
如何完整寫一個爬蟲框架

- 零到壹度原創
- 2018-03-30 11:28:404800瀏覽
本文主要為大家分享一篇如何完整寫一個爬蟲框架的請求方法,具有很好的參考價值,希望對大家有所幫助。一起跟著小編過來看看吧,希望能幫助大家。
產生爬蟲框架:
1、建立scrapy爬蟲工程
##2、在工程中產生一個scrapy爬蟲
3、設定spider爬蟲
4、運行爬蟲,取得網頁
具體操作:
1、建立工程
#定義一個工程,名稱為:python123demo
 方法:
方法:
 在cmd中,d: 進入d盤, cd pycodes 進入檔案pycodes
在cmd中,d: 進入d盤, cd pycodes 進入檔案pycodes
#然後輸入
 scrapy startproject python123demo
scrapy startproject python123demo
 在pycodes中會產生一個檔案:
在pycodes中會產生一個檔案:
#_init_.py不需要使用者寫

2、在工程中產生一個scrapy爬蟲
 執行一條指令,給出爬蟲名字和爬取的網站
執行一條指令,給出爬蟲名字和爬取的網站
產生爬蟲:
產生一個名稱為demo 的spider
只產生demo.py,其內容為:
# #name = 'demo' 當前爬蟲名字為demo
allowed_domains = " 爬取該網站域名以下的鏈接,該域名由cmd命令台輸入
#start_urls = [] 爬取的初始頁面

parse()用於處理相應,解析內容形成字典,發現新的url爬取請求
3、配置產生的spider爬蟲,使其滿足我們的需求
#將解析的頁面儲存成檔案

修改demo.py檔
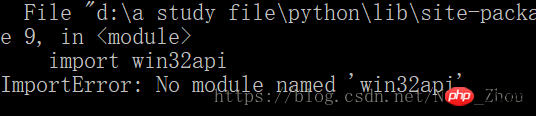
#然後我的電腦上出現了一個錯誤
windows系統上出現這個問題的解決需要安裝Py32Win模組,但直接透過官網連結裝exe會出現幾百個錯誤,更方便的做法是
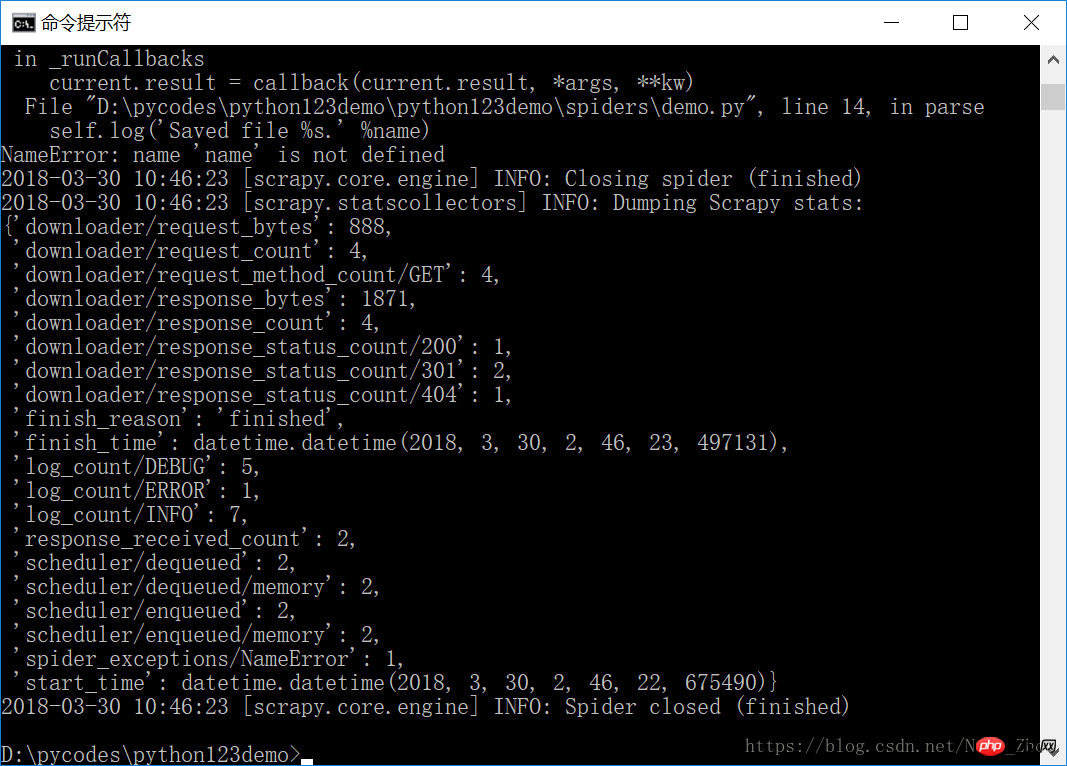
擷取頁面儲存在demo.html檔案中

#demo.py 所對應的完整程式碼:

兩個版本等價:

以上是如何完整寫一個爬蟲框架的詳細內容。更多資訊請關注PHP中文網其他相關文章!
陳述:
本文內容由網友自願投稿,版權歸原作者所有。本站不承擔相應的法律責任。如發現涉嫌抄襲或侵權的內容,請聯絡admin@php.cn
上一篇:Python是爬取其他網頁下一篇:Python是爬取其他網頁