
Python--BeautifulSoup函式庫的介紹

- 零下一度原創
- 2017-06-23 11:14:513124瀏覽
Beautiful Soup parses anything you give it, and does the tree traversal stuff for you.
BeautifulSoup庫是解析、遍歷、維護「標籤樹」 的功能庫(遍歷,是指沿著某條搜尋路線,依序對樹中每個結點均做一次且僅做一次訪問)。
BeautifulSoup函式庫我們常稱為bs4,匯入該函式庫為:from bs4 import BeautifulSoup。其中,import BeautifulSoup即主要用bs4中的BeautifulSoup類別。
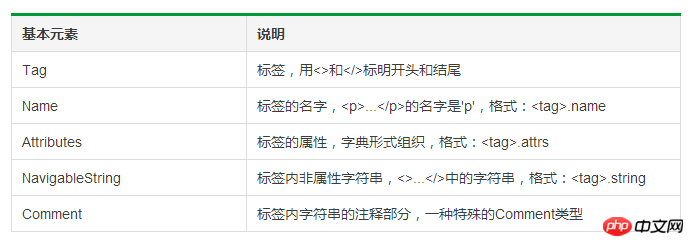
bs4庫解析器
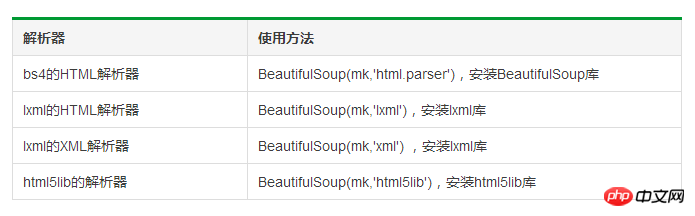
#BeautifulSoup類別的基本元素
1 import requests 2 from bs4 import BeautifulSoup 3 4 res = requests.get('') 5 soup = BeautifulSoup(res.text,'lxml') 6 print(soup.a) 7 # 任何存在于HTML语法中的标签都可以用soup.<tag>访问获得,当HTML文档中存在多个相同<tag>对应内容时,soup.<tag>返回第一个。 8 9 print(soup.a.name)10 # 每个<tag>都有自己的名字,可以通过<tag>.name获取,字符串类型11 12 print(soup.a.attrs)13 print(soup.a.attrs['class'])14 # 一个<tag>可能有一个或多个属性,是字典类型15 16 print(soup.a.string)17 # <tag>.string可以取到标签内非属性字符串18 19 soup1 = BeautifulSoup('<p><!--这里是注释--></p>','lxml')20 print(soup1.p.string)21 print(type(soup1.p.string))22 # comment是一种特殊类型,也可以通过<tag>.string取到#運行結果:
a
# {'href': '', 'class': ['no- login']} ['no-login']
登入
這裡是註解
#bs4函式庫的HTML內容遍歷
HTML的基本結構
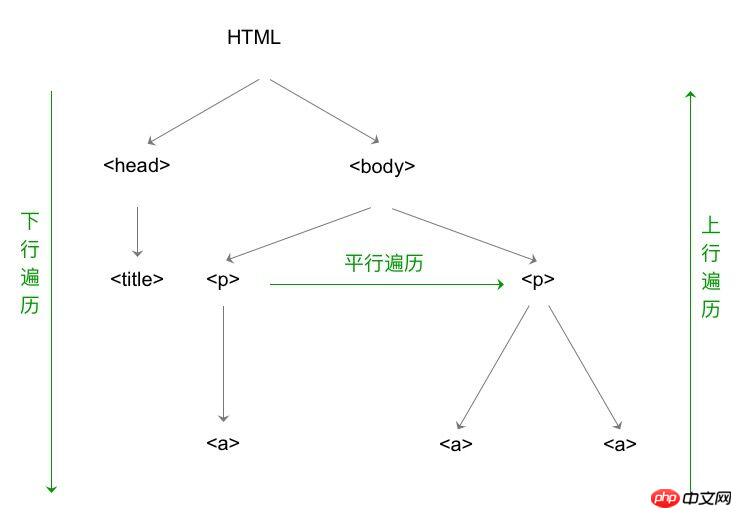
標籤樹的下行遍歷
其中,BeautifulSoup類型是標籤樹的根節點。
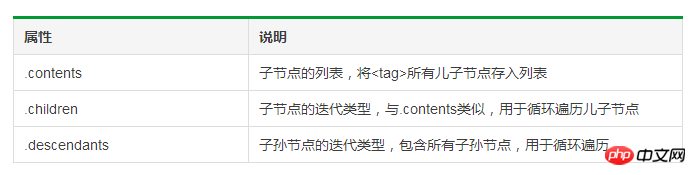
1 # 遍历儿子节点2 for child in soup.body.children:3 print(child.name)4 5 # 遍历子孙节点6 for child in soup.body.descendants:7 print(child.name)
標籤樹的上行遍歷

1 # 遍历所有先辈节点时,包括soup本身,所以要if...else...判断2 for parent in soup.a.parents:3 if parent is None:4 print(parent)5 else:6 print(parent.name)
#運行結果:
div
#div
body
html 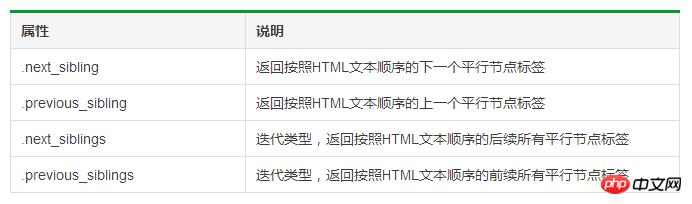
#標籤樹的平行遍歷
1 # 遍历后续节点2 for sibling in soup.a.next_sibling:3 print(sibling)4 5 # 遍历前续节点6 for sibling in soup.a.previous_sibling:7 print(sibling)
#bs4函式庫的prettify()方法############prettify( )方法可以將程式碼格式搞的標準一些,用soup.prettify()表示。在PyCharm中,用print(soup.prettify())來輸出。 #########操作環境:Mac,Python 3.6,PyCharm 2016.2############參考資料:中國大學MOOC課程《Python網路爬蟲與資訊擷取》#### ##
以上是Python--BeautifulSoup函式庫的介紹的詳細內容。更多資訊請關注PHP中文網其他相關文章!
陳述:
本文內容由網友自願投稿,版權歸原作者所有。本站不承擔相應的法律責任。如發現涉嫌抄襲或侵權的內容,請聯絡admin@php.cn
上一篇:python中re正規模組詳解下一篇:python中re正規模組詳解