
解析JS正規的原理與語法
- php中世界最好的语言原創
- 2018-03-29 16:17:431819瀏覽
這次帶給大家解析JS正規的原理和語法,解析JS正則原理和語法的注意事項有哪些,下面就是實戰案例,一起來看一下。
正則啊,就像一座燈塔,當你在字符串的海洋不知所措的時候,總能給你一點思路;正則啊,就像一台驗鈔機,在你不知道用戶提交的鈔票真假的時候,總是可以幫你一眼識別;正則啊,就像一個手電筒,在你需要找什麼玩意的時候,總是能幫你get你要的東西...
—— 在節選自Stinson 同學的語文排比句練習《正則》
欣賞了一段文學節選後,我們正式來梳理一遍JS中的正則,本文的首要目的是,防止我經常忘記正則的一些用法,故梳理和寫下來加強熟練度和用作參考,次要目的是與君共勉,如有紕漏,請不吝賜教,良辰謝過。
本文既然取題為“一條龍”,就要對得起”龍”,故將包括正則原理、語法一覽、JS(ES5)中的正則、ES6對正則的擴展、實踐正則的思路,我盡量深入盡量淺出地去講這些東西(搞得好像真能深入淺出一樣的),如果你只想知道怎麼應用,那麼看第二、三、五部分,基本就能滿足你的需求了,如果想掌握JS中的正規的,那麼還是委屈你跟著我的思路來吧,嘿嘿嘿!
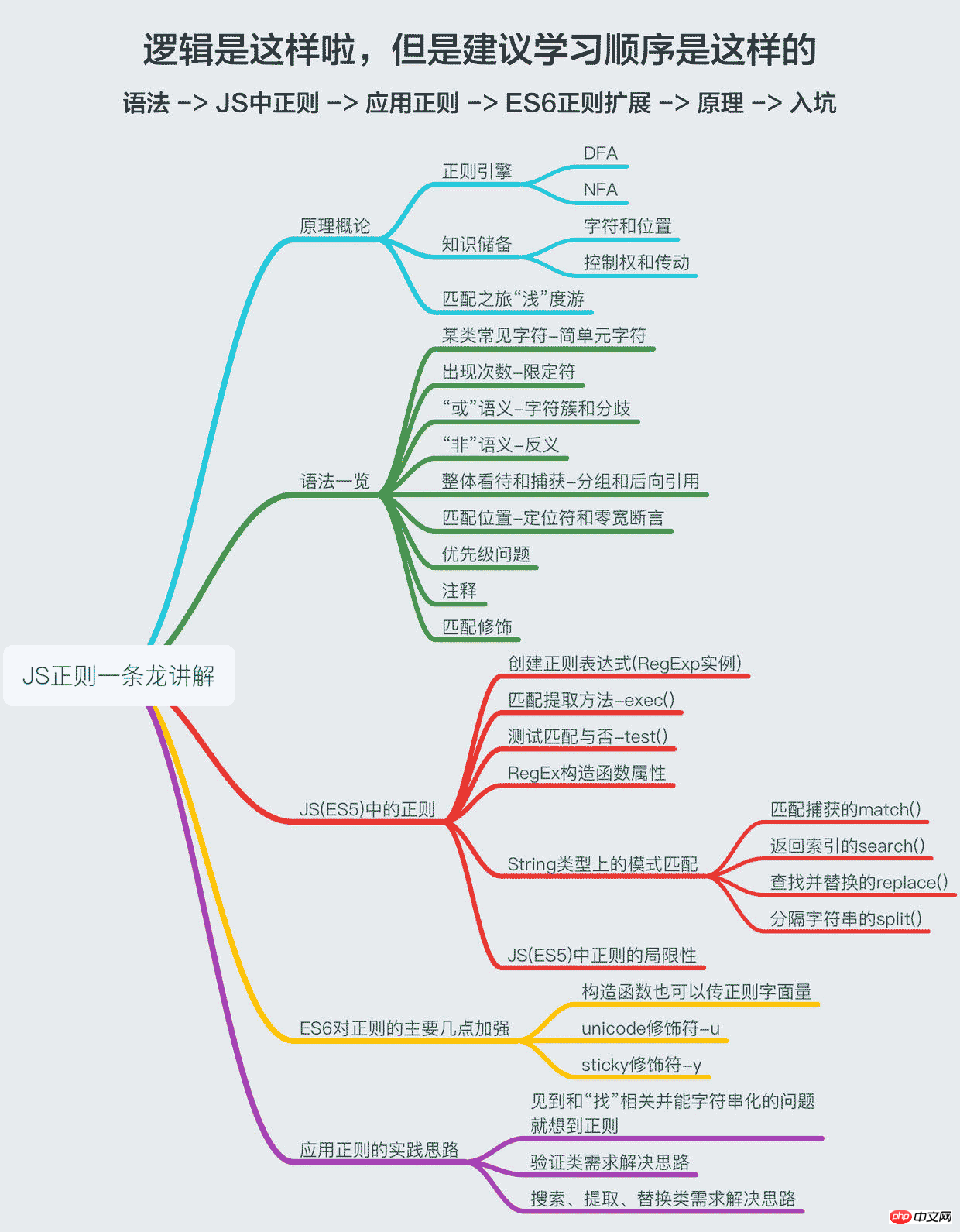
一、原理概論
#一開始用正規的時候,就覺得神奇,電腦究竟是怎麼根據一個正規表示式來符合字串的?直到後來我遇到了一本書叫《計算理論》,看到了正規、DFA、NFA的概念和相互間的聯繫,才有一些恍然小悟的意思。
但如果真的要從原理上吃透正則表達式,那麼恐怕最好的方式是:
1. 首先去找一本專門講正則的書去看看,O'REILLY的「動物總動員」系列裡就有;
2. 再自己實現一個正規引擎。
而本文的重點在於JS中正規的應用,故原理僅作簡單介紹(因為我也沒寫過正則引擎,也不深入),一來大致「糊弄下」像我一樣的好奇寶寶們對正規原理的疑惑,二來知道一些原理方面的基本知識,對於理解文法和寫正則是大有裨益的。
1. 正規引擎
為什麼正則能有效,因為有引擎,這和為什麼JS能執行一樣,有JS引擎,所謂正則引擎,可以理解為根據你的正規表示式用演算法去模擬一台機器,這台機器有很多狀態,透過讀取待測的字串,在這些狀態間跳來跳去,如果最後停在了「終結狀態」(Happy Ending),那麼就Say I Do,否則Say You Are a Good Man。如此將一個正規表示式轉換為一個可在有限的步數中計算出結果的機器,那麼就實現了引擎。
正規的引擎大致可分為兩類:DFA和NFA
1. DFA (Deterministic finite automaton) 確定型有窮自動機
2. NFA (Non -deterministic finite automaton) 非確定型有窮自動機,大部分都是NFA
這裡的「確定型」指,對於某個確定字符的輸入,這台機器的狀態會確定地從a跳到b,「非確定型」指,對於某個確定字符的輸入,這台機器可能有好幾種狀態的跳法;這裡的「有窮」指,狀態是有限的,可以在有限的步數內確定某個字串是被接受還是發好人卡的;這裡的“自動機”,可以理解為,一旦這台機器的規則設定完成,就可以自行判斷了,不要人看。
DFA引擎不需要進行回溯,所以匹配效率一般情況下要高,但是它並不支持捕獲組,於是也就不支持反向引用和$這種形式的引用,也不支持環視(Lookaround)、非貪婪模式等一些NFA引擎特有的特性。
如果想更詳細地了解正規、DFA、NFA,那麼可以去看《計算理論》,然後你可以根據某個正規表示式自己畫出一台自動機。
2. 知識儲備
這一小節對於你理解正規表示式很有用,尤其是明白什麼是字符,什麼是位置。
2.1 正規眼中的字串-n個字符,n+1個位置

在上面的「笑聲」字串中,一共有8個字符,這是你能看到的,還有9個位置,這是聰明的人才能看到的。為什麼要有字元還要有位置?因為位置是可以被配對的。
那麼進一步我們再來理解“佔有字符”和“零寬度”:
#如果一個子正則表達式匹配到的是字符,而不是位置,而且會被保存到最終的結果中,那個這個子表達式就是佔有字符的,比如/ha/(匹配ha)就是佔有字符的;
如果一個子正則匹配的是位置,而不是字符,或匹配到的內容不保存在結果中(其實也可以看做一個位置),那麼這個子表達式是零寬度的,比如/read(?=ing)/(匹配reading,但是只將read放入結果中,下文會詳述語法,此處僅舉例用),其中的(?=ing)就是零寬度的,它本質代表一個位置。
佔有字元是互斥的,零寬度是非互斥的。也就是一個字符,同一時間只能由一個子表達式匹配,而一個位置,卻可以同時由多個零寬度的子表達式匹配。舉個栗子,例如/aa/是匹配不了a的,這個字串中的a只能由正則的第一個a字元匹配,而不能同時由第二個a匹配(廢話);但是位置是可以多個匹配的,例如/\b\ba/是可以匹配a的,雖然正則表達式裡有2個表示單字開頭位置的\b元字符,這兩個\b是可以同時匹配位置0(在這個例子中)的。
注意:我們說字元和位置是面向字串說的,而說佔有字元和零寬度是面向正規說的。
2.2 控制權和傳動
這兩個字可能在搜一些博文或資料的時候會遇到,這裡做一個解釋先:
控制權是指哪一個正規子表達式(可能為一個普通字元、元字元或元字元序列組成)在匹配字串,那麼控制權就在哪。
傳動是指正規引擎的一種機制,傳動裝置將定位正規從字串的哪裡開始匹配。
正規表示式當開始匹配的時候,一般是由一個子表達式取得控制權,從字串中的某一個位置開始嘗試匹配,一個子表達式開始嘗試匹配的位置,是從前一子表達匹配成功的結束位置開始的。
舉一個栗子,read(?=ing)ing\sbook符合reading book,我們把這個正規看成5個子表達式read、(?=ing)、ing、\s、book,當然你也可以吧read看做4個單獨字元的子表達式,只是我們這裡為了方便這麼看待。 read從位置0開始匹配到位置4,後面的(?=ing)繼續從位置4開始匹配,發現位置4後面確實是ing,於是斷言匹配成功,也就是整一個(?=ing)就是匹配了位置4這一個位置而已(這裡更能理解什麼是零寬了吧),然後後面的ing再從位置4開始匹配到位置7,然後\s再從位置7匹配到位置8,最後的book從位置8匹配到位置12,整一個匹配完成。
3. 配對之旅「淺」度遊(可跳過)
說了那麼多,我們把自己當做一個正則引擎,一步一步以最小的單位— —「字元」和「位置」-去看正規相符的過程,舉幾個栗子。
3.1 基本符合
正規表示式:easy
來源字串:So easy
匹配過程:首先由正規表示式字元e取得控制權,從字串的位置0開始匹配,遇到字串字元'S',匹配失敗,然後正則引擎向前傳動,從位置1開始嘗試,遇到字符串字元'o',匹配失敗,繼續傳動,後面的空格自然也失敗,於是從位置3開始嘗試匹配,成功匹配字符串字符'e',控制權交給正則表達式子表達式(這裡也是一個字符)a,嘗試從上次匹配成功的結束位置4開始匹配,成功匹配字符串字'a',後面一直如此匹配到'y',然後匹配完成,匹配結果為easy。
3.2 零寬符合
正则:^(?=[aeiou])[a-z]+$ 源字符串:apple
首先這個正規表示:符合這樣一個從頭到尾完整的字串,這整一個字串僅由小寫字母組成,並且以a、e、 i、o、u這5個字母任一字母開頭。
匹配过程:首先正则的^(表示字符串开始的位置)获取控制权,从位置0开始匹配,匹配成功,控制权交给(?=[aeiou]),这个子表达式要求该位置右边必须是元音小写字母中的一个,零宽子表达式相互间不互斥,所以从位置0开始尝试匹配,右侧是字符串的‘a',符合因此匹配成功,所以(?=[aeiou])匹配此处的位置0匹配成功,控制权交给[a-z]+,从位置0开始匹配,字符串‘apple'中的每个字符都匹配成功,匹配到字符串末尾,控制权交回正则的$,尝试匹配字符串结束位置,成功,至此,整个匹配完成。
3.3 贪婪匹配和非贪婪匹配
正则1:{.*}
正则2:{.*?}
源字符串:{233}
这里有两个正则,在限定符(语法会讲什么是限定符)后面加?符号表示忽略优先量词,也就是非贪婪匹配,这个栗子我剥得快一点。
首先开头的{匹配,两个正则都是一样的表现。
正则1的.*为贪婪匹配,所以一直匹配余下字符串'233}',匹配到字符串结束位置,只是每次匹配,都记录一个备选状态,为了以后回溯,每次匹配有两条路,选择了匹配这条路,但记一下这里还可以有不匹配这条路,如果前面死胡同了,可以退回来,此时控制权交还给正则的},去匹配字符串结束位置,失败,于是回溯,意思就是说前面的.*你吃的太多了,吐一个出来,于是控制权回给.*,吐出一个}(其实是用了前面记录的备选状态,尝试不用.*去匹配'}'),控制权再给正则的},这次匹配就成功了。
正则2的.*?为非贪婪匹配,尽可能少地匹配,所以匹配'233}'的每一个字符的时候,都是尝试不匹配,但是一但控制权交还给最后的}就发现出问题了,赶紧回溯乖乖匹配,于是每一个字符都如此,最终匹配成功。
云里雾里?这就对了!可以移步去下面推荐的博客看看:
想详细了解贪婪和非贪婪匹配原理以及获取更多正则相关原理,除了看书之外,推荐去一个CSDN的博客 雁过无痕-博客频道 - CSDN.NET ,讲解得很详细和透彻
二、语法一览
正则的语法相信许多人已经看过deerchao写的30分钟入门教程,我也是从那篇文字中入门的,deerchao从语法逻辑的角度以.NET正则的标准来讲述了正则语法,而我想重新组织一遍,以便于应用的角度、以JS为宿主语言来重新梳理一遍语法,这将便于我们把语言描述翻译成正则表达式。
下面这张一览图(可能需要放大),整理了常用的正则语法,并且将JS不支持的语法特性以红色标注出来了(正文将不会描述这些不支持的特性),语法部分的详细描述也将根据下面的图,从上到下,从左到右的顺序来梳理,尽量不啰嗦。
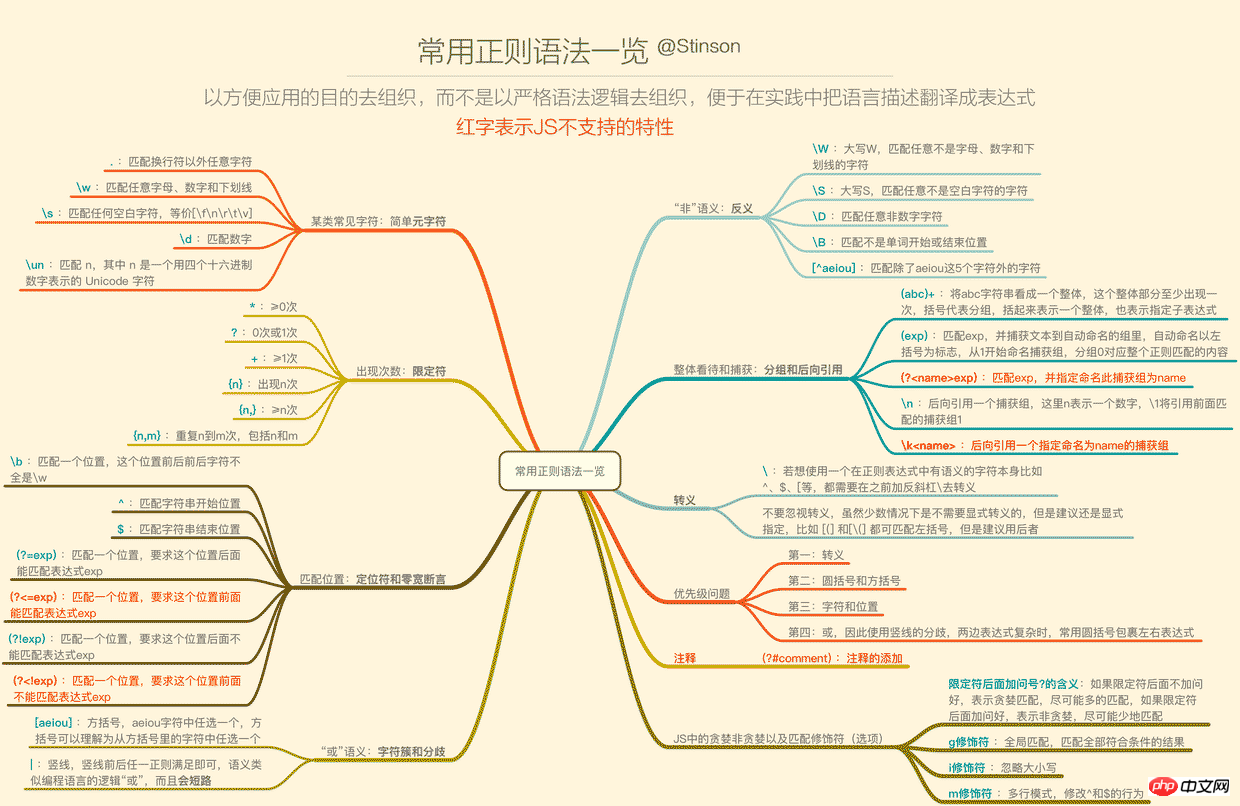
1. 要用某类常见字符——简单元字符
为什么这里要加简单2个字,因为在正则中,\d、\w这样的叫元字符,而{n,m}、(?!exp)这样的也叫元字符,所以元字符是在正则中有特定意义的标识,而这一小节讲的是简单的一些元字符。
.匹配除了换行符以外的任意字符,也即是[^\n],如果要包含任意字符,可使用(.|\n)
\w匹配任意字母、数字或者下划线,等价于[a-zA-Z0-9_],在deerchao的文中还指出可匹配汉字,但是\w在JS中是不能匹配汉字的
\s匹配任意空白符,包含换页符\f、换行符\n、回车符\r、水平制表符\t、垂直制表符\v
\d匹配数字
\un匹配n,这里的n是一个有4个十六进制数字表示的Unicode字符,比如\u597d表示中文字符“好”,那么超过\uffff编号的字符怎么表示呢?ES6的u修饰符会帮你。
2. 要表示出现次数(重复)——限定符
a*表示字符a连续出现次数 >= 0 次
a+表示字符a连续出现次数 >= 1 次
a?表示字元a出現次數0 或1 次
a{5}表示字元a連續出現次數5 次
#a{5,}表示字元a連續出現次數>= 5次
#a{5,10}表示字元a連續出現次數為5到10次,包括5和10
3. 匹配位置-定位符號和零寬斷言
符合某個位置的表達式都是零寬的,這是主要包含兩部分,一是定位符,匹配一個特定位置,二是零寬斷言,匹配一個要滿足某要求的位置。
定位符有以下幾個常用的:
\b匹配單字邊界位置,準確的描述是它匹配一個位置,這個位置前後不全是\w能描述的字符,所以像\u597d\babc是可以匹配「好abc」的。
^符合字串開始位置,也就是位置0,如果設定了RegExp 物件的Multiline 屬性,^ 也符合'\n' 或'\r' 之後的位置
$符合字串結束位置,如果設定了RegExp 物件的Multiline 屬性,$ 也符合'\n' 或'\r' 之前的位置
#零寬斷言(JS支援的)有以下兩個:
(?=exp)符合一個位置,這個位置的右邊能符合表達式exp,注意這個表達式式只是匹配一個位置,只是它對於這個位置的右邊有要求,而右邊的東西是不會被放進結果的,比如用read(?=ing)去匹配“reading”,結果是“read”,而「ing」是不會放進結果的
(?!exp)符合一個位置,這個位置的右邊不能符合表達式exp
4. 想表達「或」的意思-字元簇與分歧
我們常會表達「或」的意思,例如這幾個字元中的任何一個都行,再例如配對5個數字或5個字母都行等等需求。
字元簇可用來表達字元層級的「或」語義,表示的是方括號中的字元任選一:
[abc]表示a、b 、c這3個字元中的任意一個,如果字母或數字是連續的,那麼可以用-連起來表示,[b-f]代表從b到f這麼多字元中任選一個
[(ab)(cd)]並不會用來匹配字串“ab”或“cd”,而是匹配a、b、c、d、(、)這6個字元中的任一個,也就是想表達「匹配字串ab或cd」這樣的需求不能這麼做,要這麼寫ab|cd。但這裡要匹配圓括號本身,講道理是要反斜線轉義的,但是在方括號中,圓括號被當成普通字元看待,即便如此,仍然建議顯式地轉義
分歧用來表示表達式層級的「或」語義,表示的是符合|左右任一表達式就可:
- ##ab|cd會符合字串「 ab」或「cd」
- 會短路,回想下
程式語言中邏輯或的短路,所以用(ab|abc)去匹配字串「abc ”,結果會是“ab”,因為垂直線左邊的已經滿足了,就用左邊的匹配結果代表整個正則的結果
- \W、 \D、\S、\B 用大寫字母的這幾個元字符表示就是對應小寫字母匹配內容的反義,這幾個依次匹配“除了字母、數字、下劃線外的字符”、“非數字字符” 、「非空白符」、「非單字邊界位置」
- [^aeiou]表示除了a、e、i、o、u外的任一字符,在方括號中且出現在開頭位置的^表示排除,如果^在方括號中不出現在開頭位置,那麼它僅僅代表^字符本身
後向引用
其實你在上面的一些地方已經看到了圓括號,是的,圓括號就是用來分組的,括在一對括號裡的就是一個分組。上面讲的大部分是针对字符级别的,比如重复字母 “A” 5次,可以用A{5}来表示,但是如果想要字符串“ABC”重复5次呢?这个时候就需要用到括号。
括号的第一个作用,将括起来的分组当做一个整体看待,所以你可以像对待字符重复一样在一个分组后面加限定符,比如(ABC){5}。
分组匹配到的内容也就是这个分组捕获到的内容,从左往右,以左括号为标志,每个分组会自动拥有一个从1开始的编号,编号0的分组对应整个正则表达式,JS不支持捕获组显示命名。
括号的第二个作用,分组捕获到的内容,可以在之后通过\分组编号的形式进行后向引用。比如(ab|cd)123\1可以匹配“ab123ab”或者“cd123cd”,但是不能匹配“ab123cd”或“cd123ab”,这里有一对括号,也是第一对括号,所以编号为捕获组1,然后在正则中通过\1去引用了捕获组1的捕获的内容,这叫后向引用。
括号的第三个作用,改变优先级,比如abc|de和(abc|d)e表达的完全不是一个意思。
7. 转义
任何在正则表达式中有作用的字符都建议转义,哪怕有些情况下不转义也能正确,比如[]中的圆括号、^符号等。
8. 优先级问题
优先级从高到低是:
转义 \
括号(圆括号和方括号)(), (?:), (?=), []
字符和位置
竖线 |
9. 贪婪和非贪婪
在限定符中,除了{n}确切表示重复几次,其余的都是一个有下限的范围。
在默认的模式(贪婪)下,会尽可能多的匹配内容。比如用ab*去匹配字符串“abbb”,结果是“abbb”。
而通过在限定符后面加问号?可以进行非贪婪匹配,会尽可能少地匹配。用ab*?去匹配“abbb”,结果会是“a”。
不带问号的限定符也称匹配优先量词,带问号的限定符也称忽略匹配优先量词。
10. 修饰符(匹配选项)
其实正则的匹配选项有很多可选,不同的宿主语言环境下可能各有不同,此处就JS的修饰符作一个说明:
加g修饰符:表示全局匹配,模式将被应用到所有字符串,而不是在发现第一个匹配项时停止
加i修饰符:表示不区分大小写
加m修饰符:表示多行模式,会改变^和$的行为,上文已述
三、JS(ES5)中的正则
JS中的正则由引用类型RegExp表示,下面主要就RegExp类型的创建、两个主要方法和构造函数属性来展开,然后会提及String类型上的模式匹配,最后会简单罗列JS中正则的一些局限。
1. 创建正则表达式
一种是用字面量的方式创建,一种是用构造函数创建,我们始终建议用前者。
//创建一个正则表达式
var exp = /pattern/flags;
//比如
var pattern=/\b[aeiou][a-z]+\b/gi;
//等价下面的构造函数创建
var pattern=new RegExp("\\b[aeiou][a-z]+\\b","gi");
其中pattern可以是任意的正则表达式,flags部分是修饰符,在上文中已经阐述过了,有 g、i、m 这3个(ES5中)。
现在说一下为什么不要用构造函数,因为用构造函数创建正则,可能会导致对一些字符的双重转义,在上面的例子中,构造函数中第一个参数必须传入字符串(ES6可以传字面量),所以字符\ 会被转义成\,因此字面量的\b会变成字符串中的\\b,这样很容易出错,贼多的反斜杠。
2. RegExp上用来匹配提取的方法——exec()
var matches=pattern.exec(str); 接受一个参数:源字符串 返回:结果数组,在没有匹配项的情况下返回null
结果数组包含两个额外属性,index表示匹配项在字符串中的位置,input表示源字符串,结果数组matches第一项即matches[0]表示匹配整个正则表达式匹配的字符串,matches[n]表示于模式中第n个捕获组匹配的字符串。
要注意的是,第一,exec()永远只返回一个匹配项(指匹配整个正则的),第二,如果设置了g修饰符,每次调用exec()会在字符串中继续查找新匹配项,不设置g修饰符,对一个字符串每次调用exec()永远只返回第一个匹配项。所以如果要匹配一个字符串中的所有需要匹配的地方,那么可以设置g修饰符,然后通过循环不断调用exec方法。
//匹配所有ing结尾的单词
var str="Reading and Writing";
var pattern=/\b([a-zA-Z]+)ing\b/g;
var matches;
while(matches=pattern.exec(str)){
console.log(matches.index +' '+ matches[0] + ' ' + matches[1]);
}
//循环2次输出
//0 Reading Read
//12 Writing Writ
3. RegExp上用来测试匹配成功与否的方法——test()
var result=pattern.test(str);
接受一个参数:源字符串
返回:找到匹配项,返回true,没找到返回false
4. RegExp构造函数属性
RegExp构造函数包含一些属性,适用于作用域中的所有正则表达式,并且基于所执行的最近一次正则表达式操作而变化。
RegExp.input或RegExp["$_"]:最近一次要匹配的字符串
RegExp.lastMatch或RegExp["$&"]:最近一次匹配项
RegExp.lastParen或RegExp["$+"]:最近一次匹配的捕获组
RegExp.leftContext或RegExp["$`"]:input字符串中lastMatch之前的文本
RegExp.rightContext或RegExp["$'"]:input字符串中lastMatch之后的文本
RegExp["$n"]:表示第n个捕获组的内容,n取1-9
5. String类型上的模式匹配方法
上面提到的exec和test都是在RegExp实例上的方法,调用主体是一个正则表达式,而以字符串为主体调用模式匹配也是最为常用的。
5.1 匹配捕获的match方法
在字符串上调用match方法,本质上和在正则上调用exec相同,但是match方法返回的结果数组是没有input和index属性的。
var str="Reading and Writing"; var pattern=/\b([a-zA-Z]+)ing\b/g; //在String上调用match var matches=str.match(pattern); //等价于在RegExp上调用exec var matches=pattern.exec(str);
5.2 返回索引的search方法
接受的参数和match方法相同,要么是一个正则表达式,要么是一个RegExp对象。
//下面两个控制台输出是一样的,都是5 var str="I am reading."; var pattern=/\b([a-zA-Z]+)ing\b/g; var matches=pattern.exec(str); console.log(matches.index); var pos=str.search(pattern); console.log(pos);
5.3 查找并替换的replace方法
var result=str.replace(RegExp or String, String or Function); 第一个参数(查找):RegExp对象或者是一个字符串(这个字符串就被看做一个平凡的字符串) 第二个参数(替换内容):一个字符串或者是一个函数 返回:替换后的结果字符串,不会改变原来的字符串
第一个参数是字符串
只会替换第一个子字符串
第一个参数是正则
指定g修饰符,则会替换所有匹配正则的地方,否则只替换第一处
第二个参数是字符串
可以使用一些特殊的字符序列,将正则表达式操作的值插进入,这是很常用的。
$n:匹配第n个捕获组的内容,n取0-9
$nn:匹配第nn个捕获组内容,nn取01-99
$`:匹配子字符串之后的字符串
$':匹配子字符串之前的字符串
$&:匹配整个模式得字符串
$$:表示$符号本身
第二个参数是一个函数
在只有一个匹配项的情况下,会传递3个参数给这个函数:模式的匹配项、匹配项在字符串中的位置、原始字符串
在有多个捕获组的情况下,传递的参数是模式匹配项、第一个捕获组、第二个、第三个...最后两个参数是模式的匹配项在字符串位置、原始字符串
这个函数要返回一个字符串,表示要替换掉的匹配项
5.4 分隔字符串的split
基于指定的分隔符将一个字符串分割成多个子字符串,将结果放入一个数组,接受的第一个参数可以是RegExp对象或者是一个字符串(不会被转为正则),第二个参数可选指定数组大小,确保数组不会超过既定大小。
6 JS(ES5)中正则的局限
JS(ES5)中不支持以下正则特性(在一览图中也可以看到):
匹配字符串开始和结尾的\A和\Z锚 向后查找(所以不支持零宽度后发断言) 并集和交集类 原子组 Unicode支持(\uFFFF之后的) 命名的捕获组 单行和无间隔模式 条件匹配 注释
四、ES6对正则的主要加强
ES6对正则做了一些加强,这边仅仅简单罗列以下主要的3点,具体可以去看ES6
1. 构造函数可以传正则字面量了
ES5中构造函数是不能接受字面量的正则的,所以会有双重转义,但是ES6是支持的,即便如此,还是建议用字面量创建,简洁高效。
2. u修饰符
加了u修饰符,会正确处理大于\uFFFF的Unicode,意味着4个字节的Unicode字符也可以被支持了。
// \uD83D\uDC2A是一个4字节的UTF-16编码,代表一个字符
/^\uD83D/u.test('\uD83D\uDC2A')
// false,加了u可以正确处理
/^\uD83D/.test('\uD83D\uDC2A')
// true,不加u,当做两个unicode字符处理
加了u修饰符,会改变一些正则的行为:
.原本只能匹配不大于\uFFFF的字符,加了u修饰符可以匹配任何Unicode字符
Unicode字符新表示法\u{码点}必须在加了u修饰符后才是有效的
使用u修饰符后,所有量词都会正确识别码点大于0xFFFF的Unicode字符
使一些反义元字符对于大于\uFFFF的字符也生效
3. y修饰符
y修饰符的作用与g修饰符类似,也是全局匹配,开始从位置0开始,后一次匹配都从上一次匹配成功的下一个位置开始。
不同之处在于,g修饰符只要剩余位置中存在匹配就可,而y修饰符确保匹配必须从剩余的第一个位置开始。
所以/a/y去匹配"ba"会匹配失败,因为y修饰符要求,在剩余位置第一个位置(这里是位置0)开始就要匹配。
ES6对正则的加强,可以看这篇
五、应用正则的实践思路
应用正则,一般是要先想到正则(废话),只要看到和“找”相关的需求并且这个源是可以被字符串化的,就可以想到用正则试试。
一般在应用正则有两类情况,一是验证类问题,另一类是搜索、提取、替换类问题。验证,最常见的如表单验证;搜索,以某些设定的命令加关键词去搜索;提取,从某段文字中提取什么,或者从某个JSON对象中提取什么(因为JSON对象可以字符串化啊);替换,模板引擎中用到。
1. 验证类问题
验证类问题是我们最常遇到的,这个时候其实源字符串长什么样我们是不知道,鬼知道萌萌哒的用户会做出什么邪恶的事情来,推荐的方式是这样的:
首先用白话描述清楚你要怎样的字符串,描述好了之后,就开脑洞地想用户可能输入什么奇怪的东西,就是自己举例,拿一张纸可举一大堆的,有接受的和不接受的(这个是你知道的),这个过程中可能你会去修改之前的描述;
把你的描述拆解开来,翻译成正则表达式;
测试你的正则表达式对你之前举的例子的判断是不是和你预期一致,这里就推荐用在线的JS正则测试去做,不要自己去一遍遍写了。
2. 搜索、提取、替换类问题
这类问题,一般我们是知道源文本的格式或者大致内容的,所以在解决这类问题时一般已经会有一些测试的源数据,我们要从这些源数据中提取出什么、或者替换什么。
找到这些手上的源数据中你需要的部分;
观察这些部分的特征,这些部分本身的特征以及这些部分周围的特征,比如这部分前一个符号一定是一个逗号,后一个符号一定是一个冒号,总之就是找规律;
考察你找的特征,首先能不能确切地标识出你要的部分,不会少也不会多,然后考虑下以后的源数据也是如此么,以后会不会这些特征就没有了;
组织你对要找的这部分的描述,描述清楚经过你考察的特征;
翻译成正则表达式;
测试。
終於絮絮叨叨寫完了,1萬多字有關JS正則的講解,寫完發現自己對正則的熟練又進了一步,所以推薦大家經常做做梳理,很有用,然後樂於分享,於己於人都是大有裨益,感謝能看完的所有人。
相信看了本文案例你已經掌握了方法,更多精彩請關注php中文網其它相關文章!
推薦閱讀:
以上是解析JS正規的原理與語法的詳細內容。更多資訊請關注PHP中文網其他相關文章!