
Windows下怎麼安裝tesseract-ocr 4.00並且設定?

- 零下一度原創
- 2017-06-23 14:09:145051瀏覽
最近要做文字識別,不讓直接用別人的接口,所以只能嘗試去用開源的類別庫。 tesseract-ocr是惠普公司開源的文字辨識項目,透過它可以快速建構圖文辨識系統,幫助我們開發出能辨識圖片的ocr系統。因為Windows環境開發,我也必須在windows環境安裝系統。
第一步:下載安裝包
根據,我找到非官方的安裝包,好像我只看到64位元的安裝包http://digi.bib.uni-mannheim .de/tesseract/tesseract-ocr-setup-4.00.00dev.exe,下載後直接安裝即可,但是要記得你的安裝目錄,我們等會配置環境變數要用。
如果不是做英文的圖文識別,還需要下載其他語言的識別套件。
簡體字辨識套件:
繁體字辨識套件:
第二步:安裝
直接執行下載好的tesseract -ocr-setup-4.00.00dev.exe,下一步、下一步安裝。
第三步:設定環境變數
注意:我的系統是win7,其他系統應該差不多,跟設定java變數一樣
複製你的安裝位址,我的是安裝在C:\Program Files (x86)\Tesseract-OCR,介面如下:
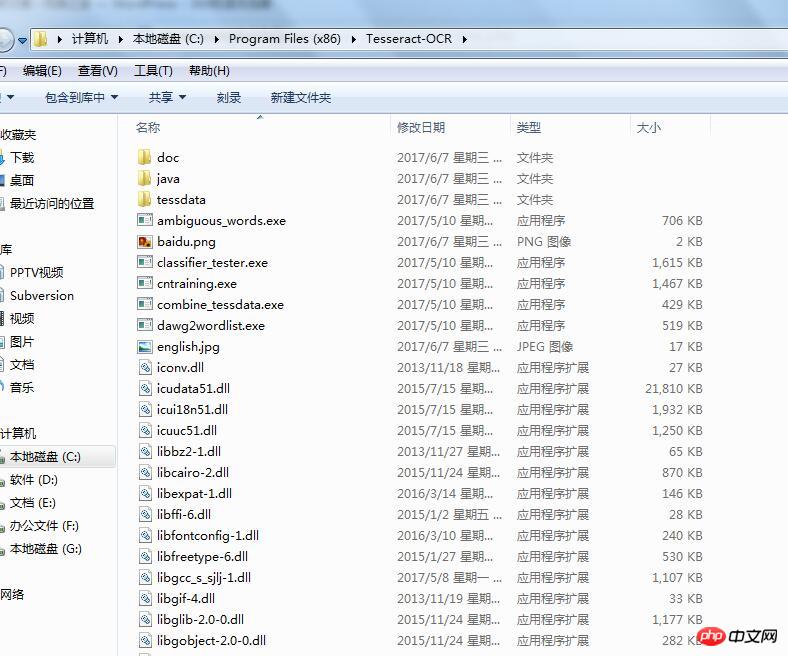
複製安裝路徑「C:\Program Files (x86)\Tesseract- OCR”,進入“控制面板\系統和安全性\系統”,點擊
“系統保護”

#進入以下介面:
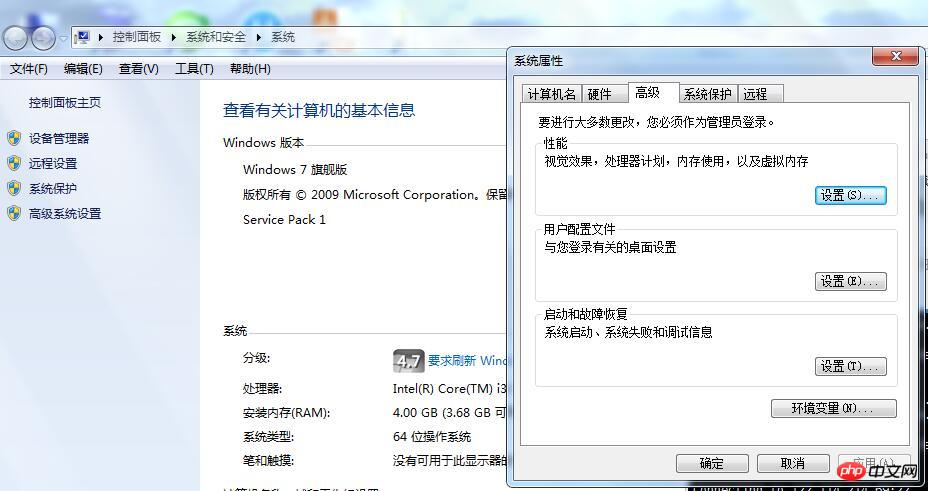
點擊環境變量,進入配置以下介面:
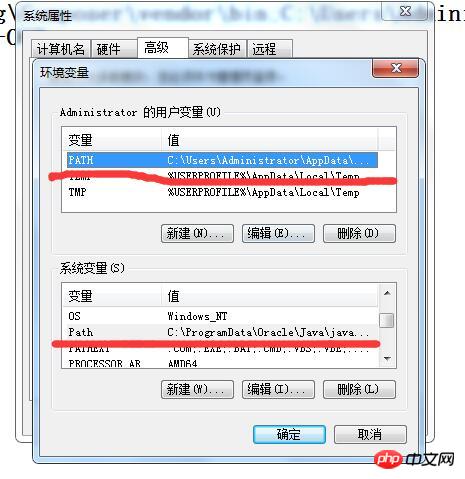
#把剛才的安裝路徑「C:\Program Files (x86)\ Tesseract-OCR」加入紅線劃的PATH和Path,注意,加入時候開頭用「;」跟之前的變數隔開,結尾以「;」結尾。以下是我的設定資訊樣本:
C:\Users\Administrator\AppData\Roaming\Composer\vendor\bin;C:\Users\Administrator\AppData\Roaming\npm;C:\ Program Files (x86)\Tesseract-OCR;
配置了點選儲存。
開啟指令終端,輸入:tesseract -v,可以看到版本資訊

如果出現報錯,估計是環境變量沒配置好。
到這裡,我們就算安裝完成了,但是,我們的系統還是無法識別中文的,我們要去下載簡體漢字、繁體漢字語言包(上文給了地址了),下載好之後放到安裝目錄的tessconfigs目錄下即可。
補充:因為沒有配置全域變量,無法跨碟執行資料轉換,這裡我們在環境變量那增加一個設定資訊
系統變數—->新建:

增加一個TESSDATA_PREFIX變數名,變數值還是我的安裝路徑C:\Program Files (x86)\Tesseract-OCR;
以上是Windows下怎麼安裝tesseract-ocr 4.00並且設定?的詳細內容。更多資訊請關注PHP中文網其他相關文章!