
如何利用Python爬取網易雲音樂熱門評論

- 零到壹度原創
- 2018-04-11 17:33:253416瀏覽
這篇文章給大家分享的內容是如何利用Python爬取網易雲音樂熱門評論,有著一定的參考價值,有需要的朋友可以參考一下
前言
#最近在研究文本挖掘相關的內容,所謂巧婦難為無米之炊,要進行文本分析,首先得到有文本吧。取得文字的方式有很多,例如從網路上下載現成的文字文檔,或透過第三方提供的API進行取得資料。但有的時候我們想要的資料並不能直接取得,因為並沒有提供直接的下載管道或API供我們取得資料。那這個時候該怎麼辦呢?有一種比較好的方法是透過網路爬蟲,也就是寫電腦程式偽裝成使用者去獲得想要的資料。 利用電腦的高效,我們可以輕鬆快速地取得資料。
關於爬蟲
#那麼該如何寫一個爬蟲呢?有很多種語言可以寫爬蟲,像是Java,php,python 等,我個人比較喜歡使用python。因為python不但有著內建的功能強大的網路庫,還有諸多優秀的第三方函式庫,別人直接造好了輪子,我們直接拿過來用就可以了,這為寫爬蟲帶來了極大的方便。不誇張地說,使用不到10行python程式碼其實可以寫一個小小的爬蟲,而使用其他的語言可以要多寫很多程式碼,簡潔易懂正是python的巨大的優勢。
好了廢話不多說,進入今天的正題。近幾年網易雲音樂火了起來,我自己就是網易雲音樂的用戶,用了幾年了。以前用的是QQ音樂和酷狗,透過我自己的親身經歷來看,我覺得網易雲音樂最優特色的就是其精準的歌曲推薦和獨具特色的用戶評論(鄭重聲明!!!這不是軟文,非廣告! !常常一首歌下面會有一些被點讚眾多的神評論。加上前些日子網易雲音樂將精選用戶評論搬上了地鐵,網易雲音樂的評論又火了一把。所以我想對網易雲的評論進行分析,發現其中的規律,特別是分析一些熱評具有什麼共同的特徵。帶著這個目的,我開始了對網易雲評論的抓取工作。
網路庫
Python內建了兩個網路函式庫urllib和urllib2,但這兩個函式庫使用起來不是特別方便,所以在這裡我們使用一個廣受好評的第三方函式庫requests。使用requests只用很少的幾行程式碼就可以實現設定代理,模擬登陸等比較複雜的爬蟲工作。 如果已經安裝pip的話,直接使用pip install requests 即可安裝。
中文文件位址在此http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
#大家有什麼問題可以自行參考官方文檔,上面會有非常詳細的介紹。至於urllib和urllib2這兩個函式庫也是比較有用的,以後如果有機會我會再跟大家介紹一下。
工作原理
#在正式開始介紹爬蟲之前,先來談談爬蟲的基本工作原理,我們知道我們打開瀏覽器訪問某個網址本質上是向伺服器發送了一定的請求,伺服器在收到我們的請求之後,會根據我們的請求返回數據,然後通過瀏覽器將這些數據解析好,呈現在我們的面前。
如果我們使用程式碼的話,就要跳過瀏覽器的這個步驟,直接向伺服器發送一定的數據,然後再取回伺服器傳回的數據,提取出我們想要的資訊。
但是問題是,有的時候伺服器需要對我們發送的請求進行校驗,如果它認為我們的請求是非法的,就會不回傳數據,或傳回錯誤的數據。所以為了避免這種情況,我們有的時候需要把程式偽裝成一個正常的使用者,以便順利得到伺服器的回應。
如何偽裝呢?
這就要看使用者透過瀏覽器造訪一個網頁與我們透過程式造訪一個網頁之間的差異。
通常來說,我們透過瀏覽器造訪一個網頁,除了發送造訪的url之外,還會寄給服務額外的資訊,例如headers(頭部資訊)等,這就相當於是請求的身份證明,伺服器看到了這些數據,就會知道我們是透過正常的瀏覽器存取的,就會乖乖地返回數據給我們了。
模擬登陸
所以我們程式就得像瀏覽器一樣,在發送請求的時候,帶著這些標誌著我們身分的訊息,這樣就能順利拿到資料。有的時候,我們必須在登入狀態下才能得到一些數據,所以我們必須要模擬登入。
本質上來說,透過瀏覽器登入就是post一些表單資訊給伺服器(包括使用者名,密碼等資訊),伺服器校驗之後我們就可以順利登入了,利用程式也是一樣,瀏覽器post什麼數據,我們原樣發送就可以了。
關於模擬登入#,我後面會專門介紹一下。當然事情有的時候也不會這麼順利,因為有些網站設定了反爬措施,例如如果訪問過快,有時候會被封ip(典型的例如豆瓣)。這時候我們還得要設定代理伺服器,也就是變更我們的ip位址,如果一個ip被封了,就換另外一個ip,具體怎麼做,這些話題以後慢慢再說。
小技巧
最後,再介紹一個我認為在寫爬蟲過程中非常有用的小技巧。如果你在使用火狐瀏覽器或chrome的話,也許你會注意到有一個叫作開發者工具(chrome)或web控制台(firefox)的地方。這個工具非常有用,因為利用它,我們可以清楚地看到在訪問一個網站的過程中,瀏覽器到底發送了什麼信息,服務器究竟返回了什麼信息,這些信息是我們寫爬蟲的關鍵所在。下面你就會看到它的巨大用處。
如何爬取評論
#首先打開網易雲音樂的網頁版,隨便選擇一首歌曲打開它的網頁,這裡我以周傑倫的《晴天》為例。如下圖:
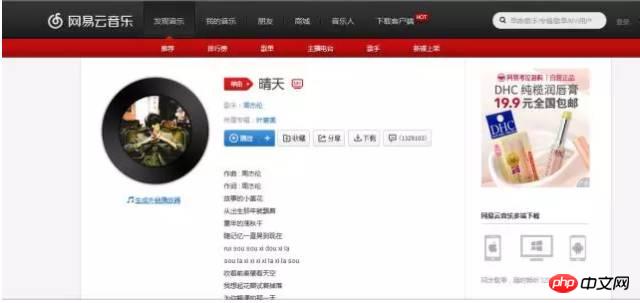
接下來開啟web控制台(chrome的話開啟開發者工具,如果是其他瀏覽器應該也是類似),如下圖:
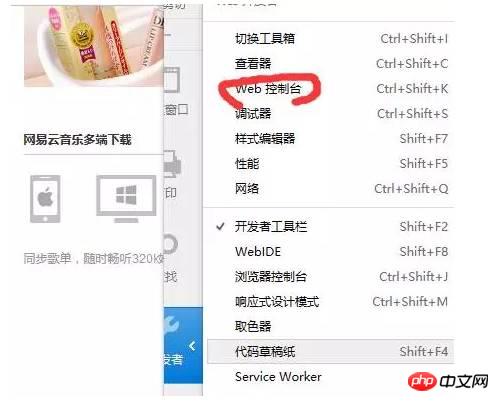
然後這個時候我們需要點選網絡,清除所有的訊息,然後點擊重新發送(相當於刷新瀏覽器),這樣我們就可以直觀看瀏覽器發送了什麼訊息以及伺服器回應了什麼訊息。如下圖:
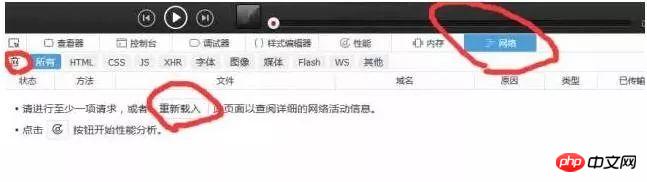
#刷新之後得到的資料如下

##可以看到瀏覽器發送了非常多的信息,那麼哪一個才是我們想要的呢?這裡我們可以透過狀態碼做一個初步的判斷,status code(狀態碼)標誌了伺服器請求的狀態,這裡狀態碼為200即表示請求正常,而304則表示不正常(狀態碼種類非常多,如果要想詳細了解可以自行搜索,這裡不說304具體的含義了)。所以我們通常只用看狀態碼為200的請求就可以了,還有就是,我們可以透過右邊欄的預覽來粗略觀察伺服器回傳了什麼資訊(或查看回應)。如下圖:
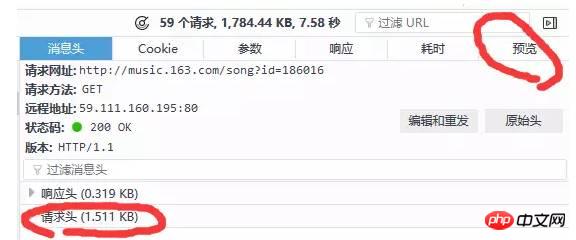
透過這兩種方法結合一般我們就可以快速找到我們想要分析的請求。注意圖5中的請求網址一欄就是我們想要請求的網址,請求的方法有兩種:get和post,還有一個需要重點關注的就是請求頭,裡麵包含了user -Agent(客戶端資訊),refrence(從何處跳轉過來)等多種訊息,一般無論是get還是post方法我們都會把頭部資訊帶上。頭部資訊如下圖:
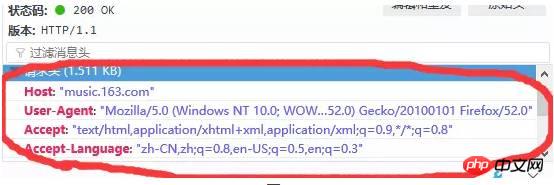
另外還要注意的是:get請求一般就直接把請求的參數以 ? parameter1=value1¶meter2=value2 等這樣的形式發送了,所以不需要帶上額外的請求參數,而post請求則一般需要帶上額外的參數,而不直接把參數放在url當中,所以有的時候我們還需要注意參數這一欄。經過仔細尋找,我們終於找到原來與評論相關的請求在http://music.163.com/weapi/v1/resource/comments/R_SO_4_186016?csrf_token= 這個請求當中,如下圖:
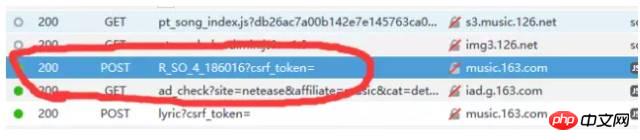
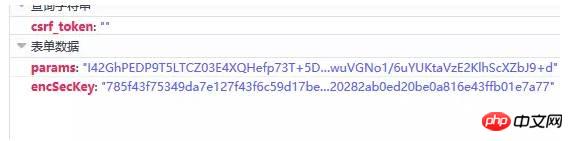
點開這個請求,我們發現它是一個post請求,請求的參數有兩個,一個是params,還有一個是encSecKey,這兩個參數的值非常的長,感覺應該像是加密過的。如下圖:
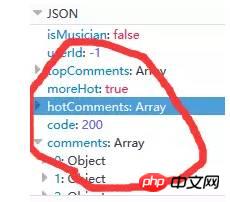
伺服器傳回的和評論相關的資料為json格式的,裡面含有非常豐富的資訊(例如有關評論者的信息,評論日期,按讚數,評論內容等等),如下圖9所示: (其實hotComments為熱門評論,comments為評論陣列)
至此,我們已經確定了方向了,即只需要確定params和encSecKey這兩個參數值即可,這個問題困擾了我一下午,我弄了很久也沒有搞清楚這兩個參數的加密方式,但是我發現了一個規律,http://music.163.com/weapi/v1/resource/comments/R_SO_4_186016?csrf_token= 中R_SO_4_ 後面的數字就是這首歌的id值,而對於不同的歌曲的param和encSecKey值,如果把一首歌比如A的這兩個參數值傳給B這首歌,那麼對於相同的頁數,這種參數是通用的,即A的第一頁的兩個參數值傳給其他任何一首歌的兩個參數,都可以獲得相應歌曲的第一頁的評論,對於第二頁,第三頁等也是類似。
但是遺憾的是,不同的頁數參數是不同的,這種辦法只能抓取有限的幾頁(當然抓取評論總數和熱門評論已經足夠了),如果要想抓取全部數據,就必須搞明白這兩個參數值的加密方式。
以為我沒有搞明白,昨天晚上我帶著這個問題去知乎搜尋了一下,居然真的被我找到了答案。 @平胸小仙女這位知友詳細說明瞭如何破解這兩個參數的加密過程,我研究了一下,發現還是有點小複雜的,按照知友寫的方法,我改了一下,就成功得到了全部的評論。這裡要對知乎@平胸小仙女 表示感謝。
到此為止,如何抓取網易雲音樂的評論全部資料就全部講完了。按照慣例,最後上代碼,親測有效:
#!/usr/bin/env python2.7
# -*- coding: utf-8 -*-
# @Time : 2017/3/28 8:46
# @Author : Lyrichu
# @Email : 919987476@qq.com
# @File : NetCloud_spider3.py '''
@Description:
网易云音乐评论爬虫,可以完整爬取整个评论
部分参考了@平胸小仙女的文章
来源:知乎
''' from Crypto.Cipher import AES
import base64
import requests
import json
import codecs
import time
# 头部信息
headers = {
'Host':"music.163.com",
'Accept-Language':"zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
'Accept-Encoding':"gzip, deflate",
'Content-Type':"application/x-www-form-urlencoded",
'Cookie':"_ntes_nnid=754361b04b121e078dee797cdb30e0fd,1486026808627; _ntes_nuid=754361b04b121e078dee797cdb30e0fd; JSESSIONID-WYYY=yfqt9ofhY%5CIYNkXW71TqY5OtSZyjE%2FoswGgtl4dMv3Oa7%5CQ50T%2FVaee%2FMSsCifHE0TGtRMYhSPpr20i%5CRO%2BO%2B9pbbJnrUvGzkibhNqw3Tlgn%5Coil%2FrW7zFZZWSA3K9gD77MPSVH6fnv5hIT8ms70MNB3CxK5r3ecj3tFMlWFbFOZmGw%5C%3A1490677541180; _iuqxldmzr_=32; vjuids=c8ca7976.15a029d006a.0.51373751e63af8; vjlast=1486102528.1490172479.21; __gads=ID=a9eed5e3cae4d252:T=1486102537:S=ALNI_Mb5XX2vlkjsiU5cIy91-ToUDoFxIw; vinfo_n_f_l_n3=411a2def7f75a62e.1.1.1486349441669.1486349607905.1490173828142; P_INFO=m15527594439@163.com|1489375076|1|study|00&99|null&null&null#hub&420100#10#0#0|155439&1|study_client|15527594439@163.com; NTES_CMT_USER_INFO=84794134%7Cm155****4439%7Chttps%3A%2F%2Fsimg.ws.126.net%2Fe%2Fimg5.cache.netease.com%2Ftie%2Fimages%2Fyun%2Fphoto_default_62.png.39x39.100.jpg%7Cfalse%7CbTE1NTI3NTk0NDM5QDE2My5jb20%3D; usertrack=c+5+hljHgU0T1FDmA66MAg==; Province=027; City=027; _ga=GA1.2.1549851014.1489469781; __utma=94650624.1549851014.1489469781.1490664577.1490672820.8; __utmc=94650624; __utmz=94650624.1490661822.6.2.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; playerid=81568911; __utmb=94650624.23.10.1490672820",
'Connection':"keep-alive",
'Referer':'http://music.163.com/' }
# 设置代理服务器
proxies= {
'http:':'http://121.232.146.184',
'https:':'https://144.255.48.197'
}
# offset的取值为:
(评论页数-1)*20,total第一页为true,其余页为false # first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}'
# 第一个参数 second_param = "010001"
# 第二个参数
# 第三个参数 third_param = "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
# 第四个参数 forth_param = "0CoJUm6Qyw8W8jud"
# 获取参数 def get_params(page):
# page为传入页数
iv = "0102030405060708"
first_key = forth_param
second_key = 16 * 'F'
if(page == 1): # 如果为第一页
first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}'
h_encText = AES_encrypt(first_param, first_key, iv)
else:
offset = str((page-1)*20)
first_param = '{rid:"", offset:"%s", total:"%s", limit:"20", csrf_token:""}' %(offset,'false')
h_encText = AES_encrypt(first_param, first_key, iv)
h_encText = AES_encrypt(h_encText, second_key, iv)
return h_encText
# 获取 encSecKey
def get_encSecKey():
encSecKey = "257348aecb5e556c066de214e531faadd1c55d814f9be95fd06d6bff9f4c7a41f831f6394d5a3fd2e3881736d94a02ca919d952872e7d0a50ebfa1769a7a62d512f5f1ca21aec60bc3819a9c3ffca5eca9a0dba6d6f7249b06f5965ecfff3695b54e1c28f3f624750ed39e7de08fc8493242e26dbc4484a01c76f739e135637c"
return encSecKey
# 解密过程
def AES_encrypt(text, key, iv):
pad = 16 - len(text) % 16
text = text + pad * chr(pad)
encryptor = AES.new(key, AES.MODE_CBC, iv)
encrypt_text = encryptor.encrypt(text)
encrypt_text = base64.b64encode(encrypt_text)
return encrypt_text
# 获得评论json数据
def get_json(url, params, encSecKey):
data = {
"params": params,
"encSecKey": encSecKey
}
response = requests.post(url, headers=headers, data=data,proxies = proxies)
return response.content
# 抓取热门评论,返回热评列表
def get_hot_comments(url):
hot_comments_list = []
hot_comments_list.append(u"用户ID 用户昵称 用户头像地址 评论时间 点赞总数 评论内容")
params = get_params(1) # 第一页
encSecKey = get_encSecKey()
json_text = get_json(url,params,encSecKey)
json_dict = json.loads(json_text)
hot_comments = json_dict['hotComments'] # 热门评论
print("共有%d条热门评论!" % len(hot_comments))
for item in hot_comments:
comment = item['content'] # 评论内容
likedCount = item['likedCount'] # 点赞总数
comment_time = item['time'] # 评论时间(时间戳)
userID = item['user']['userID'] # 评论者id
nickname = item['user']['nickname'] # 昵称
avatarUrl = item['user']['avatarUrl'] # 头像地址
comment_info = userID + " " + nickname + " " + avatarUrl + " " + comment_time + " " + likedCount + " " + comment + u""
hot_comments_list.append(comment_info)
return hot_comments_list
# 抓取某一首歌的全部评论
def get_all_comments(url):
all_comments_list = [] # 存放所有评论
all_comments_list.append(u"用户ID 用户昵称 用户头像地址 评论时间 点赞总数 评论内容") # 头部信息
params = get_params(1)
encSecKey = get_encSecKey()
json_text = get_json(url,params,encSecKey)
json_dict = json.loads(json_text)
comments_num = int(json_dict['total'])
if(comments_num % 20 == 0):
page = comments_num / 20
else:
page = int(comments_num / 20) + 1
print("共有%d页评论!" % page)
for i in range(page): # 逐页抓取
params = get_params(i+1)
encSecKey = get_encSecKey()
json_text = get_json(url,params,encSecKey)
json_dict = json.loads(json_text)
if i == 0:
print("共有%d条评论!" % comments_num) # 全部评论总数
for item in json_dict['comments']:
comment = item['content'] # 评论内容
likedCount = item['likedCount'] # 点赞总数
comment_time = item['time'] # 评论时间(时间戳)
userID = item['user']['userId'] # 评论者id
nickname = item['user']['nickname'] # 昵称
avatarUrl = item['user']['avatarUrl'] # 头像地址
comment_info = unicode(userID) + u" " + nickname + u" " + avatarUrl + u" " + unicode(comment_time) + u" " + unicode(likedCount) + u" " + comment + u""
all_comments_list.append(comment_info)
print("第%d页抓取完毕!" % (i+1))
return all_comments_list
# 将评论写入文本文件
def save_to_file(list,filename):
with codecs.open(filename,'a',encoding='utf-8') as f:
f.writelines(list)
print("写入文件成功!")
if __name__ == "__main__":
start_time = time.time() # 开始时间
url = "http://music.163.com/weapi/v1/resource/comments/R_SO_4_186016/?csrf_token="
filename = u"晴天.txt"
all_comments_list = get_all_comments(url)
save_to_file(all_comments_list,filename)
end_time = time.time() #结束时间
print("程序耗时%f秒." % (end_time - start_time))我利用上述代碼跑了一下,抓了兩首周傑倫的熱門歌曲《晴天》(有130多萬評論)而《告白氣球》(有20多萬個評論),前者跑了大概有20多分鐘,後者有6600多秒(也就是將近2個小時),截圖如下:
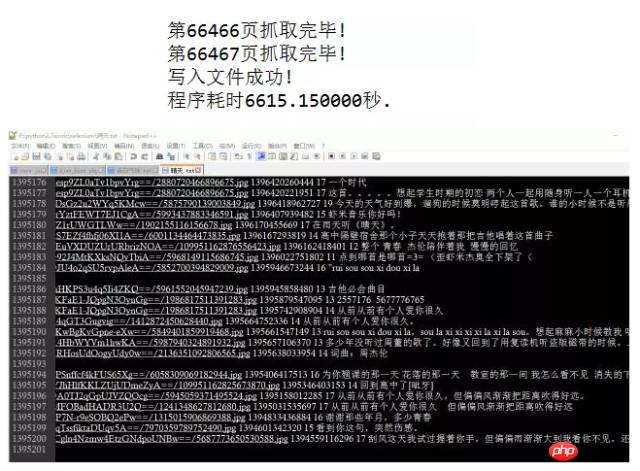
注意我是依照空格來分隔的,每一行分別有用戶ID用戶暱稱用戶頭像地址評論時間點讚總數評論內容 這些內容。同學們自己跑程式碼抓取的時候,注意不要開太多線程給網易雲的伺服器太大壓力哦(中間有一段時間伺服器回傳資料特別慢,不知道是不是限制訪問了,後來又好了)。我後面或許會自己去對評論資料進行視覺化分析,敬請期待!
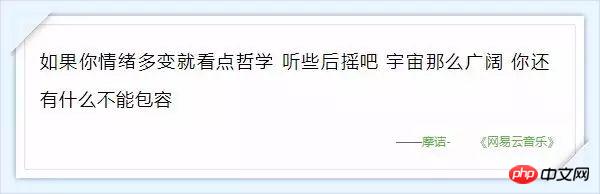
附錄:那些讓人感動的評論

以上是如何利用Python爬取網易雲音樂熱門評論的詳細內容。更多資訊請關注PHP中文網其他相關文章!