
Python中基本且又常用的演算法
- 巴扎黑原創
- 2017-08-02 10:27:413536瀏覽
這篇文章主要學習Python常用演算法,Python常用排序演算法,具有一定的參考價值,有興趣的小夥伴可以參考一下
本節內容
演算法定義
時間複雜度
空間複雜度
常用演算法實例
#1.演算法定義
#演算法(Algorithm)是指解題方案的準確而完整的描述,是一系列解決問題的清晰指令,演算法代表著用系統的方法描述解決問題的策略機制。也就是說,能夠對某一規範的輸入,在有限時間內獲得所要求的輸出。如果一個演算法有缺陷,或不適合某個問題,執行這個演算法就不會解決這個問題。不同的演算法可能用不同的時間、空間或效率來完成同樣的任務。一個演算法的優劣可以用空間複雜度與時間複雜度來衡量。
一個演算法應該具有以下七個重要的特徵:
①有窮性(Finiteness):演算法的有窮性是指演算法必須能在執行有限個步驟之後終止;
②確切性(Definiteness):演算法的每一步驟必須有確切的定義;
③輸入項目(Input):一個演算法有0個或多個輸入,以刻畫運算對象的初始情況,所謂0個輸 入是指演算法本身定出了初始條件;
④輸出項(Output):一個演算法有一個或多個輸出,以反映輸入資料加工後的結果。沒 有輸出的演算法是毫無意義的;
⑤可行性(Effectiveness):演算法中執行的任何計算步驟都是可以分解為基本的可執行 的操作步,即每個計算步都可以在有限時間內完成(也稱之為有效性);
⑥高效性(High efficiency):執行速度快,佔用資源少;
⑦健壯性(Robustness) :對數據響應正確。
2. 時間複雜度
電腦科學中,演算法的時間複雜度是一個函數,它定量描述了該演算法的運行時間,時間複雜度常用大O符號(大O符號(Big O notation)是用來描述函數漸進式的數學符號。更確切地說,它是用另一個(通常較簡單的)函數來描述一個函數數量級的漸近上界。 ,使用這種方式時,時間複雜度可稱為是漸近的,它考察當輸入值大小趨近無窮時的情況。
大O,簡而言之可以認為它的意思是「order of」(大約是)。
無窮大漸近
大O符號在分析演算法效率的時候非常有用。舉個例子,解決一個規模為 n 的問題所花費的時間(或所需步驟的數目)可以被求得:T(n) = 4n^2 - 2n + 2。
當n 增加時,n^2; 項將開始占主導地位,而其他各項可以被忽略-舉例說明:當n = 500,4n^2; 項是2n 項的1000倍大,因此在大多數場合下,省略後者對表達式的值的影響將是可以忽略的。
數學表示掃盲貼python演算法表示概念掃盲教學
一、計算方法
1.演算法執行所耗費的時間,從理論上是不能算出來的,必須上機運行測試才能知道。但我們不可能也沒有必要對每個演算法都上機測試,只要知道哪個演算法花費的時間多,哪個演算法花費的時間少就可以了。而一個演算法花費的時間與演算法中語句的執行次數成正比例,哪個演算法中語句執行次數多,它花費時間就多。
一個演算法中的語句執行次數稱為語句頻度或時間頻度。記為T(n)。
2.一般情況下,演算法的基本運算重複執行的次數是模組n的某一個函數f(n),因此,演算法的時間複雜度記做:T( n)=O(f(n))。隨著模組n的增大,演算法執行的時間的成長率和f(n)的成長率成正比,所以f(n)越小,演算法的時間複雜度越低,演算法的效率越高。
在計算時間複雜度的時候,先找出演算法的基本操作,然後根據對應的各語句確定它的執行次數,再找出T(n)的同數量級(它的同數量級有以下:1 ,Log2n ,n ,nLog2n ,n的平方,n的三次方,2的n次方,n!可得到一常數c,則時間複雜度T(n)=O(f(n))。
3.常見的時間複雜度
以數量級遞增排列,常見的時間複雜度有:
常數階O(1), 對數階O(log2n), 線性階O(n), 線性對數階O(nlog2n), 平方階O(n^2), 立方階O(n^3),..., k次方階O(n ^k), 指數階O(2^n) 。
其中,
1.O(n),O(n^2), 立方階O(n^3),..., k次方階O(n^k) 為多項式階時間複雜度,分別稱為一階時間複雜度,二階時間複雜度。 。 。 。
2.O(2^n),指數階時間複雜度,該種不實用
3.對數階O(log2n), 線性對數階O(nlog2n),除了常數階以外,該種效率最高
範例:演算法:
for(i=1;i<=n;++i)
{
for(j=1;j<=n;++j)
{
c[ i ][ j ]=0; //该步骤属于基本操作 执行次数:n^2
for(k=1;k<=n;++k)
c[ i ][ j ]+=a[ i ][ k ]*b[ k ][ j ]; //该步骤属于基本操作 执行次数:n^3
}
} 則有T(n)= n^2+n^3,根據上面括號裡的同數量級,我們可以確定n^3為T(n)的同數量級
則有f(n)= n^3,然後根據T(n)/f(n)求極限可得到常數c
則該演算法的時間複雜度:T(n)=O(n^3)
四、 定義:如果一個問題的規模是n ,解這一問題的某一演算法所需的時間為T(n),它是n的某一函數T(n)稱為此演算法的「時間複雜度」。
當輸入量n逐漸加大時,時間複雜度的極限情形稱為演算法的「漸近時間複雜度」。
我們常用大O表示法表示時間複雜性,注意它是某一個演算法的時間複雜性。大O表示只是說有上界,由定義如果f(n)=O(n),那顯然成立f(n)=O(n^2),它給你一個上界,但並不是上確界,但人們在表示的時候一般都習慣表示前者。
此外,一個問題本身也有它的複雜性,如果某個演算法的複雜性到達了這個問題複雜性的下界,那就稱這樣的演算法是最佳演算法。
「大O記法」:在這個描述中使用的基本參數是 n,也就是問題實例的規模,把複雜性或運行時間表達為n的函數。這裡的「O」表示量級(order),比如說「二分檢索是O(logn)的」,也就是說它需要「透過logn量級的步驟去檢索一個規模為n的數組」記法O ( f(n) )表示當n增大時,運轉時間至多將以正比於f(n)的速度增長。
這種漸進估計對演算法的理論分析和大致比較是非常有價值的,但在實務上細節也可能造成差異。例如,一個低附加代價的O(n2)演算法在n較小的情況下可能比一個高附加代價的 O(nlogn)演算法運行得更快。當然,隨著n夠大以後,具有較慢上升函數的演算法必然會運作得更快。
的頻度均為1,該程序段的執行時間為與問題規模n無關的常數。演算法的時間複雜度為常數階,記作T(n)=O(1)。如果演算法的執行時間不隨著問題規模n的增加而成長,即使演算法中有上千條語句,其執行時間也不過是一個較大的常數。此類演算法的時間複雜度是O(1)。
O(n^2)
2.1. 交換i與j的內容
sum=0; (一次) for(i=1;i81b27cffc0f5ab5b464836c747d510f1左子樹->右子樹
#中序遍歷:左子樹->根節點->右子樹
後序遍歷:左子樹->右子樹->根節點
#例如:求下面樹的三種遍歷
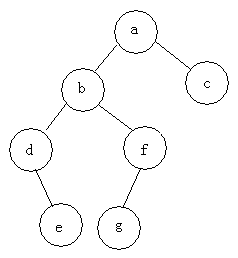
前序遍歷:abdefgc
中序遍歷:debgfac
#後序遍歷:edgfbca
二元樹的類型
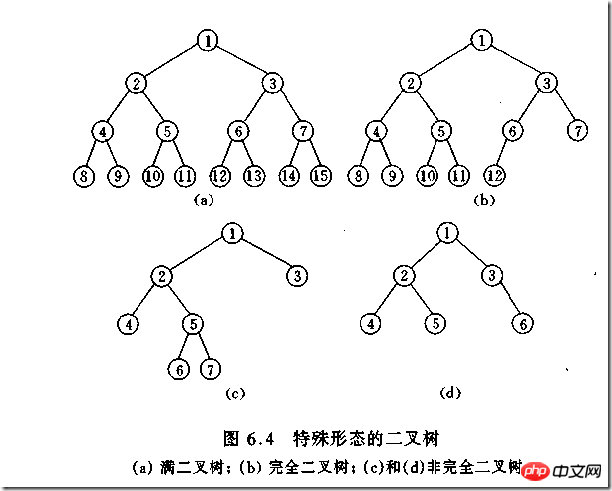
(1)完全二叉树——若设二叉树的高度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第h层有叶子结点,并且叶子结点都是从左到右依次排布,这就是完全二叉树。
(2)满二叉树——除了叶结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树。
(3)平衡二叉树——平衡二叉树又被称为AVL树(区别于AVL算法),它是一棵二叉排序树,且具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树
如何判断一棵树是完全二叉树?按照定义
教材上的说法:一个深度为k,节点个数为 2^k - 1 的二叉树为满二叉树。这个概念很好理解,就是一棵树,深度为k,并且没有空位。
首先对满二叉树按照广度优先遍历(从左到右)的顺序进行编号。
一颗深度为k二叉树,有n个节点,然后,也对这棵树进行编号,如果所有的编号都和满二叉树对应,那么这棵树是完全二叉树。
如何判断平衡二叉树?
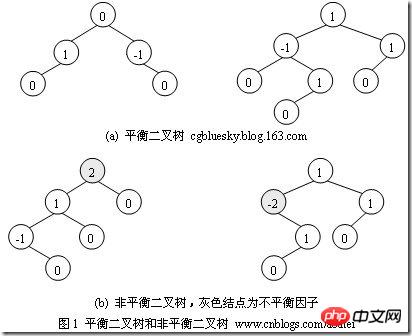
(b)左边的图 左子数的高度为3,右子树的高度为1,相差超过1
(b)右边的图 -2的左子树高度为0 右子树的高度为2,相差超过1
二叉树遍历实现
class TreeNode(object):
def __init__(self,data=0,left=0,right=0):
self.data = data
self.left = left
self.right = right
class BTree(object):
def __init__(self,root=0):
self.root = root
def preOrder(self,treenode):
if treenode is 0:
return
print(treenode.data)
self.preOrder(treenode.left)
self.preOrder(treenode.right)
def inOrder(self,treenode):
if treenode is 0:
return
self.inOrder(treenode.left)
print(treenode.data)
self.inOrder(treenode.right)
def postOrder(self,treenode):
if treenode is 0:
return
self.postOrder(treenode.left)
self.postOrder(treenode.right)
print(treenode.data)
if __name__ == '__main__':
n1 = TreeNode(data=1)
n2 = TreeNode(2,n1,0)
n3 = TreeNode(3)
n4 = TreeNode(4)
n5 = TreeNode(5,n3,n4)
n6 = TreeNode(6,n2,n5)
n7 = TreeNode(7,n6,0)
n8 = TreeNode(8)
root = TreeNode('root',n7,n8)
bt = BTree(root)
print("preOrder".center(50,'-'))
print(bt.preOrder(bt.root))
print("inOrder".center(50,'-'))
print (bt.inOrder(bt.root))
print("postOrder".center(50,'-'))
print (bt.postOrder(bt.root))堆排序
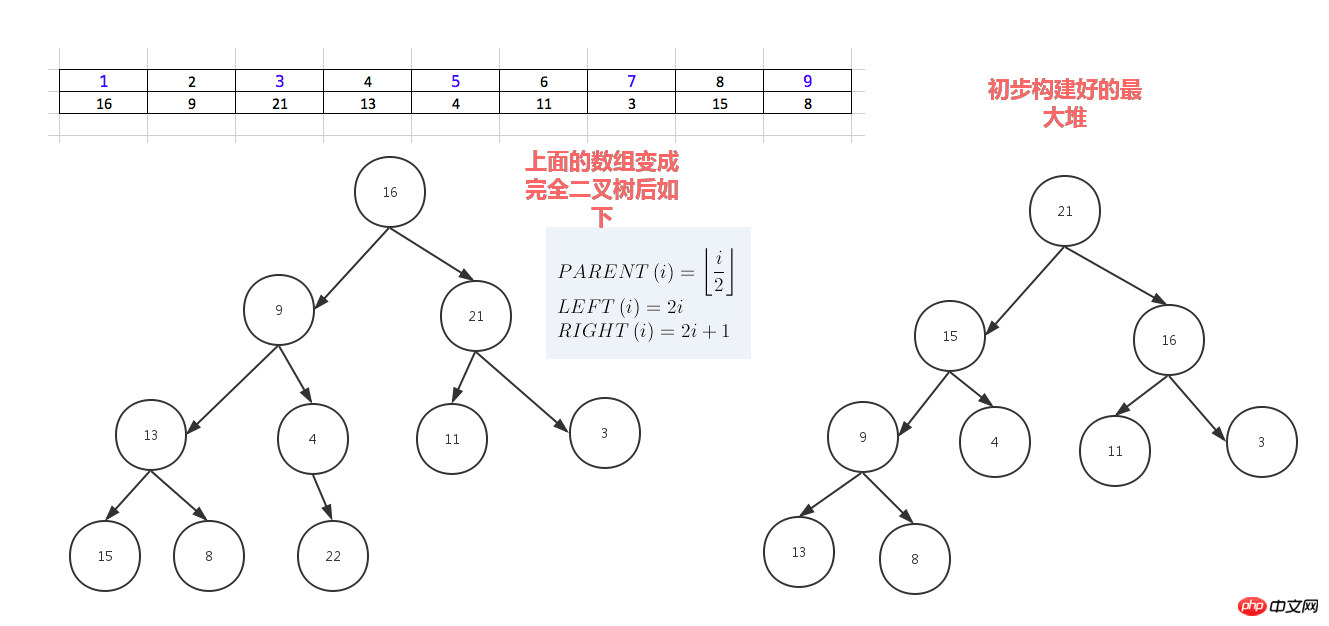
堆排序,顾名思义,就是基于堆。因此先来介绍一下堆的概念。
堆分为最大堆和最小堆,其实就是完全二叉树。最大堆要求节点的元素都要大于其孩子,最小堆要求节点元素都小于其左右孩子,两者对左右孩子的大小关系不做任何要求,其实很好理解。有了上面的定义,我们可以得知,处于最大堆的根节点的元素一定是这个堆中的最大值。其实我们的堆排序算法就是抓住了堆的这一特点,每次都取堆顶的元素,将其放在序列最后面,然后将剩余的元素重新调整为最大堆,依次类推,最终得到排序的序列。
堆排序就是把堆顶的最大数取出,
将剩余的堆继续调整为最大堆,具体过程在第二块有介绍,以递归实现
剩余部分调整为最大堆后,再次将堆顶的最大数取出,再将剩余部分调整为最大堆,这个过程持续到剩余数只有一个时结束
#_*_coding:utf-8_*_
__author__ = 'Alex Li'
import time,random
def sift_down(arr, node, end):
root = node
#print(root,2*root+1,end)
while True:
# 从root开始对最大堆调整
child = 2 * root +1 #left child
if child > end:
#print('break',)
break
print("v:",root,arr[root],child,arr[child])
print(arr)
# 找出两个child中交大的一个
if child + 1 <= end and arr[child] < arr[child + 1]: #如果左边小于右边
child += 1 #设置右边为大
if arr[root] < arr[child]:
# 最大堆小于较大的child, 交换顺序
tmp = arr[root]
arr[root] = arr[child]
arr[child]= tmp
# 正在调整的节点设置为root
#print("less1:", arr[root],arr[child],root,child)
root = child #
#[3, 4, 7, 8, 9, 11, 13, 15, 16, 21, 22, 29]
#print("less2:", arr[root],arr[child],root,child)
else:
# 无需调整的时候, 退出
break
#print(arr)
print('-------------')
def heap_sort(arr):
# 从最后一个有子节点的孩子还是调整最大堆
first = len(arr) // 2 -1
for i in range(first, -1, -1):
sift_down(arr, i, len(arr) - 1)
#[29, 22, 16, 9, 15, 21, 3, 13, 8, 7, 4, 11]
print('--------end---',arr)
# 将最大的放到堆的最后一个, 堆-1, 继续调整排序
for end in range(len(arr) -1, 0, -1):
arr[0], arr[end] = arr[end], arr[0]
sift_down(arr, 0, end - 1)
#print(arr)
def main():
# [7, 95, 73, 65, 60, 77, 28, 62, 43]
# [3, 1, 4, 9, 6, 7, 5, 8, 2, 10]
#l = [3, 1, 4, 9, 6, 7, 5, 8, 2, 10]
#l = [16,9,21,13,4,11,3,22,8,7,15,27,0]
array = [16,9,21,13,4,11,3,22,8,7,15,29]
#array = []
#for i in range(2,5000):
# #print(i)
# array.append(random.randrange(1,i))
print(array)
start_t = time.time()
heap_sort(array)
end_t = time.time()
print("cost:",end_t -start_t)
print(array)
#print(l)
#heap_sort(l)
#print(l)
if __name__ == "__main__":
main()人类能理解的版本
dataset = [16,9,21,3,13,14,23,6,4,11,3,15,99,8,22]
for i in range(len(dataset)-1,0,-1):
print("-------",dataset[0:i+1],len(dataset),i)
#for index in range(int(len(dataset)/2),0,-1):
for index in range(int((i+1)/2),0,-1):
print(index)
p_index = index
l_child_index = p_index *2 - 1
r_child_index = p_index *2
print("l index",l_child_index,'r index',r_child_index)
p_node = dataset[p_index-1]
left_child = dataset[l_child_index]
if p_node < left_child: # switch p_node with left child
dataset[p_index - 1], dataset[l_child_index] = left_child, p_node
# redefine p_node after the switch ,need call this val below
p_node = dataset[p_index - 1]
if r_child_index < len(dataset[0:i+1]): #avoid right out of list index range
#if r_child_index < len(dataset[0:i]): #avoid right out of list index range
#print(left_child)
right_child = dataset[r_child_index]
print(p_index,p_node,left_child,right_child)
# if p_node < left_child: #switch p_node with left child
# dataset[p_index - 1] , dataset[l_child_index] = left_child,p_node
# # redefine p_node after the switch ,need call this val below
# p_node = dataset[p_index - 1]
#
if p_node < right_child: #swith p_node with right child
dataset[p_index - 1] , dataset[r_child_index] = right_child,p_node
# redefine p_node after the switch ,need call this val below
p_node = dataset[p_index - 1]
else:
print("p node [%s] has no right child" % p_node)
#最后这个列表的第一值就是最大堆的值,把这个最大值放到列表最后一个, 把神剩余的列表再调整为最大堆
print("switch i index", i, dataset[0], dataset[i] )
print("before switch",dataset[0:i+1])
dataset[0],dataset[i] = dataset[i],dataset[0]
print(dataset)希尔排序(shell sort)
希尔排序(Shell Sort)是插入排序的一种。也称缩小增量排序,是直接插入排序算法的一种更高效的改进版本,该方法的基本思想是:先将整个待排元素序列分割成若干个子序列(由相隔某个“增量”的元素组成的)分别进行直接插入排序,然后依次缩减增量再进行排序,待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次直接插入排序。因为直接插入排序在元素基本有序的情况下(接近最好情况),效率是很高的,因此希尔排序在时间效率比直接插入排序有较大提高
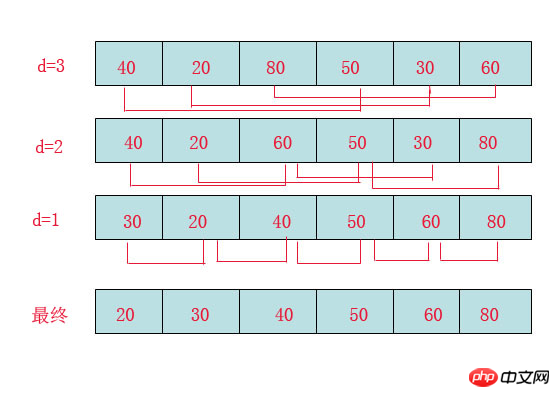
首先要明确一下增量的取法:
第一次增量的取法为: d=count/2;
第二次增量的取法为: d=(count/2)/2;
最后一直到: d=1;
看上图观测的现象为:
d=3时:将40跟50比,因50大,不交换。
将20跟30比,因30大,不交换。
将80跟60比,因60小,交换。
d=2时:将40跟60比,不交换,拿60跟30比交换,此时交换后的30又比前面的40小,又要将40和30交换,如上图。
将20跟50比,不交换,继续将50跟80比,不交换。
d=1时:这时就是前面讲的插入排序了,不过此时的序列已经差不多有序了,所以给插入排序带来了很大的性能提高。
希尔排序代码
import time,random
#source = [8, 6, 4, 9, 7, 3, 2, -4, 0, -100, 99]
#source = [92, 77, 8,67, 6, 84, 55, 85, 43, 67]
source = [ random.randrange(10000+i) for i in range(10000)]
#print(source)
step = int(len(source)/2) #分组步长
t_start = time.time()
while step >0:
print("---step ---", step)
#对分组数据进行插入排序
for index in range(0,len(source)):
if index + step < len(source):
current_val = source[index] #先记下来每次大循环走到的第几个元素的值
if current_val > source[index+step]: #switch
source[index], source[index+step] = source[index+step], source[index]
step = int(step/2)
else: #把基本排序好的数据再进行一次插入排序就好了
for index in range(1, len(source)):
current_val = source[index] # 先记下来每次大循环走到的第几个元素的值
position = index
while position > 0 and source[
position - 1] > current_val: # 当前元素的左边的紧靠的元素比它大,要把左边的元素一个一个的往右移一位,给当前这个值插入到左边挪一个位置出来
source[position] = source[position - 1] # 把左边的一个元素往右移一位
position -= 1 # 只一次左移只能把当前元素一个位置 ,还得继续左移只到此元素放到排序好的列表的适当位置 为止
source[position] = current_val # 已经找到了左边排序好的列表里不小于current_val的元素的位置,把current_val放在这里
print(source)
t_end = time.time() - t_start
print("cost:",t_end)以上是Python中基本且又常用的演算法的詳細內容。更多資訊請關注PHP中文網其他相關文章!