
用TensorFlow實作戴明迴歸演算法的範例

- 不言原創
- 2018-05-02 13:55:082492瀏覽
這篇文章主要介紹了關於用TensorFlow實現戴明回歸演算法的範例,有著一定的參考價值,現在分享給大家,有需要的朋友可以參考一下
如果最小二乘線性迴歸演算法最小化到迴歸直線的垂直距離(即,平行於y軸方向),則戴明迴歸最小化到迴歸直線的總距離(即,垂直於迴歸直線)。其最小化x值和y值兩個方向的誤差,具體的比較圖如下圖。
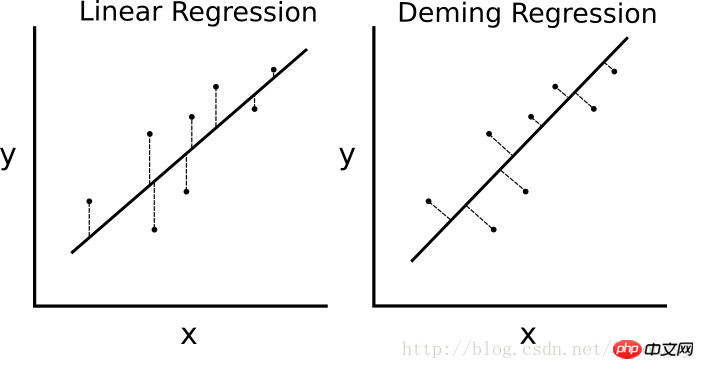
線性迴歸演算法與戴明迴歸演算法的差異。左邊的線性迴歸最小化到迴歸直線的垂直距離;右邊的戴明迴歸最小化到迴歸直線的總距離。
線性迴歸演算法的損失函數最小化垂直距離;而這裡需要最小化總距離。給定直線的斜率和截距,則求解一個點到直線的垂直距離有已知的幾何公式。代入幾何公式並使TensorFlow最小化距離。
損失函數是由分子和分母組成的幾何公式。給定直線y=mx b,點(x0,y0),求兩者間的距離的公式為:
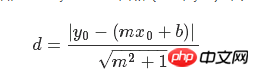
# 戴明回归
#----------------------------------
#
# This function shows how to use TensorFlow to
# solve linear Deming regression.
# y = Ax + b
#
# We will use the iris data, specifically:
# y = Sepal Length
# x = Petal Width
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from sklearn import datasets
from tensorflow.python.framework import ops
ops.reset_default_graph()
# Create graph
sess = tf.Session()
# Load the data
# iris.data = [(Sepal Length, Sepal Width, Petal Length, Petal Width)]
iris = datasets.load_iris()
x_vals = np.array([x[3] for x in iris.data])
y_vals = np.array([y[0] for y in iris.data])
# Declare batch size
batch_size = 50
# Initialize placeholders
x_data = tf.placeholder(shape=[None, 1], dtype=tf.float32)
y_target = tf.placeholder(shape=[None, 1], dtype=tf.float32)
# Create variables for linear regression
A = tf.Variable(tf.random_normal(shape=[1,1]))
b = tf.Variable(tf.random_normal(shape=[1,1]))
# Declare model operations
model_output = tf.add(tf.matmul(x_data, A), b)
# Declare Demming loss function
demming_numerator = tf.abs(tf.subtract(y_target, tf.add(tf.matmul(x_data, A), b)))
demming_denominator = tf.sqrt(tf.add(tf.square(A),1))
loss = tf.reduce_mean(tf.truep(demming_numerator, demming_denominator))
# Declare optimizer
my_opt = tf.train.GradientDescentOptimizer(0.1)
train_step = my_opt.minimize(loss)
# Initialize variables
init = tf.global_variables_initializer()
sess.run(init)
# Training loop
loss_vec = []
for i in range(250):
rand_index = np.random.choice(len(x_vals), size=batch_size)
rand_x = np.transpose([x_vals[rand_index]])
rand_y = np.transpose([y_vals[rand_index]])
sess.run(train_step, feed_dict={x_data: rand_x, y_target: rand_y})
temp_loss = sess.run(loss, feed_dict={x_data: rand_x, y_target: rand_y})
loss_vec.append(temp_loss)
if (i+1)%50==0:
print('Step #' + str(i+1) + ' A = ' + str(sess.run(A)) + ' b = ' + str(sess.run(b)))
print('Loss = ' + str(temp_loss))
# Get the optimal coefficients
[slope] = sess.run(A)
[y_intercept] = sess.run(b)
# Get best fit line
best_fit = []
for i in x_vals:
best_fit.append(slope*i+y_intercept)
# Plot the result
plt.plot(x_vals, y_vals, 'o', label='Data Points')
plt.plot(x_vals, best_fit, 'r-', label='Best fit line', linewidth=3)
plt.legend(loc='upper left')
plt.title('Sepal Length vs Pedal Width')
plt.xlabel('Pedal Width')
plt.ylabel('Sepal Length')
plt.show()
# Plot loss over time
plt.plot(loss_vec, 'k-')
plt.title('L2 Loss per Generation')
plt.xlabel('Generation')
plt.ylabel('L2 Loss')
plt.show()
結果:
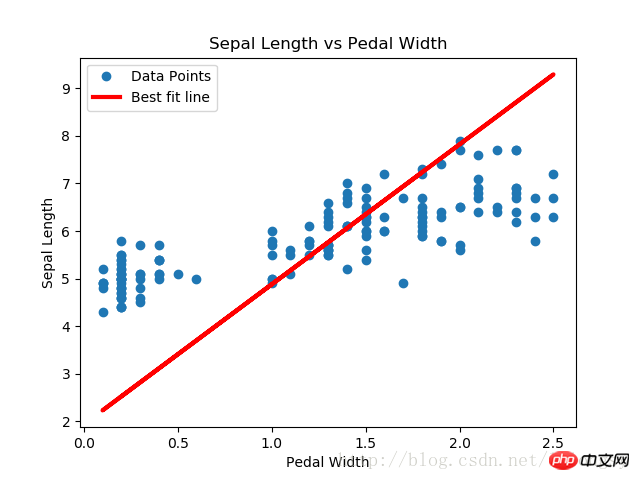
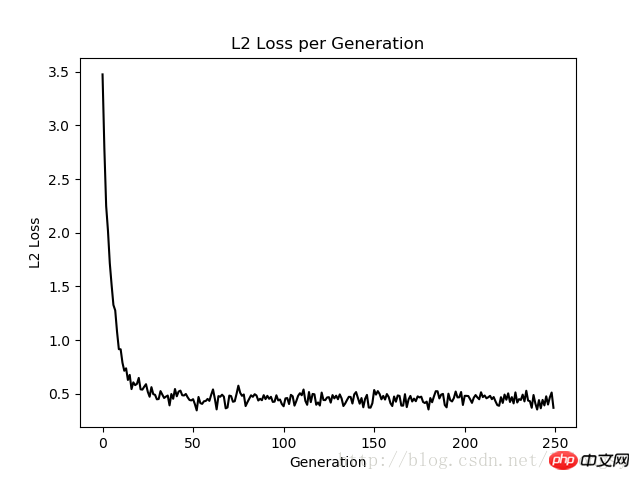
本文的戴明迴歸演算法與線性迴歸演算法所得的結果基本一致。兩者之間的關鍵差異在於預測值與資料點間的損失函數度量:線性迴歸演算法的損失函數是垂直距離損失;而戴明迴歸演算法是垂直距離損失(到x軸和y軸的總距離損失)。
注意,這裡戴明迴歸演算法的實作類型是總體迴歸(總的最小平方法誤差)。總體迴歸演算法是假設x值和y值的誤差是相似的。我們也可以根據不同的理念使用不同的誤差來擴展x軸和y軸的距離計算。
相關推薦:
以上是用TensorFlow實作戴明迴歸演算法的範例的詳細內容。更多資訊請關注PHP中文網其他相關文章!
陳述:
本文內容由網友自願投稿,版權歸原作者所有。本站不承擔相應的法律責任。如發現涉嫌抄襲或侵權的內容,請聯絡admin@php.cn