
Python中物件導向的實例教程

- 零下一度原創
- 2017-06-23 11:22:561393瀏覽
一. 生成器和迭代器
1. 生成器
生成器具有一种生成的能力,它仅仅代表着一种生成的能力,当我们需要使用的时候,才会通过迭代器去生成它。因为他只代表这一种生成的能力,因此,生成器比较节省内存,它一般通过yield来区分生成的位置。通过next来找到下一个位置。
# 当直接去执行genetor函数的时候,会先返回一个1,然后就退出了,因为遇到了yield# 当用一个next之后就会执行2. 然后继续退出# 也就是说yield其实是生成器的一个地址保存机制,只有通过next才会使他的地址指向下一个yielddef genetor():print(1)yield 1print(2)yield 2print(3)yield 3print(4)yield 4obj=genetor() a = obj.__next__() b = obj.__next__() c = obj.__next__() d = obj.__next__()
书写一个xrange函数
def xrange(args): value = 0while True:if value >= args:returnelse:yield value value += 1for i in xrange(5):print(i)
2. 迭代器
迭代器代表这个一种访问的能力,他能够通过一次次的next去迭代生成器产生的对象,因此,他能够得到我们想要得到的数据。for循环就是一种迭代器。如上面的代码,我们可以通过for循环去迭代生成器。
二. 字符串格式化
1. 字符串的格式化
字符串的格式化比拼接的方式更加有效
字符串的格式化更加的方便
2. %格式化
%[(name)][flags][width].[precision]typecode [(name)]
格式:%[(name)][flags][width].[precision]typecode (name): 可选的,用于选择指定的key flags: 输入的格式是左对齐还是右对齐,和width一块使用,+ 右对齐, 正数前面加+号, 负数前面加-号- 不变,就是左对齐 空格 不变,就是右对齐 0 右对齐,前面填充0 width 可选,占有的宽度 .precision 小数点后保留的位数 typecode s 字符串 f 有精度的数 d 整数
事例:
 字符串
字符串

s1 = "I am %+10d, age %-10d, % 10d %010d" % (10, 10, 10, 10) s2 = "I am %+10d, age %-10d, % 10d %010d" % (-10, -10, -10, -10)print(s1)print(s2) 结果: I am +10, age 10 , 10 0000000010I am -10, age -10 , -10 -000000010
# 常用事例:
s1 = "I am %s" % "hu"
s2 = "I am %(name)s, age%(age)s" % {"name": "hu", "age": 13}
s3 = "3.335 + 4.2345 = %2.f" % 7.23566
print(s1, s2, s3)3. format格式化的常用方法
[[fill]align][sign][#][0][width][,][.precision][type] 这个是format的格式,很多和%都是一样的,下面只列举一下关于它的常见用法
s1 = "i am {}, {}, {}".format("hu", "zhou", "12")
s1 = "I am {}, {}, {}".format(*["hu", "zhou", "12"])
s1 = "I am {0}, {1}, {0}".format("seven", 18)
s1 = "I am {0}, {1}, {0}".format(*["seven", 19])
s1 = "I am {name}, {age}, {name}".format(name="hu", age=11)
s1 = "I am {name}, {age}, {name}".format(**{"name":"hu", "age":11})
s1 = "I am {:s}, {:d}, {:f}".format("hu", 18, 1823.923)
s1 = "{:b},{:x},{:o}".format(10,10,10)
s1 = "{:#b},{:#x},{:#o}".format(10,10,10)三. 内置函数vars
{: , : None, : None, : 1ab075f0eefa53e6174d0b3147270dff, : None, : None, : , : dd92c9fb297397c4cea5343c81bd612c}1. __file__ 当前工作的环境的绝对路径
2. __name__ 如果是在当前工作目录,则返回的是__main__, 如果是导入的模块,返回的就是模块的名字
3. __packge__
4. __doc__ 这个变量保存的是这个文件的说明,也就是在文件开头部分对这个文件功能的说明
5. __cached__ 这个是缓存,如果是导入的模块就会有缓存
6. __builtins__ 这个是内置函数
'''这个是一个测试文档 文档名称为test'''import indexprint(index.__name__)print(__name__)print(__file__)print(__doc__)print(index.__cached__) 显示结果: index__main__C:/Users/zhou/PycharmProjects/fullstack2/6_20/test.py 这个是一个测试文档 文档名称为test C:\Users\zhou\PycharmProjects\fullstack2\6_20\__pycache__\index.cpython-35.pyc
四. 反射
1. 反射的定义
反射就是通过字符串的形式去某个对象中操作它的成员。
2. __import__方法和import的区别
f35d6e602fd7d0f0edfa6f7d103c1b57. __import__可以通过字符串导入模块
2cc198a1d5eb0d3eb508d858c9f5cbdb. import 不能通过字符串来导入模块
简单的import和__import__
# 此处s3是一个函数的名字# 对于字符串,直接import导入会报错,# 需要用__import__去导入,就相当于是import s3 # import "s3"module = __import__("s3")
module.f3()扩展的__import__, 当我们需要导入层级的模块的时候,需要用到fromlist参数
# lib目录下有个模块order,要导入的话就需要以下方法module = __import__("lib.order", fromlist=True)print(module.add_order())3. 反射的方法
f35d6e602fd7d0f0edfa6f7d103c1b57. hasattr(模块, 关键字) 判断关键字是否在模块中,在的话返回true,不在的话返回false
2cc198a1d5eb0d3eb508d858c9f5cbdb. getattr(模块, 关键字) 如果关键字是一个函数,则返回函数,如果是一个变量,就返回变量(里面的关键字传递的都是字符串,如果是函数,字符串默认是使用不了的,通过这个函数可以转换成使用的函数)
5bdf4c78156c7953567bb5a0aef2fc53. setattr(模块, 关键字, 值) 往模块中加入关键字,加入的可以是变量, 可以是函数,加入和删除都是在内存中完成的,并不会影响文件的内容
23889872c2e8594e0f446a471a78ec4c. delattr(模块,关键字) 从模块中删除关键字


s3的内容def f1():print("f1")=============================# 导入s3,判断关键字是否在s3中import s3
ret1 = hasattr(s3, "f1")
ret2 = hasattr(s3, "f11")print(ret1)print(ret2)
结果:
True
False

# 导入模块,通过字符串得到模块内函数# 然后执行函数# 字符串f1 是执行不了的,只能通过getattr得到函数在执行import s3 func = getattr(s3, 'f1') func()


# setattr传递的是一个键值对,而hasattr判断的只是键,而不是值,# 因为刚开始还没有这个“name”,所以返回的是false,通过setattr设置了这个键,所以返回的是Trueimport s3print(hasattr(s3, "name")) setattr(s3, "name", "hu")print(hasattr(s3, "name")) 结果: False True


# 开始f1是存在的,所以返回True# 通过del删除之后,在返回的就是False了import s3print(hasattr(s3, "f1")) delattr(s3, "f1")print(hasattr(s3, "f1")) 结果: True False


url = input("请输入url:")
target_module, target_func = url.split("/")print(target_func, target_module)
module = __import__("lib."+target_module, fromlist=True)print(module)if hasattr(module, target_func):# module.target_func()target_func = getattr(module, target_func)
target_func()else:print("404")五. 面向对象编程
1. 编程
其实在我们日常生活中,编程的方式有很多,例如:面向过程,面向对象,或者是函数式编程,他们的区别还蛮大的,但是最终的目的只有一个,那就是简化工作量。就像是盖房子,面向过程就是我要自己去买砖买瓦,自己垒砌,然后函数式编程就是我自己买砖买瓦,然后找木匠工人给我做,面向对象就是,我要直接买一套房子,省的自己做了。
2. 面向对象编程
(1). 定义类
类是什么呢?类严格的定义是由某种特定的元数据所组成的内聚的包。他是由多个函数共同组成的为了完成某种功能的组合。既然有了函数,为什么还要类呢?当我们的函数出现大量的相同的参数或者相同的功能的时候,就需要类来简化其操作了
# 关键字class创建了一个类,类名为Foo# 定义了三个方法,__init__ f1和f2 # 方法里面的self为默认的参数,必须带class Foo:def __init__(self):
self.Name = "hu"def f1(self):print("f1")def f2(self):print("f1")(2). 执行类(创建对象)
对象是什么呢?在Python中,一切皆对象,当我们创建了一类数据之后,他只是一类数据,其中的方法,参数都都是泛华的东西,我们需要有一个对象来对其进行实例化。也就是说,当我们说:这有个人。你肯定不知道他是谁,因为他只代表了一类数据,当我们说:他是李刚,你就会恍然大悟,哦 ,他是李刚啊,这是因为我们吧类实例化了。
__init__方法用来创建对象和封装内容
每一个方法中的self变量都是Python中默认添加的,用来传递对象的。当我们创建了一个obj对象的时候,会自动的调用类中的__init__方法,然后把obj当做参数传递给self。
# 通过类名加括号去创建一个对象,并用对象去调用方法class Foo:def __init__(self):
self.Name = "hu"def f1(self):print("f1")def f2(self):print("f1")
obj = Foo()
obj.f1()创建对象的图示:都在内存中,创建一个对象的时候,默认的会去执行类中的__init__方法,通过init方法来产生右边的对象。

(3). 三大特性
在面向对象的语言中,一般都具有以下三种特性,封装,继承和多态。也正是因为这样,才构成了一个庞大的面向对象的系统,以至于你可以通过它来表述任何事物。千变万化。
f35d6e602fd7d0f0edfa6f7d103c1b57. 封装
封装就是把一系列相同的功能封装到对象中,从而简化类的方法。在介绍封装之前,我们先来比较一下封装和不封装的区别。
由下面的例子我们就可以看出来,封装其实就是把一些重复的量统一的在一个地方进行定义,然后在利用。


# 没有封装数据class Person:def chifan(self, name, age, gender):print(name, "吃饭")def shuijiao(self, name, age, gender):print(name, "睡觉")def dadoudou(self, name, age, gender):print(name,"打豆豆")


class Person:def __init__(self, name, age, gender): self.Name = name self.Age = age self.Gender = genderdef chifan(self):print(self.Name,"吃饭")def shujiao(self):print(self.Name,"睡觉")def dadoudou(self):print(self.Name,"打豆豆")
使用场景:
a. 当同一类型的方法具有多个模板的时候,直接封装成对象即可
b. 把类当做模板,创建多个对象(对象内封装的数不一样)
例:定义了一个类Person,用__init__去封装了三个参数,以供下面的两个方法来调用,通过pickle模块来存档。
import pickleclass Person:def __init__(self, name, age, weight):
self.Name = name
self.Age = age
self.Weight = weightdef chi(self):
self.Weight += 2def jianshen(self):
self.Weight -= 1ret = pickle.load(open('youxi', 'rb'))if ret:print(ret.Weight)
obj1 = Person(ret.Name, ret.Age, ret.Weight)else:
obj1 = Person('xiaoming', 12, 200)
obj1.chi()
obj1.chi()
obj1.chi()
obj1.jianshen()
pickle.dump(obj1, open('youxi', 'wb'))2cc198a1d5eb0d3eb508d858c9f5cbdb. 继承
我们都听说过子承父业,其实继承就是这个意思,当我们定义了几个类之后,发现这几个类都有一些共同的属性和方法,这个时候我们就可以把这几个共同的属性和方法定义成一个类来当做这几个类的父亲,然后这几个类就可以继承父亲的属性和方法来当做自己的方法。如下面这个例子,定义了三个类,一个父类,一个儿子,一个女儿,父类的方法有吃和喝,儿子的方法是票,女儿的方法是赌,当儿子继承了父亲,就会把父亲的方法继承下来,自然也就会了吃和喝,女儿也一样。


class Parent: def chi(self): print("吃") def he(self): print("喝")class son(Parent):def piao(self):print("票")
class nver(Parent):def du(self):print("赌")
obj = son()
obj.chi()
obj.he()
obj.piao()
obj1 = nver()
obj1.chi()
obj1.he()
obj1.du()继承的规则
1. 子类会默认的继承父类的所有方法
2. 如果子类和父类有同样的方法,会优先的去用子类的方法
3. Python中可以继承多个类(这个是Python的特点, C#和java都不具备)
Python中继承多个类的顺序规则
因为Python中可以多继承,因此当子继承父类的时候,它的规则一般是先执行左边的,后执行右边的,当有嵌套的时候,每次还要重新回到子类中去递归查找。如下面的例子
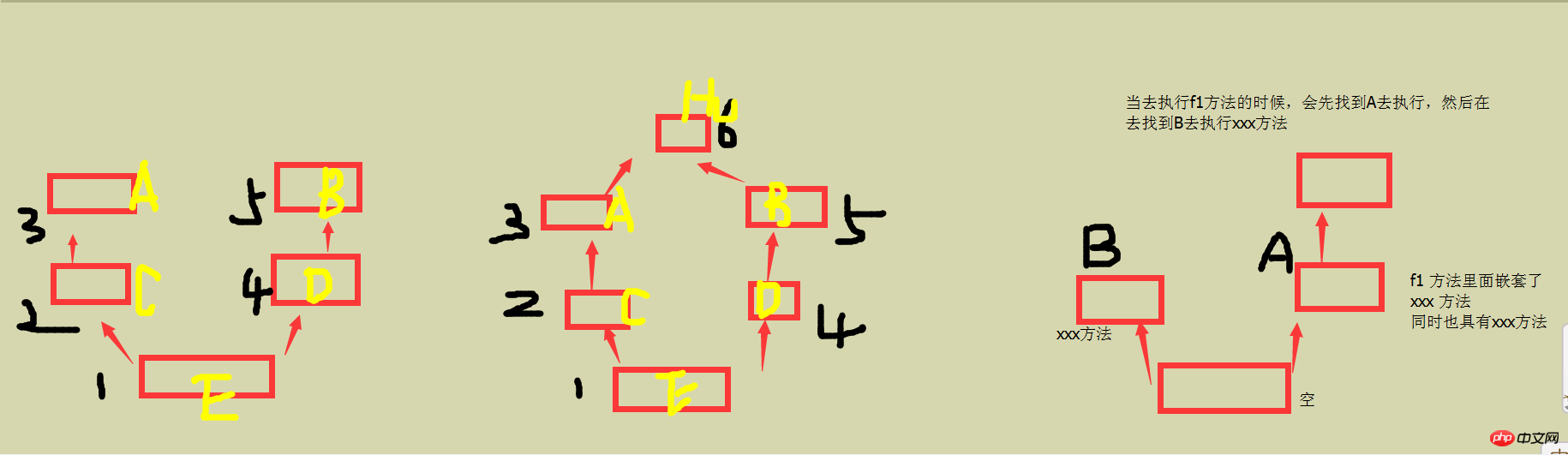
例:当子类中的方法没有的时候就会依次的向上进行查找


# 创建了几个类,继承关系如上图中的一class A:def f1(self):print("A")class B:def f1(self):print("B")class C(A):def f1(self):print("C")class D(B):def f1(self):print("D")class E(C, D):def f1(self):print("E")
obj = E()
obj.f1()

class Hu:def f1(self):print("Hu")class A(Hu):def f1(self):print("A")class B(Hu):def f1(self):print("B")class C(A):def f1(self):print("C")class D(B):def f1(self):print("D")class E(C, D):def f1(self):print("E")
obj = E()
obj.f1()5bdf4c78156c7953567bb5a0aef2fc53. 多态
因为在Python传参的时候本身就没有类型的约束,因此它本身就是多态的,我们可以把任意的数据传进去。
(4). 成员
方法: 静态方法(无需使用对象封装的内容@staticmethod,直接用类进行调用),普通方法(使用对象进行封装),类方法
字段: 静态字段(每一个对象都会有一份),普通字段(使用对象中进行封装的)
特性: 只有一种,将方法伪造成字段
调用成员的方式:
1. 如果没有self, 就用类进行调用
2. 如果有self, 就用对象进行调用
3. 异常处理
在程序执行的过程中,会遇到一些未知的错误,但是我们总是希望把这些错误的以我们能控的方式返回给用户,这是就用到了异常处理。
异常处理的格式:
# 当try后面的语句发生错误之后,就会触发后面的语句,返回一个我们可以控制的错误信息a = input("输入一个数:")try:
a = int(a)except Exception as e:print("出错了....")
以上是Python中物件導向的實例教程的詳細內容。更多資訊請關注PHP中文網其他相關文章!