
SQL Server 磁碟請求逾時的833錯誤原因及解決方法_MsSql

- 微波原創
- 2017-06-28 15:41:282541瀏覽
這篇文章主要介紹了SQL Server 磁碟請求逾時的833錯誤原因及解決方法,需要的朋友可以參考下
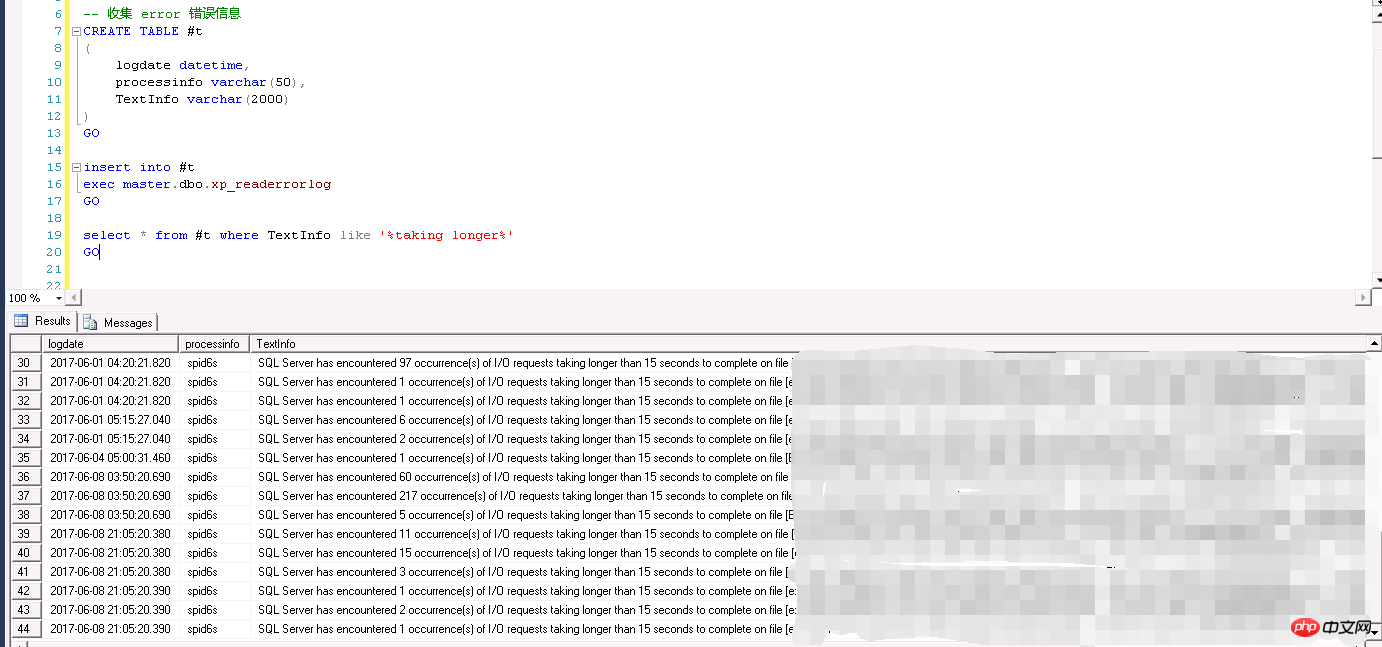
最近遇到一個SQL Server伺服器回應極度緩慢,並且出現客戶端請求報錯的情況,在資料庫中的errorlog中出現磁碟請求超過15s才完成的error訊息。
對於這類問題,到底是儲存系統或磁碟的故障,還是SQL Server 自己的問題,亦或是應用程式引發的呢?又要如何解決?
本文將對引起此問題的某一方面的因素進行簡單的分析,但是無法涵蓋所有潛在的可能性,因此遇到類似問題還要做具體的分析。
SQL Server中的磁碟請求逾時
# 該錯誤的英文版的錯誤訊息如下:
# SQL Server has encountered %d occurrence(s) of I/O requests taking longer than %d seconds to complete on file [%ls] in database id %d. The OS file handle is 0x%p. 0# # The offset of the latest long I/O is: %#016I64x
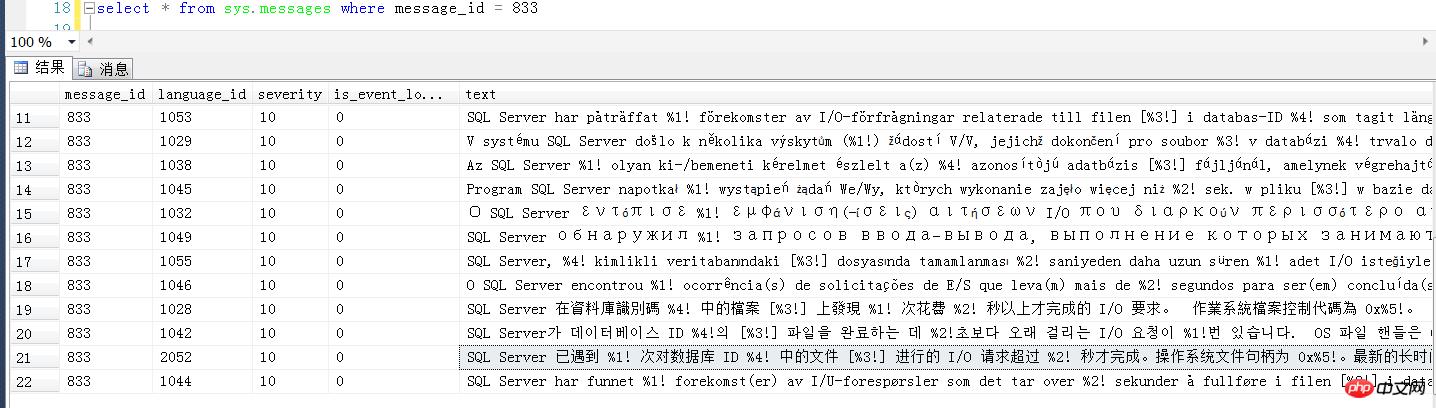
資料庫引擎錯誤833的含義
# 首先來看這個833錯誤的具體含義是什麼,就不自己裝13解釋一通了,那本經典的書上寫的很清楚了。 總之,意思就是,SQL Server在請求磁碟讀寫的時候,遇到磁碟繁忙或其他一些因素,超過了15秒還沒完成 例如資料的讀寫的時候需要向磁碟發起請求,而磁碟正忙或其他問題,來不及或相應的不夠及時,這無疑會嚴重影響SQL Server對外提供伺服器的回應時間。

原因分析
# 因為是專門的SQL Server伺服器,沒有其他應用程式的請求,很有可能跟向sqlserver資料庫發起的請求有關。 其實發生這個問題之前,早就有預兆了,平時還算穩定的伺服器(CPU很少超過60%,記憶體的PLE也可以穩定在20分鐘以上,磁碟IO延遲較低等等),只是偶爾會存在抽風一陣子的情況 抽風的時候表現為CPU狂飆到80%左右,內存的PLE會嚴重下降,IO延遲嚴重增高。 現在只能從SQL Server的Session入手,在觀察SQL Server中的活動Session的時候,發現某一類別的SQL語句的查詢時間非常長, 平時這類SQL在某一個時間段內執行的頻率還算比較高。
但是正常情況下,這類SQL的執行效率還是比較高的,為什麼突然就變的非常之底?
在檢查活動Session的對應的執行計劃的時候,發現這類活動Session的等待狀態都是IO等待(PAGEIOLATCH_SH),同時SQL的執行完全是意料之外的執行方式。
因為類似查詢還是執行的比較頻繁的,此類Session會從不同的客戶端發起,一旦SQL的執行效率降下來,伺服器上會積壓大量的活動Session
# 為什麼平常執行的好好的SQL語句突然就變的很慢很慢,
原因就在於在某一點,SQL Server自動觸發了統計資訊的更新,但是這是一個比較大的表,但是預設統計資訊更新的取樣比例是不夠的,如果取樣百分比不夠,這個統計資料完全是不可用的。
一旦自動收集統計信息完成之後,會根據當前收集到的統計信息,向之前的SQL語句發出一種它認為高效的方式(table scan而不是index seek),其實這種方式並非是合理的,
由此引發對應的SQL利用一種並非合理的執行計劃來實現查詢,同時會引發Session的擁堵,客戶端發過來大量的Session同時在利用一種低效的方式緩慢執行。
所以CPU會飆升,IO延遲增加,記憶體的PLE嚴重下降。
由此也不難理解,數十個查詢的Session正在以一種不合理的方式瘋狂地想磁碟發出請求,磁碟正在忙於活動Session的資料請求,出現無法回應因為資料或索引檔案的自動成長請求,造成一開始說的問題。
最後經過索引重建(促使統計資訊更新,當然純粹的統計資訊更新也可以)解決,長期預防的話,需要安排job人為地定義統計資訊更新的閾值以及取樣百分比。
總結:
資料庫伺服器上的問題,很多問題都是一個連鎖反應的過程,對應觀察到的部分現象,很有可能並不是表面上的反應的那樣(磁碟請求超時,問題出在存儲上?)
專業的位置上必須要有專業的素養,比如一開始DBA誤以為是存儲問題,存儲工程師認為服務器內存用滿了是不正常的等,其實都不是問題的根本原因。
面對問題,要追本溯源,找出來最根本的原因,才是解決問題的關鍵。
以上是SQL Server 磁碟請求逾時的833錯誤原因及解決方法_MsSql的詳細內容。更多資訊請關注PHP中文網其他相關文章!