
零基礎寫python爬蟲之爬蟲編寫全記錄_python

- 不言原創
- 2018-04-08 11:52:061897瀏覽
前面九篇文章從基礎到寫都做了詳細的介紹了,第十篇麼講究個十全十美,那麼我們就來詳細記錄一下一個爬蟲程序如何一步步編寫出來的,各位看官可要看仔細了
先來看看我們學校的網站:
http://jwxt.sdu.edu.cn:77777/zhxt_bks/zhxt_bks.html
查詢成績需要登錄,然後顯示各學科成績,但只顯示成績而沒有績點,也就是加權平均分數。
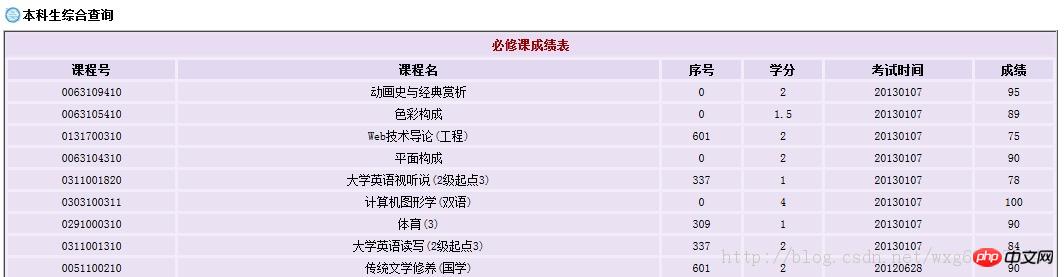
顯然這樣手動計算績點是一件非常麻煩的事情。所以我們可以用python來做一個爬蟲來解決這個問題。
1.決戰前夕
先來準備一下工具:HttpFox外掛程式。
這是一款http協定分析插件,分析頁面請求與回應的時間、內容、以及瀏覽器用到的COOKIE等。
以我為例,安裝在火狐上即可,效果如圖:
可以非常直觀的查看相應的資訊。
點選start是開始偵測,點選stop暫停偵測,點選clear清除內容。
一般在使用之前,點擊stop暫停,然後點擊clear清屏,確保看到的是存取目前頁面所獲得的資料。
2.深入敵後
下面就去山東大學的成績查詢網站,看一看在登入的時候,到底發送了那些資訊.
先來到登入頁面,把httpfox打開,在clear之後,點選start開啟偵測:

輸入完成了個人資訊,確保httpfox處於開啟狀態,然後點選確定提交信息,實現登入。
這個時候可以看到,httpfox偵測到了三個訊息:
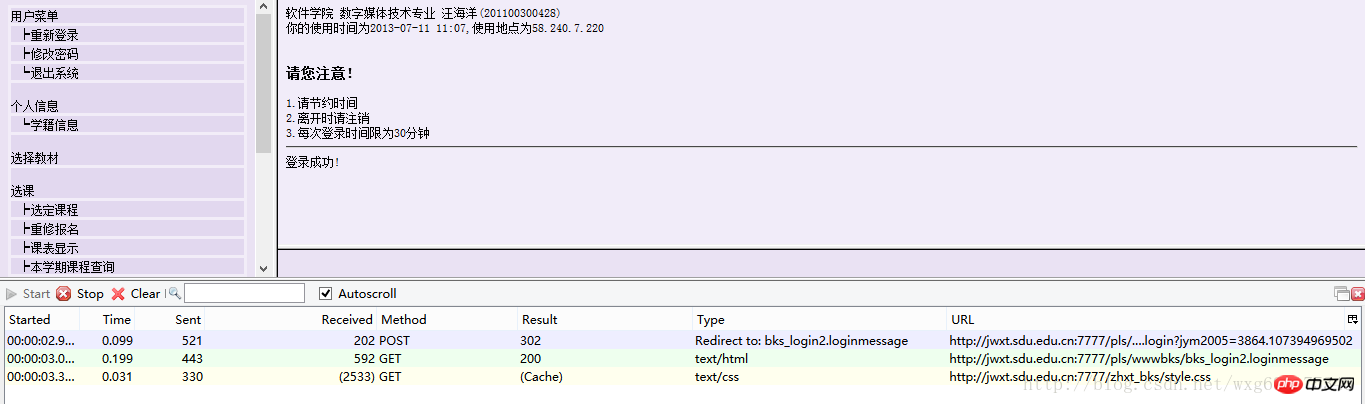
這時點擊stop鍵,確保捕捉到的是造訪該頁面之後回饋的數據,以便我們做爬蟲的時候模擬登陸使用。
3.庖丁解牛
乍一看我們拿到了三個數據,兩個是GET的一個是POST的,但是它們到底是什麼,應該怎麼用,我們還一無所知。
所以,我們需要挨個查看一下捕獲到的內容。
先看POST的訊息:
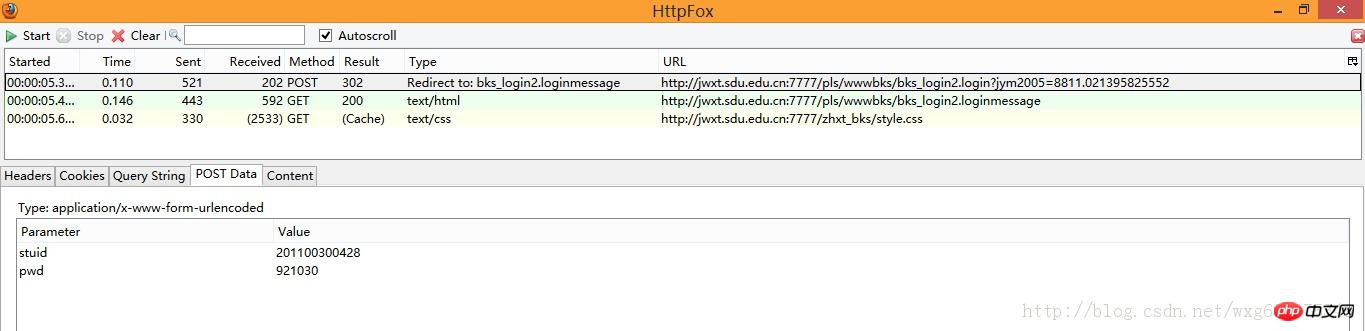
既然是POST的訊息,我們就直接看PostData就好。
可以看到一共POST兩個數據,stuid和pwd。
並且從Type的Redirect to可以看出,POST完畢之後跳到了bks_login2.loginmessage頁面。
由此看出,這個資料是點選確定之後提交的表單資料。
點擊cookie標籤,看看cookie訊息:
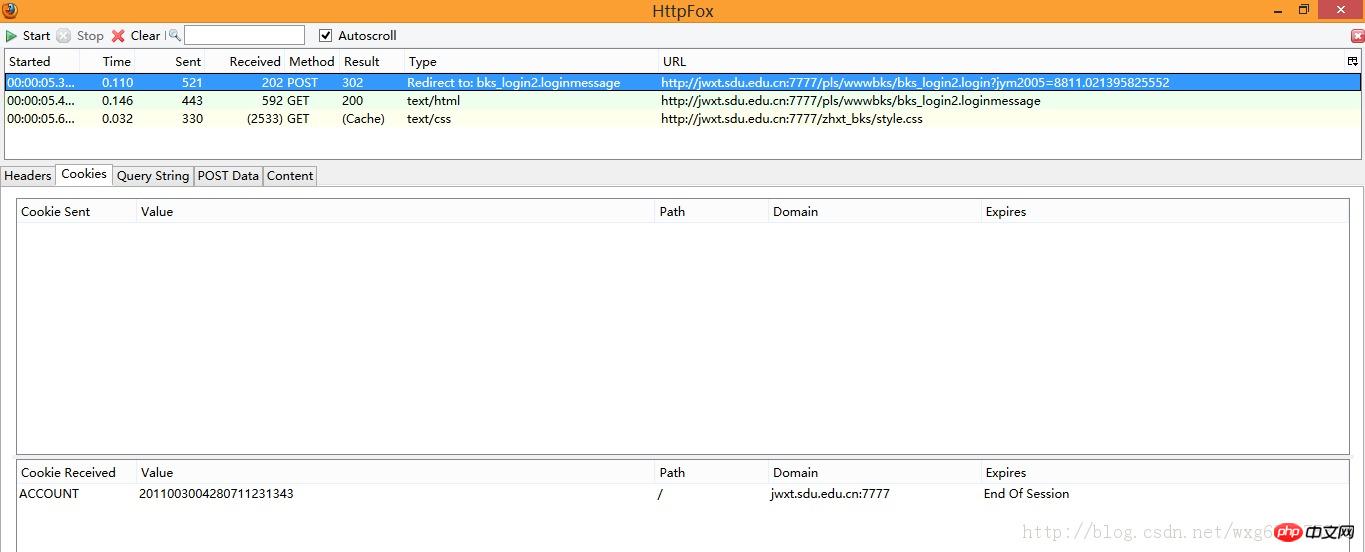
#沒錯,收到了一個ACCOUNT的cookie,並且在session結束後自動銷毀。
那麼提交之後收到了哪些資訊呢?
我們來看看後面的兩個GET資料。
先看第一個,我們點選content標籤可以看收到的內容,是不是有一種生吞活剝的快感-。 -HTML源碼暴露無疑了:
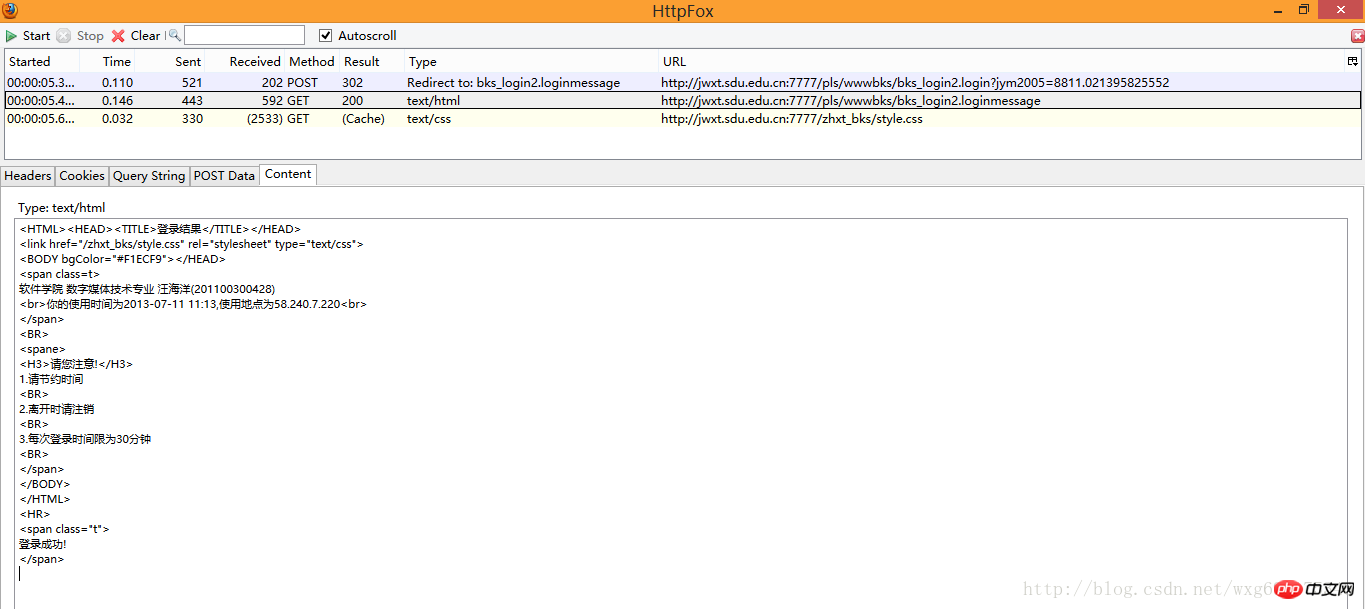
看來這個只是顯示頁面的html源碼而已,點擊cookie,查看cookie的相關資訊:
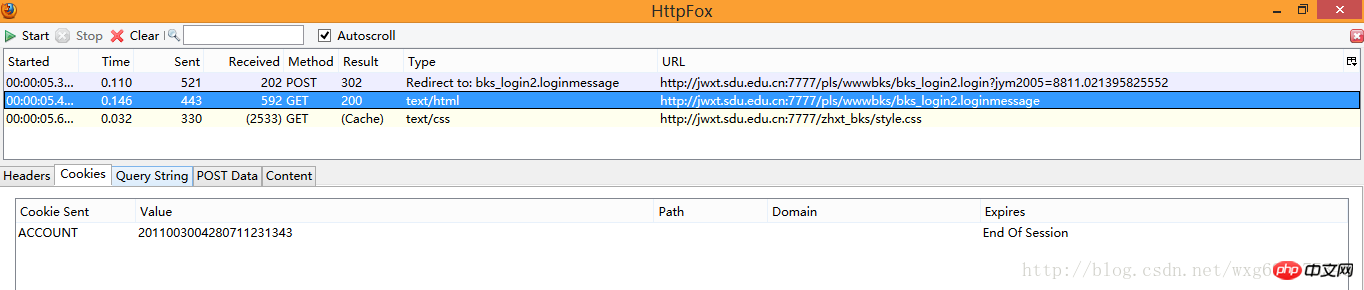
啊哈,原本html頁面的內容是傳送了cookie訊息之後才接受到的。
再來看看最後一個收到的訊息:
#大致看了一下應該只是一個叫做style.css的css文件,對我們沒有太大的作用。
4.冷靜應戰
既然已經知道了我們向伺服器發送了什麼數據,也知道了我們接收到了什麼數據,基本的流程如下:
首先,我們POST學號和密碼--->然後傳回cookie的值然後發送cookie給伺服器--->回傳頁面資訊。取得到成績頁面的數據,用正規表示式將成績和學分單獨取出併計算加權平均數。
OK,看起來好像很簡單的樣紙。那下面我們就來試試看吧。
但是在實驗之前,還有一個問題沒有解決,就是POST的資料到底送到哪裡了?
再來看一下當初的頁面:

很明顯是用html框架來實現的,也就是說,我們在網址列看到的位址並不是右邊提交表單的位址。
那麼怎樣才能得到真正的地址-。 -右鍵查看頁面原始碼:
嗯沒錯,那個name="w_right"的就是我們要的登入頁面。
網站的原來的位址是:
http://jwxt.sdu.edu.cn:7777/zhxt_bks/zhxt_bks.html
所以,真正的表單提交的位址應該是:
http://jwxt.sdu.edu.cn:7777/zhxt_bks/xk_login.html
輸入一看,果實不其然:
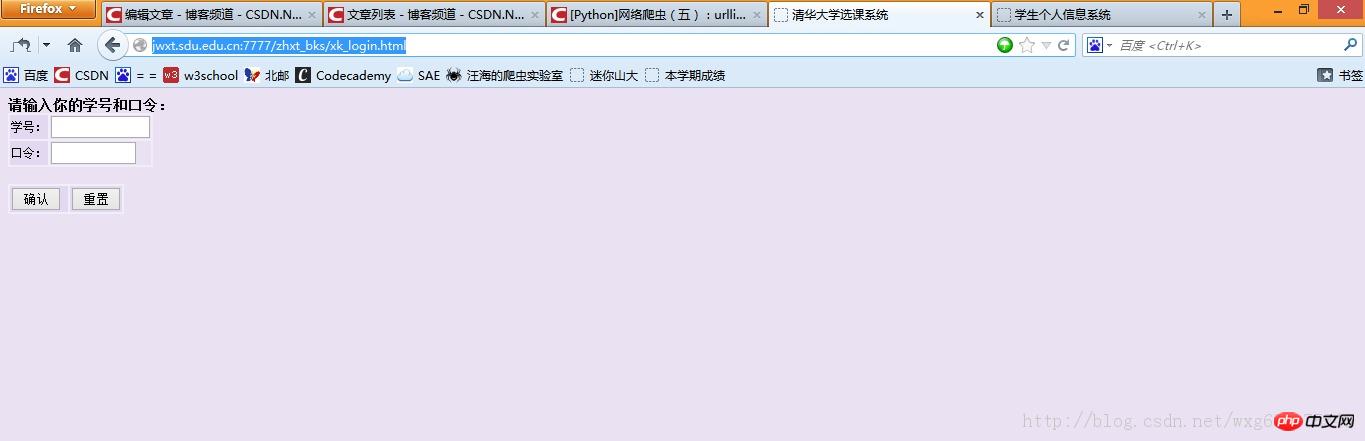
#靠居然是清華大學的選課系統。 。 。目測是我校懶得做頁面了就直接借了。 。結果連標題都不改一下。 。 。
但這個頁面依舊不是我們需要的頁面,因為我們的POST資料提交到的頁面,應該是表單form的ACTION中提交到的頁面。
也就是說,我們需要查看源碼,來知道POST資料到底發送到了哪裡:
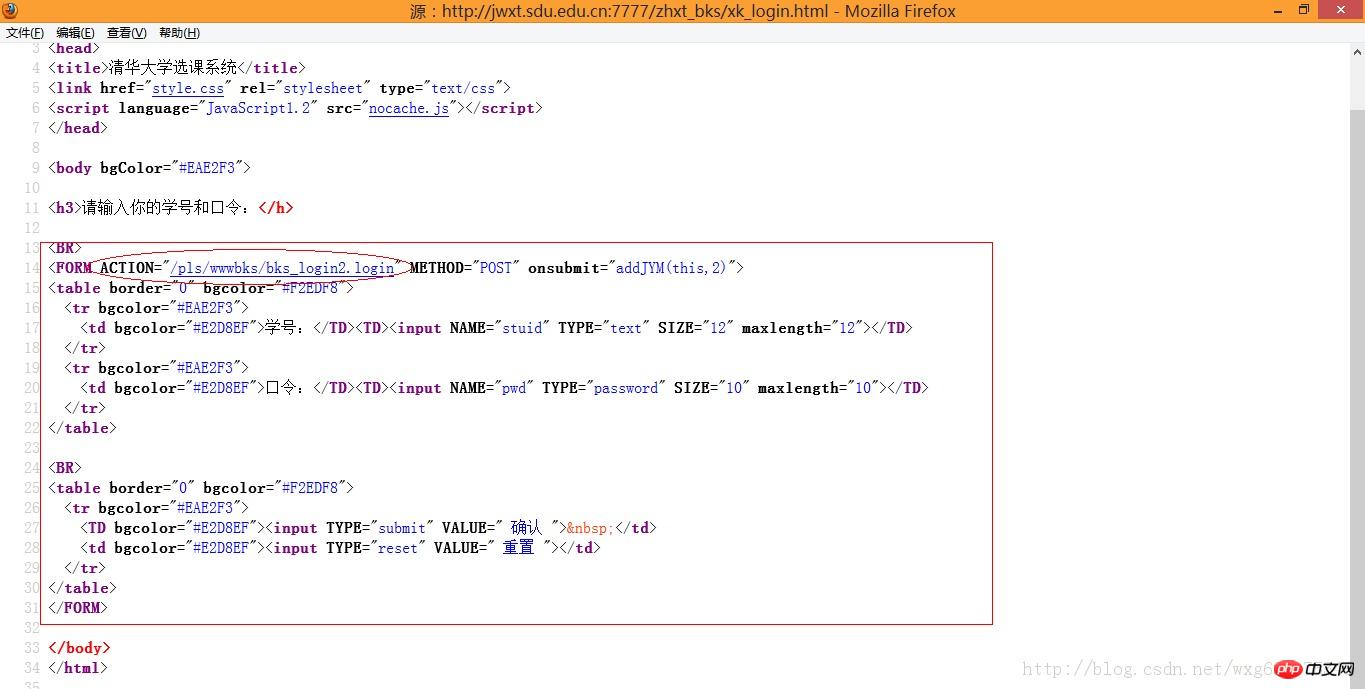
嗯,目測這個才是提交POST數據的位址。
整理到網址列中,完整的網址應如下:
#http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bks_login2.login
(取得的方式很簡單,在火狐瀏覽器中直接點擊那個連結就能看到這個連結的位址了)
5.小試牛刀
接下來的任務就是:用python模擬傳送一個POST的資料並取到回傳的cookie值。
關於cookie的操作可以看看這篇文章:
http://www.jb51.net/article/57144.htm
我們先準備一個POST的數據,再準備一個cookie的接收,然後寫出源碼如下:
# -*- coding: utf-8 -*-
#---------------------------------------
# 程序:山东大学爬虫
# 版本:0.1
# 作者:why
# 日期:2013-07-12
# 语言:Python 2.7
# 操作:输入学号和密码
# 功能:输出成绩的加权平均值也就是绩点
#---------------------------------------
import urllib
import urllib2
import cookielib
cookie = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
#需要POST的数据#
postdata=urllib.urlencode({
'stuid':'201100300428',
'pwd':'921030'
})
#自定义一个请求#
req = urllib2.Request(
url = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bks_login2.login',
data = postdata
)
#访问该链接#
result = opener.open(req)
#打印返回的内容#
print result.read()如此這般之後,再看看運行的效果:
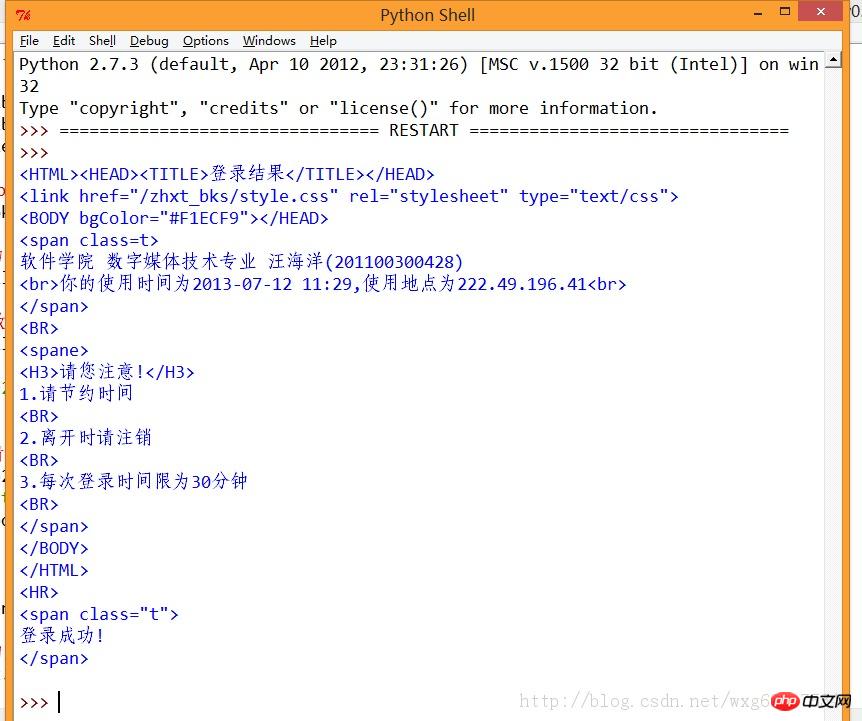
ok,如此這般,我們就算模擬登陸成功了。
6.偷天換日
接下來的任務就是用爬蟲取得到學生的成績。
再來看看來源網站。
開啟HTTPFOX之後,點擊查看成績,發現捕獲到如下的數據:
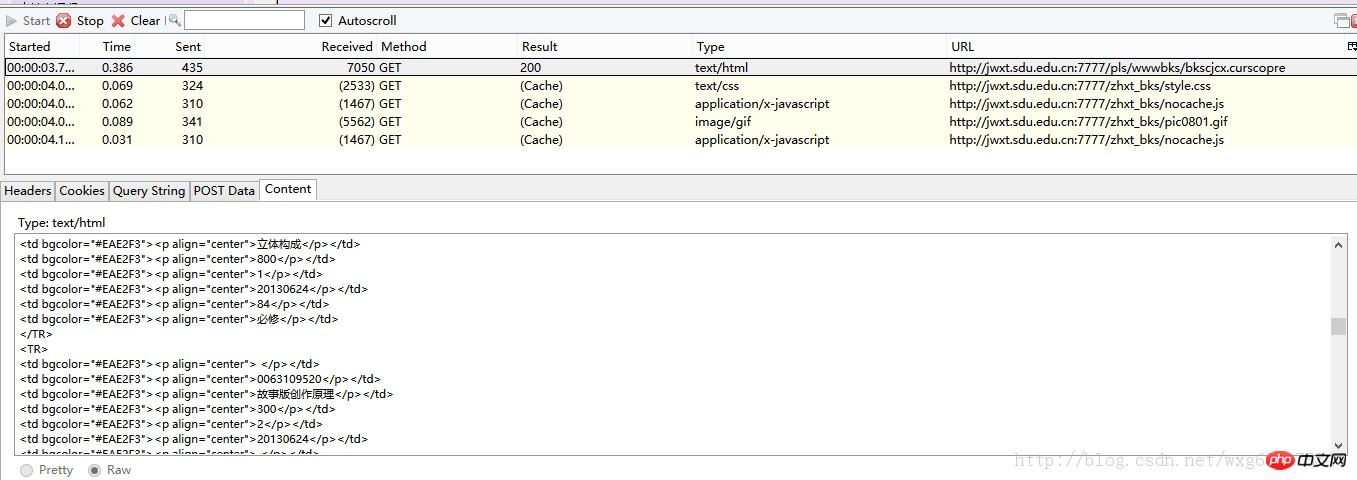
#點擊第一個GET的數據,查看內容可以發現Content就是獲得到的成績的內容。
而獲取到的頁面鏈接,從頁面源代碼中右鍵查看元素,可以看到點擊鏈接之後跳轉的頁面(火狐瀏覽器只需要右鍵單擊,“查看此框架”,即可):
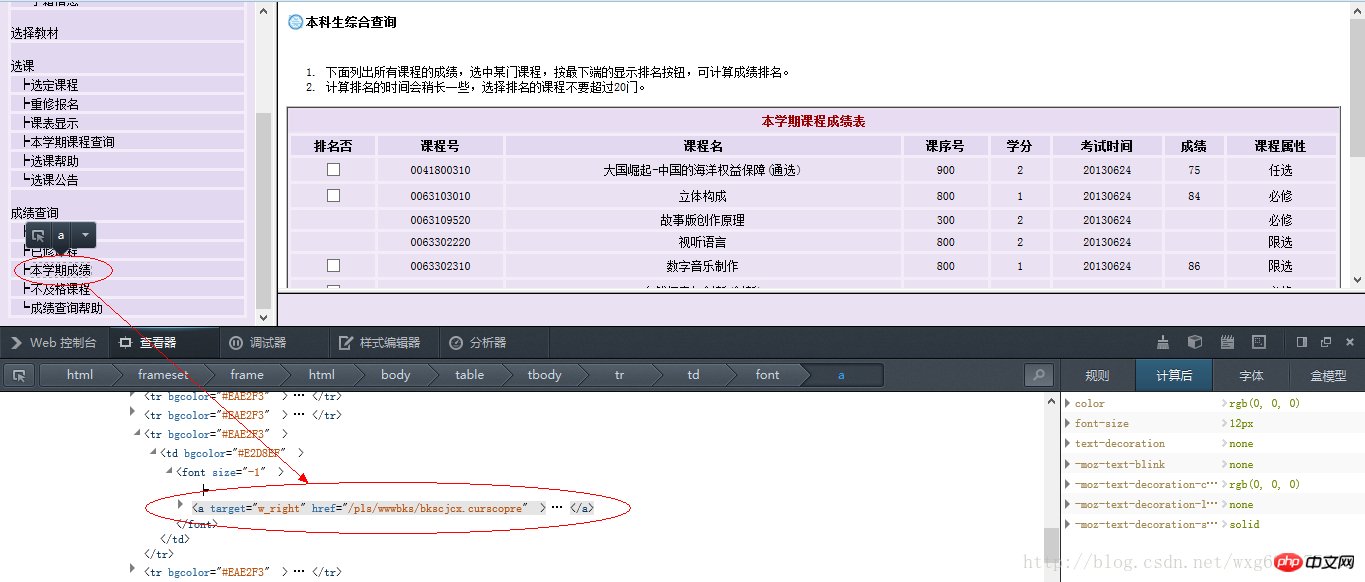
因此可以得到查看成績的連結如下:
7.萬事俱備
現在萬事俱備啦,所以只需要把連結應用到爬蟲裡面,看看能否查看到成績的頁面。 從httpfox可以看到,我們發送了一個cookie才能返回成績的信息,所以我們就用python模擬一個cookie的發送,以此來請求成績的信息:# -*- coding: utf-8 -*-
#---------------------------------------
# 程序:山东大学爬虫
# 版本:0.1
# 作者:why
# 日期:2013-07-12
# 语言:Python 2.7
# 操作:输入学号和密码
# 功能:输出成绩的加权平均值也就是绩点
#---------------------------------------
import urllib
import urllib2
import cookielib
#初始化一个CookieJar来处理Cookie的信息#
cookie = cookielib.CookieJar()
#创建一个新的opener来使用我们的CookieJar#
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
#需要POST的数据#
postdata=urllib.urlencode({
'stuid':'201100300428',
'pwd':'921030'
})
#自定义一个请求#
req = urllib2.Request(
url = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bks_login2.login',
data = postdata
)
#访问该链接#
result = opener.open(req)
#打印返回的内容#
print result.read()
#打印cookie的值
for item in cookie:
print 'Cookie:Name = '+item.name
print 'Cookie:Value = '+item.value
#访问该链接#
result = opener.open('http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bkscjcx.curscopre')
#打印返回的内容#
print result.read()按下F5運行即可,看看捕獲到的資料吧:

8.手到擒來
# -*- coding: utf-8 -*-
#---------------------------------------
# 程序:山东大学爬虫
# 版本:0.1
# 作者:why
# 日期:2013-07-12
# 语言:Python 2.7
# 操作:输入学号和密码
# 功能:输出成绩的加权平均值也就是绩点
#---------------------------------------
import urllib
import urllib2
import cookielib
import re
class SDU_Spider:
# 申明相关的属性
def __init__(self):
self.loginUrl = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bks_login2.login' # 登录的url
self.resultUrl = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bkscjcx.curscopre' # 显示成绩的url
self.cookieJar = cookielib.CookieJar() # 初始化一个CookieJar来处理Cookie的信息
self.postdata=urllib.urlencode({'stuid':'201100300428','pwd':'921030'}) # POST的数据
self.weights = [] #存储权重,也就是学分
self.points = [] #存储分数,也就是成绩
self.opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(self.cookieJar))
def sdu_init(self):
# 初始化链接并且获取cookie
myRequest = urllib2.Request(url = self.loginUrl,data = self.postdata) # 自定义一个请求
result = self.opener.open(myRequest) # 访问登录页面,获取到必须的cookie的值
result = self.opener.open(self.resultUrl) # 访问成绩页面,获得成绩的数据
# 打印返回的内容
# print result.read()
self.deal_data(result.read().decode('gbk'))
self.print_data(self.weights);
self.print_data(self.points);
# 将内容从页面代码中抠出来
def deal_data(self,myPage):
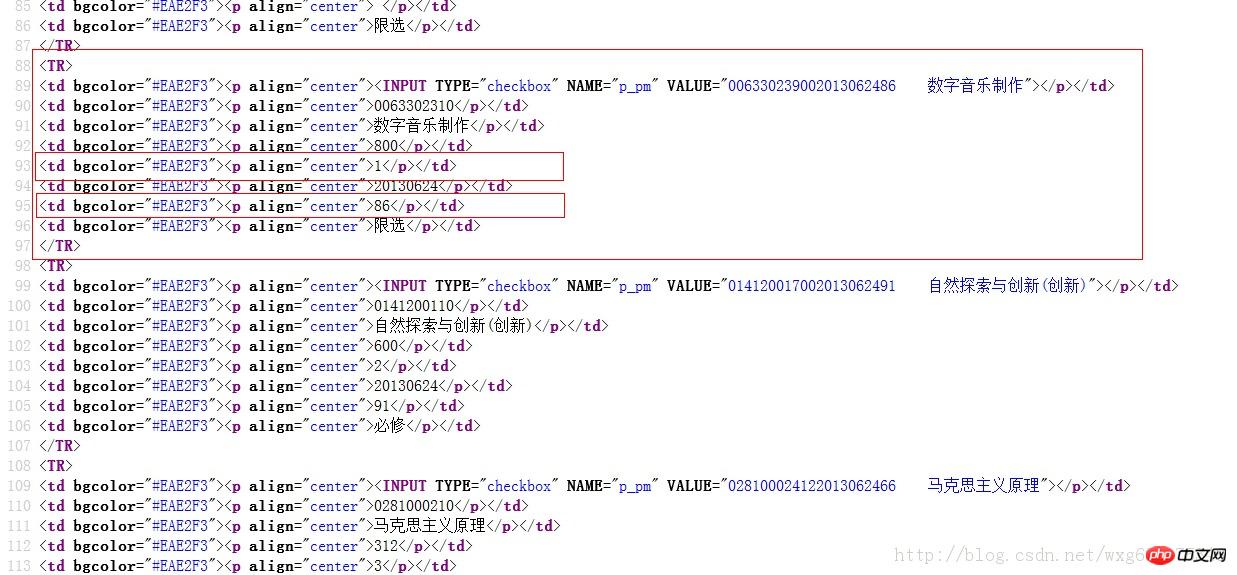
myItems = re.findall('<TR>.*?<p.*?<p.*?<p.*?<p.*?<p.*?>(.*?)</p>.*?<p.*?<p.*?>(.*?)</p>.*?</TR>',myPage,re.S) #获取到学分
for item in myItems:
self.weights.append(item[0].encode('gbk'))
self.points.append(item[1].encode('gbk'))
# 将内容从页面代码中抠出来
def print_data(self,items):
for item in items:
print item
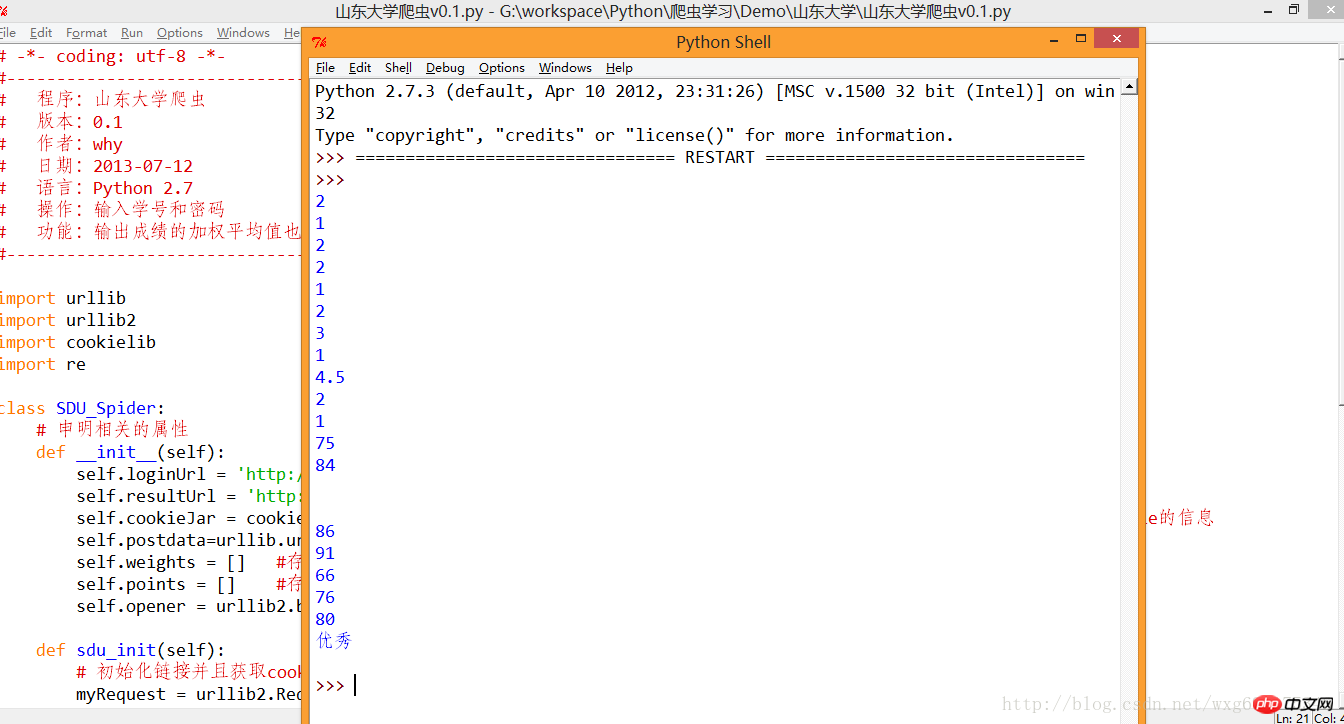
#调用
mySpider = SDU_Spider()
mySpider.sdu_init()水平有限,,正則是有點醜,。運行的效果如圖:
9.凱旋而歸
# -*- coding: utf-8 -*-
#---------------------------------------
# 程序:山东大学爬虫
# 版本:0.1
# 作者:why
# 日期:2013-07-12
# 语言:Python 2.7
# 操作:输入学号和密码
# 功能:输出成绩的加权平均值也就是绩点
#---------------------------------------
import urllib
import urllib2
import cookielib
import re
import string
class SDU_Spider:
# 申明相关的属性
def __init__(self):
self.loginUrl = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bks_login2.login' # 登录的url
self.resultUrl = 'http://jwxt.sdu.edu.cn:7777/pls/wwwbks/bkscjcx.curscopre' # 显示成绩的url
self.cookieJar = cookielib.CookieJar() # 初始化一个CookieJar来处理Cookie的信息
self.postdata=urllib.urlencode({'stuid':'201100300428','pwd':'921030'}) # POST的数据
self.weights = [] #存储权重,也就是学分
self.points = [] #存储分数,也就是成绩
self.opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(self.cookieJar))
def sdu_init(self):
# 初始化链接并且获取cookie
myRequest = urllib2.Request(url = self.loginUrl,data = self.postdata) # 自定义一个请求
result = self.opener.open(myRequest) # 访问登录页面,获取到必须的cookie的值
result = self.opener.open(self.resultUrl) # 访问成绩页面,获得成绩的数据
# 打印返回的内容
# print result.read()
self.deal_data(result.read().decode('gbk'))
self.calculate_date();
# 将内容从页面代码中抠出来
def deal_data(self,myPage):
myItems = re.findall('<TR>.*?<p.*?<p.*?<p.*?<p.*?<p.*?>(.*?)</p>.*?<p.*?<p.*?>(.*?)</p>.*?</TR>',myPage,re.S) #获取到学分
for item in myItems:
self.weights.append(item[0].encode('gbk'))
self.points.append(item[1].encode('gbk'))
#计算绩点,如果成绩还没出来,或者成绩是优秀良好,就不运算该成绩
def calculate_date(self):
point = 0.0
weight = 0.0
for i in range(len(self.points)):
if(self.points[i].isdigit()):
point += string.atof(self.points[i])*string.atof(self.weights[i])
weight += string.atof(self.weights[i])
print point/weight
#调用
mySpider = SDU_Spider()
mySpider.sdu_init()相關推薦:以上是零基礎寫python爬蟲之爬蟲編寫全記錄_python的詳細內容。更多資訊請關注PHP中文網其他相關文章!