
node如何爬取網頁中的圖片(附程式碼)

- 不言原創
- 2018-08-17 15:45:202855瀏覽
這篇文章帶給大家的內容是關於node如何爬取網頁中的圖片(附程式碼),有一定的參考價值,有需要的朋友可以參考一下,希望對你有幫助。
目錄
安裝node,並下載依賴
建置服務
-
#請求我們要爬取的頁面,返回json
安裝node
我們開始安裝node,可以去node官網下載https://nodejs. org/zh-cn/,下載完成後執行node使用,
node -v
安裝成功後會出現你所安裝的版本號碼。
接下來我們使用node, 列印出hello world,新一個名為index.js檔案輸入
#console.log('hello world')
運行這個檔案
node index.js
就會在控制面板上輸出hello world
建置伺服器
新建一個·名為node的資料夾。
首先你需要下載express依賴
npm install express
再新建一個名為demo.js的檔案目錄結構如圖:

const express = require('express');
const app = express();
app.get('/index', function(req, res) {
res.end('111')
})
var server = app.listen(8081, function() {
var host = server.address().address
var port = server.address().port
console.log("应用实例,访问地址为 http://%s:%s", host, port)
})運行node demo.js簡單的服務就搭起來了,如圖: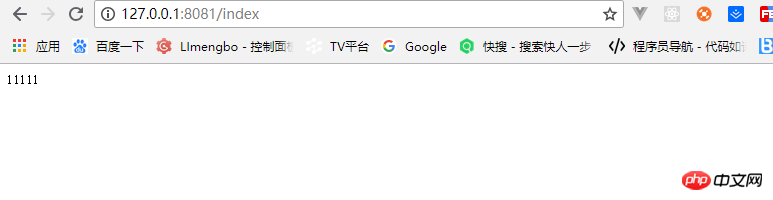
npm install superagent npm install superagent-charset npm install cheeriosuperagent 是用來發起請求的,是一個輕量的,漸進式的ajax api,可讀性好,學習曲線低,內部依賴nodejs原生的請求api,適用於nodejs環境下.,也可以使用http發起請求superagent-charset防止爬取下來的資料亂碼,更改字元格式cheerio為伺服器特別定制的,快速、靈活、實施的jQuery核心實作.。安裝完依賴就可以引入了
var superagent = require('superagent'); var charset = require('superagent-charset'); charset(superagent); const cheerio = require('cheerio');引入之後就請求我們的地址,https://www.qqtn.com/tx/weixintx_1.html,如圖:
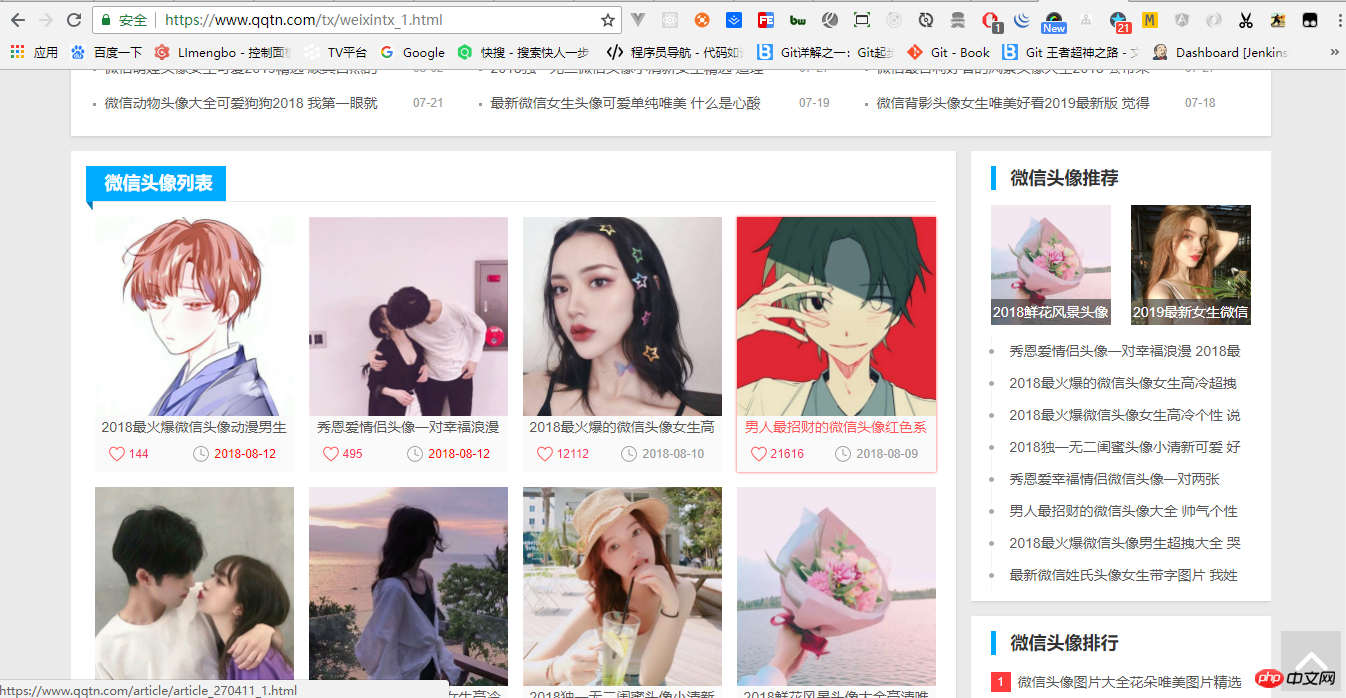
const baseUrl = 'https://www.qqtn.com/'###這些設定完之後就是發請求了,接下來請看完整程式碼demo.js###
var superagent = require('superagent');
var charset = require('superagent-charset');
charset(superagent);
var express = require('express');
var baseUrl = 'https://www.qqtn.com/'; //输入任何网址都可以
const cheerio = require('cheerio');
var app = express();
app.get('/index', function(req, res) {
//设置请求头
res.header("Access-Control-Allow-Origin", "*");
res.header('Access-Control-Allow-Methods', 'PUT, GET, POST, DELETE, OPTIONS');
res.header("Access-Control-Allow-Headers", "X-Requested-With");
res.header('Access-Control-Allow-Headers', 'Content-Type');
//类型
var type = req.query.type;
//页码
var page = req.query.page;
type = type || 'weixin';
page = page || '1';
var route = `tx/${type}tx_${page}.html`
//网页页面信息是gb2312,所以chaeset应该为.charset('gb2312'),一般网页则为utf-8,可以直接使用.charset('utf-8')
superagent.get(baseUrl + route)
.charset('gb2312')
.end(function(err, sres) {
var items = [];
if (err) {
console.log('ERR: ' + err);
res.json({ code: 400, msg: err, sets: items });
return;
}
var $ = cheerio.load(sres.text);
$('div.g-main-bg ul.g-gxlist-imgbox li a').each(function(idx, element) {
var $element = $(element);
var $subElement = $element.find('img');
var thumbImgSrc = $subElement.attr('src');
items.push({
title: $(element).attr('title'),
href: $element.attr('href'),
thumbSrc: thumbImgSrc
});
});
res.json({ code: 200, msg: "", data: items });
});
});
var server = app.listen(8081, function() {
var host = server.address().address
var port = server.address().port
console.log("应用实例,访问地址为 http://%s:%s", host, port)
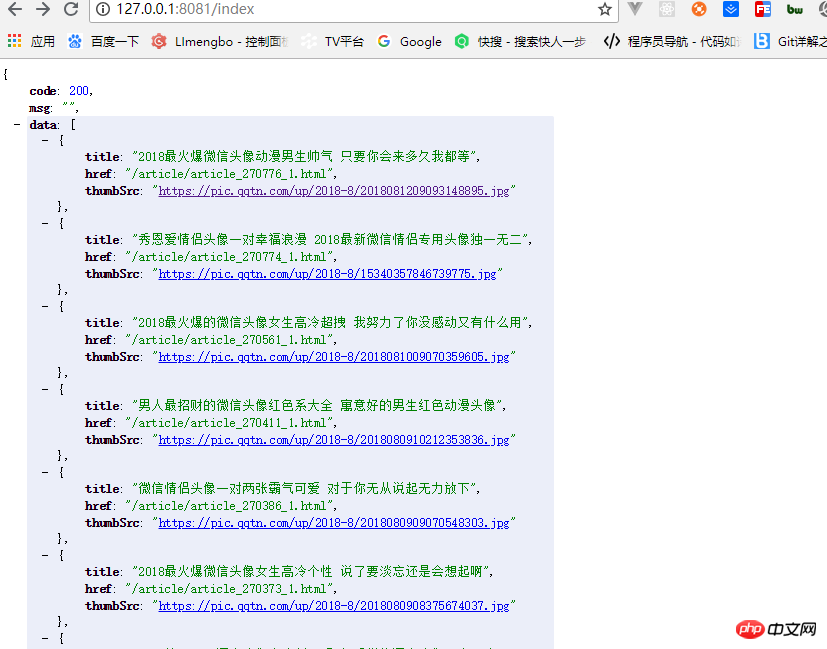
})###執行demo.js就會回傳我們拿到的數據,如圖:###############一個簡單的node爬蟲就完成了。 ######相關推薦:#########node爬蟲之gbk網頁中文亂碼解決方案_html/css_WEB-ITnose###############node下的http小爬蟲的範例程式碼分享#######以上是node如何爬取網頁中的圖片(附程式碼)的詳細內容。更多資訊請關注PHP中文網其他相關文章!
陳述:
本文內容由網友自願投稿,版權歸原作者所有。本站不承擔相應的法律責任。如發現涉嫌抄襲或侵權的內容,請聯絡admin@php.cn