
JAVA WEB 筆記--中文亂碼
- 巴扎黑原創
- 2017-06-26 11:11:011587瀏覽
JAVA WEB 亂碼問題解析
亂碼原因
在Java Web開發過程中,經常遇到亂碼的問題,造成亂碼的原因,概括起來就是對字元編碼和解碼的方式不符。
既然亂碼的原因是字元編碼與解碼的方式不匹配,那麼為什麼我們一定要對字元進行編碼,不編碼可不可以呢?這是因為在電腦中儲存資料的基本單位是1個位元組,即8個bit,那麼它所能表達的字元的最多有28=256個,而在我們現實社會中存在的字元(漢字、英文、其他文字等等)遠遠多餘這個數字,所以為了解決字元與位元組的矛盾,將字元進行編碼處理才能儲存在電腦中。
編碼與解碼
在電腦中常見的編碼方式有ASCII、ISO-8859-1、GB2312、UTF-16、UTF-8幾種編碼方式。
ASCII碼是使用一個位元組的低7位元來表示的,所以共能表達的字元最多有27=128個。 ISO-8859-1是ISO組織基於ASCII碼的基礎上擴展來的,相容於ASCII碼,涵蓋了大多數西歐字元。 ISO8859-1使用一個位元組來表示,所以其能表達的字元最多有256個。 GB2312,採用了雙位元組編碼,編碼範圍是A1-F7,其中A1-A9是符號區,B0-F7是漢字區,包含6763個漢字。 GBK是為了擴展GB2312編碼,並加入了更多的漢字,總是能表達的漢字有21003個。 UTF-16是採用定長的編碼方式,無論什麼字元都採用2個位元組進行表示,這也是JAVA記憶體中字元的儲存格式。與UTF-16相反,UTF-8採用了變長的編碼方式,不同的類型的字元可以由1-6個位元組組成。
下面以字串「日向雛田」來看一下在電腦中不同編碼方式的編碼,如下圖。

#亂碼分析與解決
對於JAVA WEB中亂碼問題,我們分割位元請求導致的亂碼和回應導致的亂碼,對於不同的亂碼我們要分析其亂碼原因,即字元編碼的方式是什麼,解碼的方式是什麼。
對於由於請求導致的亂碼我們要分析Http請求,查看其編碼方式,由於HTTP請求分為Get請求和Post請求,我們接下來分別對其進行討論。
對於Get請求,是瀏覽器預設的請求方式,和表單提交時設定為「Get」時的提交方式。我們透過火狐瀏覽器我們查看其具體內容如下:
網址列為:
請求內容為:

透過上面請求我們可以看到,GET請求中查詢字串放在了請求行中存放,發送到WEB伺服器中,透過「日向雛田」編碼我們可以看到,瀏覽器對該字串採用的編碼方式為「UTF-8」。
查看伺服器代碼我們可以看到亂碼(如下圖),這是因為伺服器在接受到該字串編碼後的資料預設透過ISO-8859-1的方式進行解碼,所以造成了編碼與解碼的方式不統一。

# 解決方案如下:
先取得字串user解碼前的編碼,然後指定該字串的編碼方式,如下圖:

# 解決方案示意圖如下:

在Java web開發過程中,我們在超連結中傳遞參數,經常遇到中文的情況。對此情況下,我們需要對中文進行編碼,我們可以設定為UTF-8,解碼方案同上。
<a href="${pageContext.request.contextPath}/Test?user=<%=URLEncoder.encode("日向雏田", "UTF-8")%>">点击</a>對於Post要求,是表單提交時設定為「Post」時的提交方式。我們透過火狐瀏覽器我們查看其具體內容如下:
網址列及其頁面為:

# post請求內容為:

由上圖我們可以知道,在post請求中,將請求內容直接放在請求體中傳送給web伺服器,編碼方式為「utf-8」。
在此回應Servlet中,doPost方法體如下:
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
String user=request.getParameter("user");
System.out.println(user);//输出为æ¥åéç°
}#
此處亂碼的原因依然時在代碼getParameter(「user」)時,web伺服器採用預設的解碼方案「ISO-8859-1」進行解碼,導致了編碼與解碼方案的不同意,解決方案可以採用get請求亂碼的解決方案,但是還有一種更為簡單的解決方案,直接指定方法體的編碼/解碼方案為“utf-8”。方案如下。
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setCharacterEncoding("utf-8"); //设置请求体的编码/解码方案为UTF-8 但是请求行的编码解码方案不会受影响
String user=request.getParameter("user");
System.out.println(user); //输出为日向雏田
}以上對於請求導致的亂碼狀況分析完畢。
在影響導致的亂碼中,web伺服器會將回應的內容寫入回應體中,傳回給客戶端並不會涉及狀態列中的情況。如向瀏覽器輸出」HelloWorld「其回應如下圖所說。
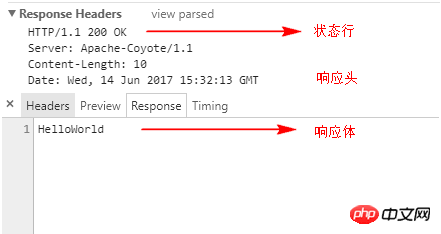
# 對於回應導致的亂碼我們必須涉及四個方法,如下:
response.setHeader("Content-Type", "text/html;cahrset=utf-8");//设置发送到客户端的响应的内容类型和响应内容的编码类型(响应体的编码类型)
response.setCharacterEncoding("utf-8");//设置响应体的编码类型
response.getWriter(); //获取响应的输出字符流
response.getOutputStream(); //获取响应的输出字节流
#對於設定回應體的編碼類型,如response.setHeader("Content-Type", "text/html;cahrset=utf-8");與response.setCharacterEncoding("utf-8");這2個方法設定的編碼方式等效,若沒有設定響應體的編碼方式,則預設為ISO-8859-1,且後面設定響應體字元的編碼方式會迭代前面的設定編碼的方式。這兩個方法都在getWriter方法前有效,在getWriter方法設定編碼的方法會無效。
但是這2個方法卻有點不同,即setHeader("Content-Type", "text/html;cahrset=utf-8")這個方法瀏覽器會自動採用該響應體的編碼方式進行解碼,而setCharacterEncoding()該方法並不是所有的瀏覽器都會採用該方法的編碼方式進行解碼,下面對這2個方法進行測試,效果如下:
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setHeader("Content-Type", "text/html;charset=utf-8");
response.getWriter().write("日向雏田");
} 
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setCharacterEncoding("utf-8");
response.getWriter().write("日向雏田");
} 
从上面可以看到第一个方法对于浏览器来说,支持的较好,提倡采用第一种方法设置响应体的字符编码方式。
对于获取响应字符输出流的方法,如果在此之前没有设置响应体的编码方式,那么默认为null,即ISO-8859-1方式进行编码。而且后面设置的编码方式会覆盖前面设置的编码方式。在getWriter()方法之后设置的编码无效。
对于获取响应输出字节流,我们在输出字符串时,我们需要设置字符串的编码方式如果没有那么默认ISO-8859-1。
对于前面2个输出流,由于只有一个输出缓存,所以这两个方法互斥。
以上,为了保证响应无乱码,需要保证字符编码和解码方法的统一,方案如下:
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
// 方案1
// response.setHeader("Content-Type", "text/html;charset=utf-8");
// response.getWriter().write("日向雏田");
// 方案2
// response.getOutputStream().write("日向雏田".getBytes("UTF-8"));
// 方案1,2互斥
}
此外在Java web开发过程中,我们还会遇到当进行文件下载时,中文文件名导致的问题,如下图所示:
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
String realPath=this.getServletContext().getRealPath("/src/日向雏田.jpg");
String fileName=realPath.substring(realPath.lastIndexOf('\\')+1);
response.setHeader("content-disposition", "attachment;filename="+fileName);
InputStream is=new FileInputStream(new File(realPath));
OutputStream os=response.getOutputStream();
byte[] buff=new byte[1024];
int len=0;
while((len=is.read(buff))>0){
os.write(buff, 0, len);
}
os.close();
is.close();
}采用火狐浏览器进行测试,查看页面效果,及其响应结果如下:


经过查看响应头分析,下载文件名存放在响应头中,且对于中文文字没有采用UTF-8、UTF-16、GBK等等能识别中文的编码,那么对于中文文件名导致采用哪种编码方式呢?查看REF 7578得知,在此处采用ASCII编码,但是REF规定,如果不可避免的要使用非ASCII码的字符,程序员应该均匀的使用UTF-8,来最小化交互操作的问题。
所以,解决方案就是把文件名编码成UTF-8,传递给响应头,浏览器(部分)默认对该文件名进行UTF-8解码处理。
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
String realPath=this.getServletContext().getRealPath("/src/日向雏田.jpg");
String fileName=realPath.substring(realPath.lastIndexOf('\\')+1);
String utf_8Name=URLEncoder.encode(fileName,"utf-8");//解决方案
response.setHeader("content-disposition", "attachment;filename="+utf_8Name);
InputStream is=new FileInputStream(new File(realPath));
OutputStream os=response.getOutputStream();
byte[] buff=new byte[1024];
int len=0;
while((len=is.read(buff))>0){
os.write(buff, 0, len);
}
os.close();
is.close();
}效果如下:其中火狐浏览器并没有对其解码

以上是JAVA WEB 筆記--中文亂碼的詳細內容。更多資訊請關注PHP中文網其他相關文章!