
MySQL分頁優化的測試案例

- PHP中文网原創
- 2017-06-20 15:27:551446瀏覽
最近無意間看到一個MySQL分頁優化的測試案例,並沒有非常具體地說明測試場景的情況下,給出了一種經典的方案,
因為現實中很多情況都不是固定不變的,能總結出來通用性的做法或者說是規律,是要考慮非常多的場景的,
同時,面對能夠達到優化的方式要追究其原因,同樣的做法,換了個場景,達不到優化效果的,還要追究其原因。
個人對此場景在不用情況表示懷疑,然後自己測試了一把,果然發現一些問題,同時也證實了一些預期的想法。
本文就MySQL分頁優化,從最簡單的情況出發,來做一個簡單的分析。
另:本文測試環境是最最低配置的雲端伺服器,相對來說伺服器硬體環境有限,不過對於不同的語句(寫法)應該是「平等的」
MySQL經典的分頁「最佳化」做法
MySQL分頁優化中,有一種經典的問題,在查詢越「靠後」的資料越慢(取決於表上的索引類型,對於B樹結構的索引,SQL Server中也是一樣)
select * from t order by id limit m,n。
也即隨著M的增大,查詢同樣多的數據,會越來越慢
面對這一問題,於是就產生了一種經典的做法,類似於(或者變種)如下的寫法
就是先把分頁範圍內的id單獨找出來,然後再跟基表做關聯,最後查詢出來所需要的資料
select * from t
inner join ( select id from t order by id limit m,n)t1 on t1.id = t.id
這種做法是不是總是生效的,或者說是在什麼情況下後者才能到達到優化的目的?有沒有做了改寫之後無效甚至變慢的狀況?
同時,絕大多數查詢都是有篩選條件的,
如果有篩選條件的情況,
sql語句就變成了select * from t where *** order by id limit m,n
如果如法炮製,改寫成類似
select * from t
inner join (select id from t where *** order by id limit m,n )t1 on t1.id = t.id
在這種情況下,改寫後的sql語句還能達到最佳化的目的嗎?
測試環境建構
測試資料較簡單,透過儲存程序循環寫入測試數據,測試表的InnoDB引擎表。
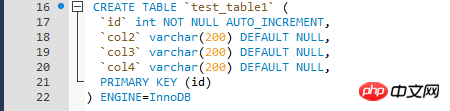
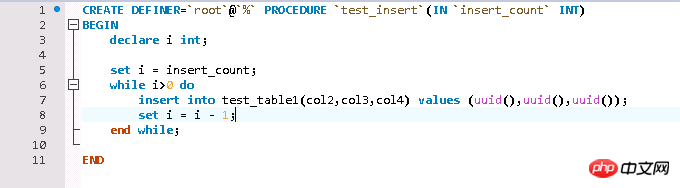
這裡要注意的是日誌寫入模式一定要修改成innodb_flush_log_at_trx_commit = 2,否則預設情況下,500w數據,估計一天都寫不完,這跟日誌寫入模式有關,就不多說了,

#
分頁查詢優化的緣由
首先還是先看一下這個經典的問題,分頁的時候,越「靠後」查詢相應越慢的情況
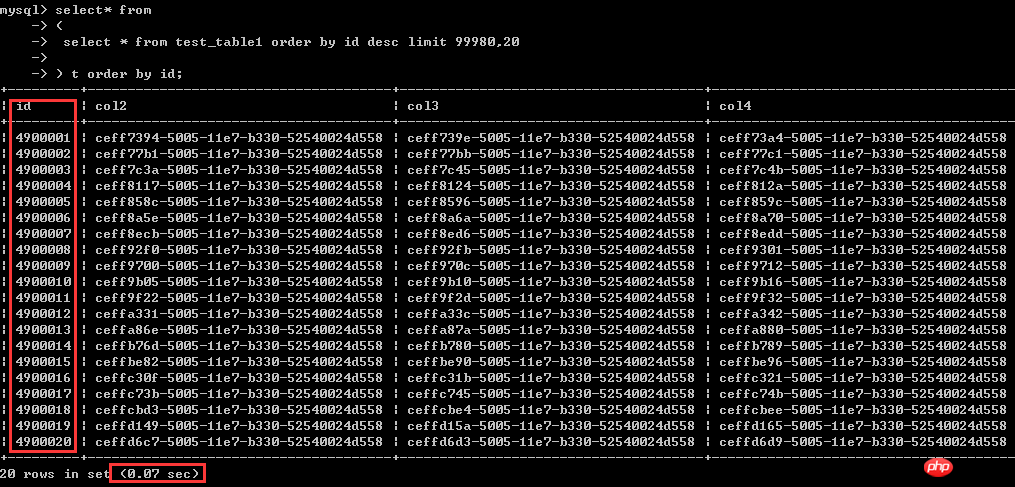
測試一:查詢第1-20行的數據,0.01秒
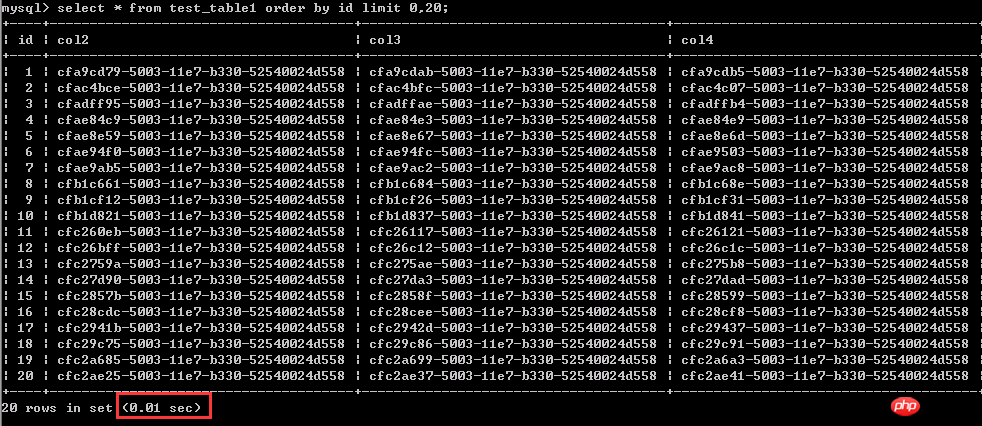
同樣是查詢20行數據,查詢相對「靠後」的數據,例如這裡的從4900001-4900020行數據的情況,用時1.97秒。

從中可以看到,查詢條件不變的情況下,越往後查詢,查詢效率越低,可以簡單理解成:同樣搜尋20行數據,越是靠後的數據,查詢代價越大。
至於為什麼後一種效率較低,後面會慢慢分析。
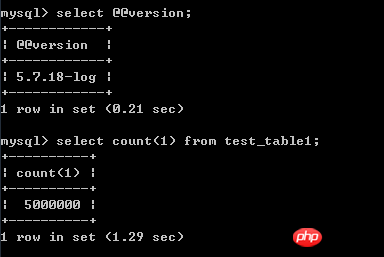
測試環境是centos 7 ,mysql 5.7,測試表的資料是500W
#
#
重現經典分頁“最佳化”,當沒有篩選條件,排序列為聚集索引的時候,並不會有所改善
select * from t order by id limit m,n。
select * from t###inner join (select id from t order by id limit m,n)t1 on t1.id = t.id###### ###### 第一種寫法:###select * from test_table1 order by id asc limit 4900000,20;測試結果見截圖,執行時間為8.31秒
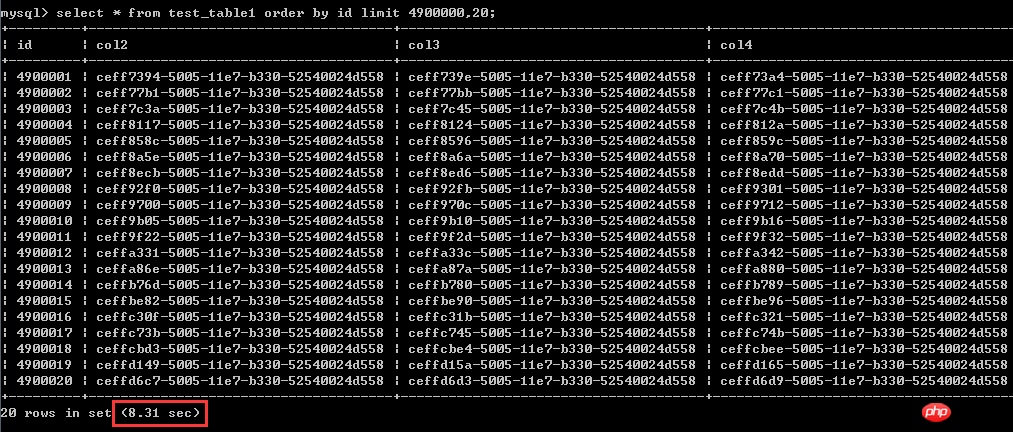
第二個版本改寫後的寫法:
select t1.* from test_table1 t1
inner join (select id from test_table1 order by id limit 4900000,20)t2 on t1.id = t2.id;執行執行時間為8.43秒
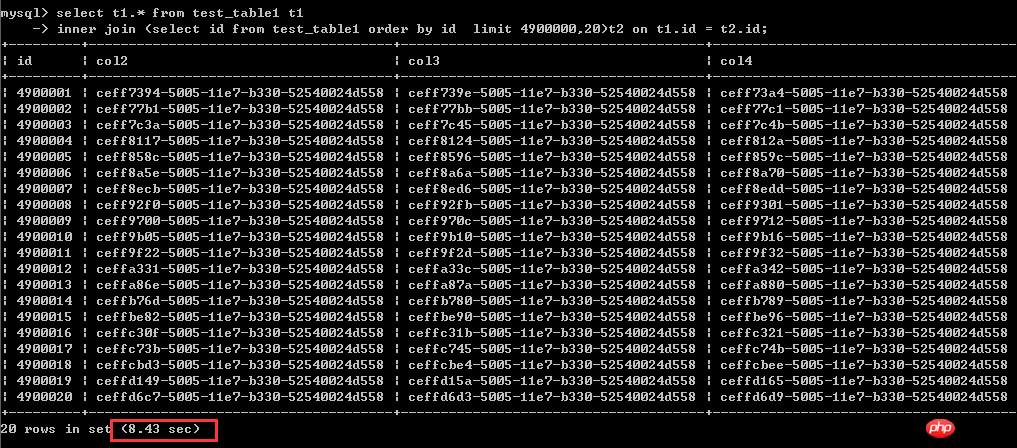
這裡很清楚,透過經典的改寫方法改寫之後,性能能毫無提升,甚至還有一點點變慢了,
實際測試上表現為兩者在性能上並沒有明顯的線性差異,這兩者樓主是做了多次測試的。
我個人看到類似結論非要測一下不可的,這個東西不能靠蒙,或靠運氣什麼的,能提高效率是為什麼,不能提高又是為什麼。
那麼為什麼改寫之後的寫法沒有像傳說中的那種提升性能?
是什麼導致目前這個改寫沒有到達提升效能的目的?
後者能夠提升效能的原理是什麼?
先看一下測試表的表結構,排序列上是有索引,這一點是沒有問題的,關鍵是這個排序列上的索引是主鍵(聚集索引)。
為什麼排序列上是聚集索引的時候,相對「優化」改寫之後的sql並不能達到「最佳化」的目的?
在排序列為聚集索引列的情況下,兩者都是順序掃描表來實現查詢符合條件的資料的
後者雖然是先驅動子查詢,然後再用子查詢的結果驅動主表,
但是子查詢並沒有改變「順序掃描表來實現查詢符合條件的資料的」做法,當前情況下,甚至改寫後的做法顯得畫蛇添足
參考如下兩者執行計劃,第一個截圖的執行計劃的一行,與改寫後的sql的執行計劃的第三行(id =2 的那一行),基本上一樣。


#
當沒有篩選條件,排序列為聚集索引時候的分頁查詢,所謂的分頁查詢優化只不過是畫蛇添足
目前來看,查詢上述數據,兩種方式都非常慢,那如果要查詢上述的數據,該如何做?
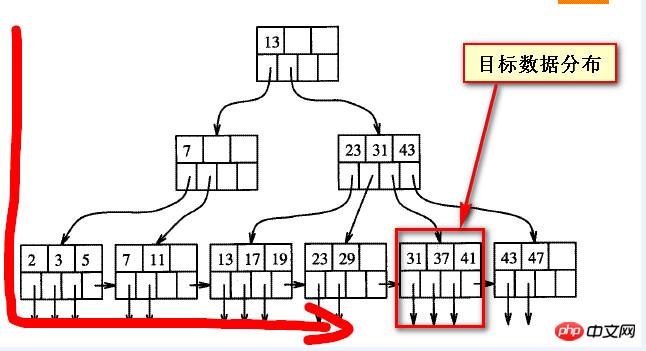
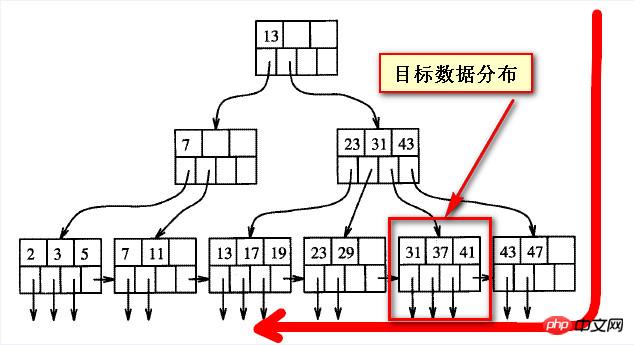
還是要看為什麼慢,首先要理解B數的平衡性結構,在我自己粗略的理解來看,如下圖,
當查詢的數據「靠後」的時候,實際上是偏離在B樹索引的一個方向,如下兩個截圖所示的目標數據
其實平衡樹上的數據,沒有所謂的“靠前”與“靠後”,“靠前”與“靠後”都是相對於對方來說的,或者說是從掃描的方向上來看的
從一個方向上看“靠後的”數據,從一個方向看就是“靠前的”,前後不是絕對的。
如下兩個截圖是B樹索引結構的粗略表現形式,假如目標資料的位置固定的情況下,所謂的「靠後」是相對與從左向右來說的;
如果從右向左看,之前所謂靠後的資料其實是「靠前」的。
只要數據是靠前的,要高效低找到這部分數據,還是可以的。 mysql中應該也有類似sqlserver中的正向(forwarded)和反向掃描(backward)的做法。
如果對於靠後的數據,採用反向掃描,應該就可以很快找到這個部分數據,然後對找到的數據在再次排序(asc),結果應該是一樣的,
首先來看效果:結果跟上面的查詢一模一樣,這裡僅耗時0.07秒,之前的兩種寫法均超過了8秒,效率有上百倍的差距。
至於這個是為什麼,我想根據上面的闡述,自己應該能夠體會的到,這裡附上這個sql。
如果經常查詢所謂的靠後的數據,比如說Id較大的數據,或者說是時間維度上較新的數據,可以採用倒敘掃描索引的方式來實現高效分頁查詢
# (這裡請算好數據所在的分頁,同樣的數據,正序和倒序其起始「頁碼」是不同的)
select* from(select * from test_table1 order by id desc limit 99980,20) t order by id;
當沒有篩選條件,排序列為非聚集索引的時候,會有所改善
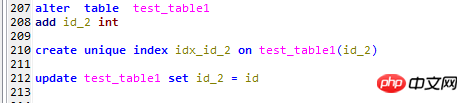
這裡對測試表test_table1做出如下改變
1,增加一個id_2列,
2,該欄位上建立一個唯一索引,
3,該欄位以對應的主鍵Id填入
##
上面的測試是按照主鍵索引(聚集索引)來排序的,現在來按照非聚集索引排序,也也就是新增的這個列id_2來排序,測試一開始提到的兩種分頁方法。
首先來看第一種寫法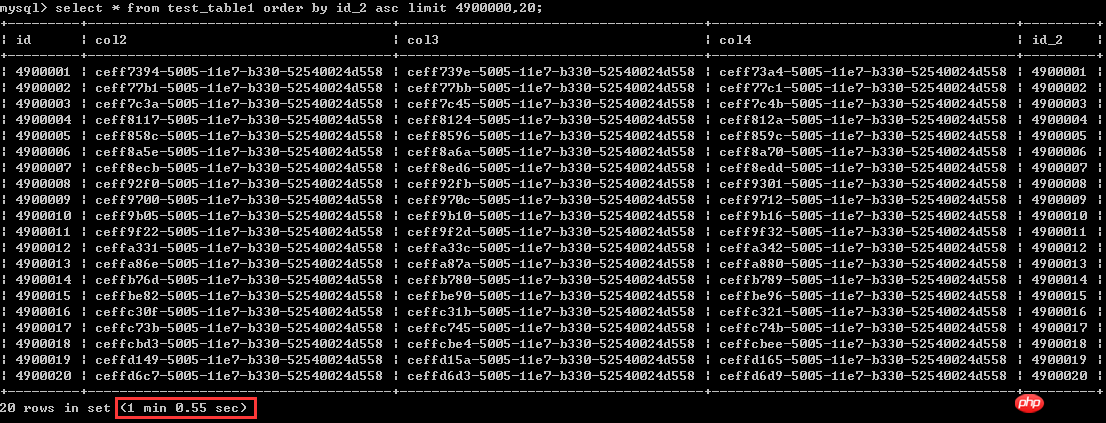
暫且認其為60秒
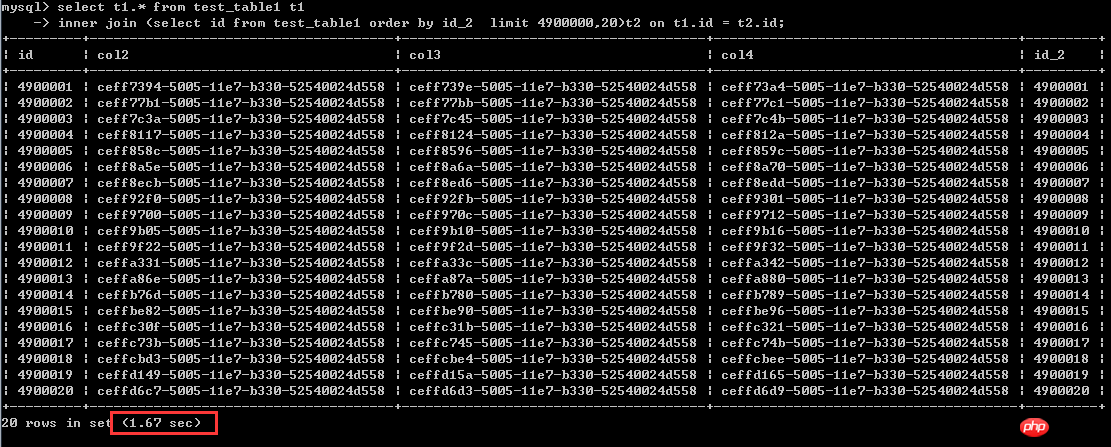 select t1.* from test_table1 t1
select t1.* from test_table1 t1
執行時間1.67秒
 從這種情況來看,也就是說排序列為非聚集索引列的時候,後一種寫法確實能大幅提升效率。差不多有40倍的提升。
從這種情況來看,也就是說排序列為非聚集索引列的時候,後一種寫法確實能大幅提升效率。差不多有40倍的提升。
首先來看第一種寫法的執行計劃,可以簡單理解為這個sql的執行時做全表掃描之後,然後重新按照id_2排序,最後取最前20條資料。
首先全表掃描就是一個非常耗時的過程,排序也是一個非常大的代價,因此表現為性能非常的低下。
 再來看後者的執行計劃,他是首先子子查詢中,按照id_2上的索引順序掃描,然後用符合條件的主鍵Id去表中查詢資料
再來看後者的執行計劃,他是首先子子查詢中,按照id_2上的索引順序掃描,然後用符合條件的主鍵Id去表中查詢資料
如果了解sqlserver執行計劃的情況下,後者與前者相比,應該還有避免了頻繁的回表( sqlserver中叫做key lookup或書籤查找的過程
可以認為是子查詢驅動外層表查詢符合條件的20條的資料的過程是一個批量的,一次性的。
select* from(select * from test_table1 order by id desc limit 99980,20) t order by id;###
另外一個,想提到的問題就是,如果經常性分頁查詢,還要按照某種順序,那麼為什麼不在這個列上建立一個聚集索引。
例如語句自增Id的,或是時間+其他欄位確保唯一性的,mysql會在主鍵上自動建立聚集索引。
接著有了聚集索引,「靠前」與「靠後」僅僅是一個相對的邏輯上的概念了,如果多數時候是想得到「靠後」或較新的數據,就可以採用上述寫法,
當存在篩選條件的情況下,分頁查詢的最佳化
這一部分想了想,情況太複雜了,很難概括出來一種非常具代表性的案例,因此就不過度做測試了。
select * from t where *** order by id limit m,n
1,例如刷選條件本身就很高效,一過濾出來僅剩下很少一部分數據,那麼改不改寫sql意義也不大,因為篩選條件本身就可以做到很有效率的篩選
2,例如刷選條件本身作用不大(過濾後資料量依然龐大),這種情況其實又回到了不存在篩選條件的情況,還有取決於如何排序,正序還是倒序等等
3,例如篩選條件本身作用不大(過濾後資料量依然巨大),要考慮的一個很實際的問題是資料分佈,
資料的分佈也會影響的sql的執行效率(sqlserver中的經歷,mysql應該差別不大)
4,本身查詢比較複雜的情況下,很難說用某種方式就可以達到高效的目的
情況越複雜,越是難以總結出來一種通用性的規律或者說是方法,一切都要以具體情況來看待,很難下一個定論。
這裡對於查詢加上篩選條件的情況,就不做一一分析了,不過可以肯定的是,脫離了實際場景,肯定沒有一個固化的方案。
另外,對於查詢當前頁數據時候,利用上一頁查詢的最大值做篩選條件,也可以很快滴找到當前頁的數據,這樣當然沒有問題,但這屬於另外一個做法,不在本文討論之列。
總結
分頁查詢,越後越慢的情況,實則對於B樹索引來說,靠前與靠後是一個邏輯上相對的概念,性能上的差異,是基於B樹索引結構以及掃描方式有關的.
如果加上篩選條件,情況將變得更加複雜,這個問題在SQL Server中的原理也是一樣的,本來也在SQL Server中做了測試的,這裡就不重複了。
當前這種情況,排序列不一定,查詢條件不一定,數據分佈不一定,就很難用一種特定的方法來實現“優化”,弄不好還起到畫蛇添足的副作用。
因此在做分頁優化的時候,一定要根據具體的場景來做分析,方法也不一定只有一種,脫離實際場景的結論,都是扯犢子。
只有弄清楚這個問題的來龍去脈,才能游刃有餘。
因此個人對於數據“優化”的結論,一定是具體問題具體分析,是很忌諱總結出來一套規則(規則1,2,3,4,5)給人“套用”,鑑於本人也很菜,就更不敢總結出來一些教條了。
##
以上是MySQL分頁優化的測試案例的詳細內容。更多資訊請關注PHP中文網其他相關文章!