Client進行擬人化,那麼該協定就是Server和Client這兩兄弟間指定的一種互動溝通方式。
3.HTTP運作原理:
HTTP協定工作於客戶端-服務端架構為上。瀏覽器以HTTP客戶端透過URL向HTTP服務端即WEB伺服器傳送所有請求。 Web伺服器根據接收到的請求後,向客戶端發送回應訊息。
# 4.HTTP四點注意事項: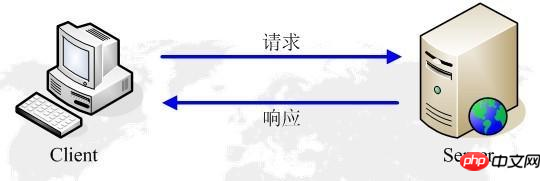 - HTTP允許傳輸任意類型的資料物件。正在傳輸的類型由Content-Type加以標記。 - HTTP是無連線:無連線的意思是限制每次連線只處理一個請求。伺服器處理完客戶的請求,並收到客戶的應答後,即斷開連線。採用這種方式可以節省傳輸時間。 - HTTP是媒體獨立的:這意味著,只要客戶端和伺服器知道如何處理的資料內容,任何類型的資料都可以透過HTTP發送。客戶端以及伺服器指定使用適合的MIME-type內容類型。 - HTTP是無狀態:HTTP協定是無狀態協定。無狀態是指協議對於事務處理沒有記憶能力。缺少狀態意味著如果後續處理需要前面的訊息,則它必須重傳,這可能導致每次連接傳送的資料量增加。另一方面,在伺服器不需要先前資訊時它的應答就較快。
- HTTP允許傳輸任意類型的資料物件。正在傳輸的類型由Content-Type加以標記。 - HTTP是無連線:無連線的意思是限制每次連線只處理一個請求。伺服器處理完客戶的請求,並收到客戶的應答後,即斷開連線。採用這種方式可以節省傳輸時間。 - HTTP是媒體獨立的:這意味著,只要客戶端和伺服器知道如何處理的資料內容,任何類型的資料都可以透過HTTP發送。客戶端以及伺服器指定使用適合的MIME-type內容類型。 - HTTP是無狀態:HTTP協定是無狀態協定。無狀態是指協議對於事務處理沒有記憶能力。缺少狀態意味著如果後續處理需要前面的訊息,則它必須重傳,這可能導致每次連接傳送的資料量增加。另一方面,在伺服器不需要先前資訊時它的應答就較快。
5.HTTP之URL:
HTTP使用統一資源識別碼(Uniform Resource Identifiers, URI)來傳輸資料和建立連線。 URL是一種特殊類型的URI,包含了用於查找某個資源的足夠的信息
URL,全稱是UniformResourceLocator, 中文叫統一資源定位符,是互聯網上用來標識某一處資源的地址。以下面這個URL為例,介紹下普通URL的各部分組成:http://www.aspxfans.com:8080/news/index.asp?boardID=5&ID=24618&page=1#name從上面的URL可以看出,一個完整的URL包括以下幾部分:
- 協定部分:該URL的協定部分為“http:”,這代表網頁使用的是HTTP協定。在Internet中可以使用多種協議,如HTTP,FTP等等本例中使用的是HTTP協定。在"HTTP"後面的「//」為分隔符號
- 網域部分:該URL的網域部分為「www.aspxfans.com」。在一個URL中,也可以使用IP位址作為網域名稱使用
- 埠部分:跟在網域後面的是端口,網域名稱和連接埠之間使用「:」作為分隔符號。連接埠不是一個URL必須的部分,如果省略連接埠部分,將採用預設連接埠
- 虛擬目錄部分:從網域後的第一個「/」開始到最後一個「/」為止,就是虛擬目錄部分。虛擬目錄也不是一個URL必須的部分。本範例中的虛擬目錄是「/news/」
- 檔案名稱部分:從網域後的最後一個「/」開始到「?」為止,是檔案名稱部分,如果沒有「?」,則是從網域後的最後一個“/”開始到“#”為止,是檔案部分,如果沒有“?”和“#”,那麼從網域後的最後一個“/”開始到結束,都是檔名部分。本例中的檔案名稱是“index.asp”。檔案名稱部分也不是一個URL必須的部分,如果省略該部分,則使用預設的檔案名稱
- 錨部分:從「#」開始到最後,都是錨部分。本例中的錨部分是“name”。錨部分也不是一個URL必須的部分
- 參數部分:從「?」開始到「#」為止之間的部分為參數部分,又稱搜尋部分、查詢部分。本例中的參數部分為「boardID=5&ID=24618&page=1」。參數可以允許有多個參數,參數與參數之間以“&”作為分隔符號。
6.HTTP之Request:
客戶端發送一個HTTP請求到伺服器的請求訊息包含以下組成部分:
##封包頭:常被稱為請求頭,請求頭中儲存的是該請求的一些主要說明(自我介紹)。伺服器據此取得客戶端的資訊。
常見的請求頭:
accept:瀏覽器透過這個頭告訴伺服器,它所支援的資料類型
Accept-Charset: 瀏覽器透過這個頭告訴伺服器,它支援哪種字元集
Accept-Encoding:瀏覽器透過這個頭告訴伺服器,支援的壓縮格式
Accept-Language:瀏覽器透過這個頭告訴伺服器,它的語言環境
Host:瀏覽器透過這個頭告訴伺服器,想存取哪台主機
If-Modified-Since: 瀏覽器透過這個頭告訴伺服器,快取資料的時間
Referer:瀏覽器透過這個頭告訴伺服器,客戶機是哪個頁面來的 防盜鏈
Connection:瀏覽器透過這個頭告訴伺服器,請求完後是斷開連結還是何持連結
X-Requested-With: XMLHttpRequest 代表透過ajax方式進行存取
#User-Agent:請求載體的身份識別
封包文體:常被稱為請求體,請求體中儲存的是將要傳輸/傳送給伺服器的資料訊息。
7.HTTP之Response:
伺服器回傳一個HTTP回應到客戶端的回應訊息包含以下組成部分:

#狀態碼:以「清晰明確」的語言告訴客戶端本次請求的處理結果。
HTTP的回應狀態碼由5段組成:
1xx 訊息,一般是告訴客戶端,請求已經收到了,正在處理,別急...
2xx 處理成功,一般表示:請求收悉、我明白你要的、請求已受理、已經處理完成等信息.
3xx 重定向到其它地方。它讓客戶端再發起一個請求以完成整個處理。
4xx 處理發生錯誤,責任在客戶端,如客戶端的請求一個不存在的資源,客戶端未被授權,禁止存取等。
5xx 處理發生錯誤,責任在服務端,如服務端拋出異常,路由出錯,HTTP版本不支援等。
對應頭:回應的詳情顯示
常見的對應頭資訊:
Location: 伺服器透過這個頭,來告訴瀏覽器跳到哪裡
Server:伺服器通過這個頭,告訴瀏覽器伺服器的型號
Content-Encoding:伺服器透過這個頭,告訴瀏覽器,資料的壓縮格式
Content-Length: 伺服器透過這個頭,告訴瀏覽器回送資料的長度
Content-Language: 伺服器透過這個頭,告訴瀏覽器語言環境
Content-Type:伺服器透過這個頭,告訴瀏覽器回送資料的類型
Refresh:伺服器透過這個頭,告訴瀏覽器定時刷新
Content-Disposition: 伺服器透過這個頭,告訴瀏覽器以下載方式打資料
Transfer-Encoding:伺服器透過這個頭,告訴瀏覽器資料是以分塊方式回傳的
Expires: - 1 控制瀏覽器不要快取
Cache-Control: no-cache
Pragma: no-cache
對應體:根據客戶端指定的請求訊息,傳送給客戶端的指定資料
二.HTTPS協議
1.官方概念:
HTTPS (Secure Hypertext Transfer Protocol)安全超文本傳輸協議,HTTPS是在HTTP上建立SSL加密層,並對傳輸資料進行加密,是HTTP協定的安全版。
2.白話概念:
加密安全版的HTTP協定。
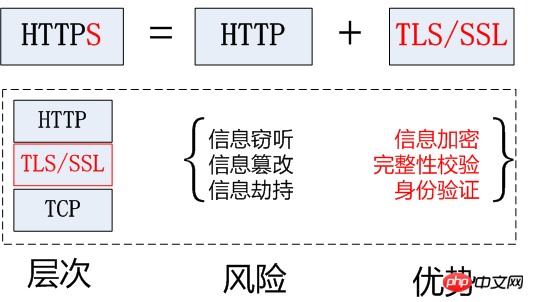
3.HTTPS採用的加密技術
3.1 SSL加密技術
SSL採用的加密技術稱為「共享加密」 ,也叫作“對稱金鑰加密”,這種加密方法是這樣的,例如客戶端向伺服器發送一條訊息,首先客戶端會採用已知的演算法對訊息進行加密,例如MD5或Base64加密,接收端加密的資訊解密的時候需要用到金鑰,中間會傳遞金鑰,(加密和解密的金鑰是同一個),金鑰在傳輸中間是被加密的。這種方式看起來安全,但是仍有潛在的危險,一旦被竊聽,或者資訊被挾持,就有可能破解密鑰,而破解其中的資訊。因此「共享金鑰加密」這種方式有安全隱患:
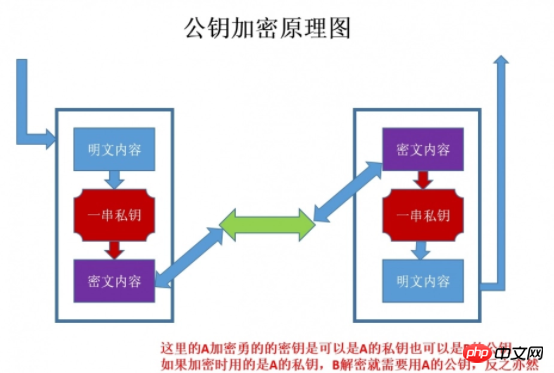
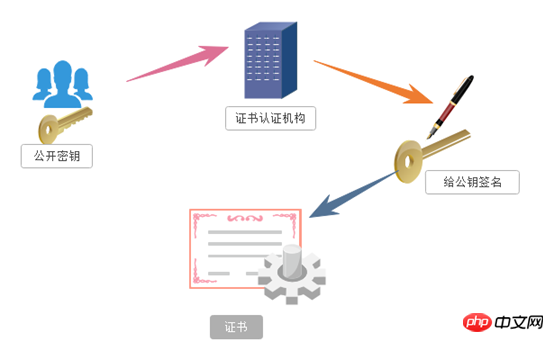
“非對稱加密”使用的時候有兩把鎖,一把叫做“私有密鑰”,一把是“公開密鑰”,使用非物件加密的加密方式的時候,伺服器首先告訴客戶端按照自己給定的公開密鑰進行加密處理,客戶端按照公開密鑰加密以後,伺服器接受到資訊再透過自己的私有密鑰進行解密,這樣做的好處就是解密的鑰匙根本就不會進行傳輸,因此也就避免了被挾持的風險。就算公開金鑰被竊聽者拿到了,它也很難進行解密,因為解密過程是對離散對數求值,這可不是輕易就能做到的事。以下是不對稱加密的原理圖:

但對不對稱秘鑰加密技術也存在如下
以上是python爬蟲中http和https協議的詳細講解(圖文)的詳細內容。更多資訊請關注PHP中文網其他相關文章!