
PHP一些簡單測試
- 巴扎黑原創
- 2017-07-19 17:02:594898瀏覽
php-ml是使用PHP編寫的機器學習函式庫。雖然我們知道,python或C++提供了更多機器學習的函式庫,但實際上,他們大多都略顯複雜,配置起來讓許多新手感到絕望。 php-ml這個機器學習庫雖然沒有特別高大上的演算法,但其具有最基本的機器學習、分類等演算法,我們的小公司做一些簡單的資料分析、預測等等都是夠用的。在我們的專案中,追求的應該是性價比,而不是過度的效率和精確度。有些演算法和函式庫看起來非常厲害,但如果我們考慮快速上線,而我們的技術人員沒有機器學習方面的經驗,那麼複雜的程式碼和配置反而會拖累我們的專案。而如果我們本身就是做一個簡單的機器學習應用,那麼研究複雜函式庫和演算法的學習成本很顯然高了點,而且,專案出了奇奇怪怪的問題,我們能解決嗎?需求改變了怎麼辦?相信大家都有過這種經驗:做著做著,程序忽然報錯,自己怎麼都搞不清楚原因,上谷歌或百度一搜,只搜出一條滿足條件的問題,在五年、十年前提問,然後零回覆。 。 。所以,選擇最簡單最有效率、性價比最高的做法是必須的。 php-ml的速度不算慢(趕快換php7吧),精確度也不錯,畢竟演算法都一樣,而且php是基於c的。部落客最看不慣的就是,拿python和Java,PHP之間比性能,比適用範圍。真要性能,請你拿C開發。真要追求適用範圍,也請用C,甚至彙編。 。 。
首先,我們要使用這個函式庫,需要先下載這個函式庫。在github可以下載到這個庫檔案()。當然,更推薦使用composer來下載該庫,自動配置。
下載好了以後,我們可以看看這個庫的文檔,文檔都是一些簡單的小範例,我們可以自己建立一個文件嘗試一下。都淺顯易懂。接下來,我們來拿實際的數據測試一下。資料集一個是Iris花蕊的資料集,另一個因為記錄遺失,所以不知道是有關什麼的資料了。 。 。
Iris花蕊部分數據,有三種不同的分類:
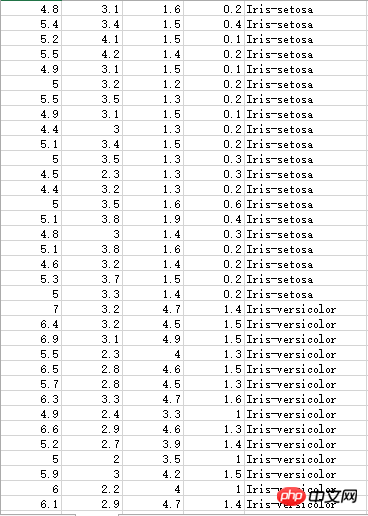 還要處理一下:
還要處理一下: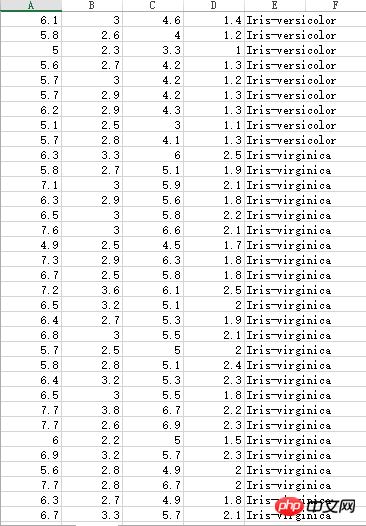
我們先處理不知名資料集。首先,我們的不知名資料集的檔案名稱為data.txt。而這個資料集剛好可以先繪製成x-y折線圖。所以,我們先將原始資料繪製成一個折線圖。由於x軸比較長,所以我們只需要看清楚它大致的形狀即可:


1 <?php 2 include_once './src/jpgraph.php'; 3 include_once './src/jpgraph_line.php'; 4 5 $g = new Graph(1920,1080);//jpgraph的绘制操作 6 $g->SetScale("textint"); 7 $g->title->Set('data'); 8 9 //文件的处理10 $file = fopen('data.txt','r');11 $labels = array();12 while(!feof($file)){13 $data = explode(' ',fgets($file));
14 $data[1] = str_replace(',','.',$data[1]);//数据处理,将数据中的逗号修正为小数点15 $labels[(int)$data[0]] = (float)$data[1];//这里将数据以键值的方式存入数组,方便我们根据键来排序16 }
17 18 ksort($labels);//按键的大小排序19 20 $x = array();//x轴的表示数据21 $y = array();//y轴的表示数据22 foreach($labels as $key=>$value){23 array_push($x,$key);24 array_push($y,$value);25 }26 27 28 $linePlot = new LinePlot($y);29 $g->xaxis->SetTickLabels($x);
30 $linePlot->SetLegend('data');31 $g->Add($linePlot);32 $g->Stroke();
 在有了這個原圖做對比,我們接下來進行學習。我們採用php-ml的LeastSquars來學習。我們測試的輸出需要存入文件,方便我們可以畫一個對比圖。學習程式碼如下:
在有了這個原圖做對比,我們接下來進行學習。我們採用php-ml的LeastSquars來學習。我們測試的輸出需要存入文件,方便我們可以畫一個對比圖。學習程式碼如下:
1 <?php 2 require 'vendor/autoload.php'; 3 4 use Phpml\Regression\LeastSquares; 5 use Phpml\ModelManager; 6 7 $file = fopen('data.txt','r'); 8 $samples = array(); 9 $labels = array();10 $i = 0;11 while(!feof($file)){12 $data = explode(' ',fgets($file));13 $samples[$i][0] = (int)$data[0];14 $data[1] = str_replace(',','.',$data[1]);15 $labels[$i] = (float)$data[1];16 $i ++;17 }
18 fclose($file);19 20 $regression = new LeastSquares();21 $regression->train($samples,$labels);22 23 //这个a数组是根据我们对原数据处理后的x值给出的,做测试用。24 $a = [0,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,20,22,23,24,25,26,27,29,30,31,37,40,41,45,48,53,55,57,60,61,108,124];25 for($i = 0; $i < count($a); $i ++){26 file_put_contents("putput.txt",($regression->predict([$a[$i]]))."\n",FILE_APPEND); //以追加的方式存入文件 27 }
1 <?php 2 include_once './src/jpgraph.php'; 3 include_once './src/jpgraph_line.php'; 4 5 $g = new Graph(1920,1080); 6 $g->SetScale("textint"); 7 $g->title->Set('data'); 8 9 $file = fopen('putput.txt','r');10 $y = array();11 $i = 0;12 while(!feof($file)){13 $y[$i] = (float)(fgets($file));14 $i ++;
15 }
16 17 $x = [0,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,20,22,23,24,25,26,27,29,30,31,37,40,41,45,48,53,55,57,60,61,108,124];18 19 $linePlot = new LinePlot($y);20 $g->xaxis->SetTickLabels($x);
21 $linePlot->SetLegend('data');22 $g->Add($linePlot);23 $g->Stroke();
可以发现,图形出入还是比较大的,尤其是在图形锯齿比较多的部分。不过,这毕竟是40组数据,我们可以看出,大概的图形趋势是吻合的。一般的库在做这种学习时,数据量低的情况下,准确度都非常低。要达到比较高的精度,需要大量的数据,万条以上的数据量是必要的。如果达不到这个数据要求,那我们使用任何库都是徒劳的。所以,机器学习的实践中,真正难的不在精度低、配置复杂等技术问题,而是数据量不够,或者质量太低(一组数据中无用的数据太多)。在做机器学习之前,对数据的预先处理也是必要的。
接下来,我们来对花蕊数据进行测试。一共三种分类,由于我们下载到的是csv数据,所以我们可以使用php-ml官方提供的操作csv文件的方法。而这里是一个分类问题,所以我们选择库提供的SVC算法来进行分类。我们把花蕊数据的文件名定为Iris.csv,代码如下:
1 <?php 2 require 'vendor/autoload.php'; 3 4 use Phpml\Classification\SVC; 5 use Phpml\SupportVectorMachine\Kernel; 6 use Phpml\Dataset\CsvDataset; 7 8 $dataset = new CsvDataset('Iris.csv' , 4, false); 9 $classifier = new SVC(Kernel::LINEAR,$cost = 1000);10 $classifier->train($dataset->getSamples(),$dataset->getTargets());11 12 echo $classifier->predict([$argv[1],$argv[2],$argv[3],$argv[4]]);//$argv是命令行参数,调试这种程序使用命令行较方便
是不是很简单?短短12行代码就搞定了。接下来,我们来测试一下。根据我们上面贴出的图,当我们输入5 3.3 1.4 0.2的时候,输出应该是Iris-setosa。我们看一下:

看,至少我们输入一个原来就有的数据,得到了正确的结果。但是,我们输入原数据集中没有的数据呢?我们来测试两组:
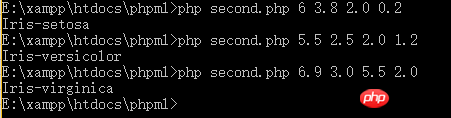
由我们之前贴出的两张图的数据看,我们输入的数据在数据集中并不存在,但分类按照我们初步的观察来看,是合理的。
所以,这个机器学习库对于大多数的人来说,都是够用的。而大多数鄙视这个库鄙视那个库,大谈性能的人,基本上也不是什么大牛。真正的大牛已经忙着捞钱去了,或者正在做学术研究等等。我们更多的应该是掌握算法,了解其中的道理和玄机,而不是夸夸其谈。当然,这个库并不建议用在大型项目上,只推荐小型项目或者个人项目等。
以上是PHP一些簡單測試的詳細內容。更多資訊請關注PHP中文網其他相關文章!