
詳解Python中的字元編碼

- 零下一度原創
- 2017-06-16 10:49:551366瀏覽
下面小編就為大家帶來一篇老生常談Python基礎之字符編碼。小編覺得蠻不錯的,現在就分享給大家,也給大家做個參考。一起跟著小編過來看看吧
前言
字元編碼非常容易出問題,我們要牢記幾句話:
1.用什麼編碼保存的,就要用什麼編碼打開
2.程式的執行,是先將檔案讀入記憶體中
3.unicode是父編碼,只能encode解碼成其他編碼格式
utf-8,GBK這些是子8編碼,只能decode編碼成Unicode
一、什麼是字元編碼
我們知道,電腦只能辨識二進位,我們平常寫的程式碼都需要轉成二進位才能被電腦辨識。所以,我們寫的字元怎麼轉換成二進位呢,這個過程實際上就是透過一個標準來讓我們寫的字元與特定數字一一對應,這個標準就稱為字元編碼。
字元------(字元編碼)------->數字
#二、字元編碼發展歷程
1.ASCII碼
電腦起源於美國,字元編碼也起源於美國。但是美國人民使用的文字只有26個字母,再加上些特殊符號就搞定了。不像我們中國,小學生就要認識幾千個漢字。所以美國人民就使用了ASCII碼(美國資訊交換標準碼)作為字符編碼,一個Bytes代表一個字符,1Bytes=8bit,可以有2的8次方即256中不同的變化,但最初只用了前7位,即127個字符,已經足夠美國人民使用了(當然也出於成本的考慮)。後來將拉丁文編入第8位,至此,ASCII碼就被佔滿了,英語國家和拉丁國家可以愉快的玩耍了。
2.GBK
別看咱們中國暫時科技比不上美帝國,但是咱們有一顆積極向上的心啊,於是,在1980年,國家標準總局發布了中文使用的字符編碼-->GBK,使用兩個字節表示一個漢字,這樣就有2的16次方即65536種組合,已經足夠漢字使用了。
同時,其他國家也分別發布了自己國家的字元編碼標準,如日本的shift_JIS,韓國的Euc-kr等等
3.Unicode
據說,字符編碼鼎盛時期有數百種,且彼此間互相不支持,看來各國人民都很有骨氣,但是這太不利於世界的互通了,於是Unicode應運而生。 1994年,國際標準化組織發布了號稱萬國碼的Unicode,用兩個字節表示一個字符,有65536種組合,已經能把全世界絕大多數語言包括了。
4.utf-8
Unicode雖然好,但有一個問題,本來用一個字節就能表示的英文,現在要用兩個字節,儲存空間平白多出一倍,這顯然是不完美的,所以又產生了utf-8,對英文字元只用1個字節,對中文字元用3個位元組來表示。
5.Unicode所有字元都是兩個字節,簡單粗暴,字元轉換成數字的速度快,但是佔用儲存空間大
utf-8對不同的字元採用不用的長度表示,節省空間,但是轉換效率不如Unicode快
記憶體中使用的字元編碼是Unicode,記憶體就是為了加快速度的,所以寧肯犧牲一點空間,也要保證速度
硬碟和網路傳輸是用utf-8的,因為磁碟I/O或網路I/O延遲要遠大於utf-8的轉換效率,並且在網路傳輸中應該盡可能節省頻寬
三、Python解釋器執行
#第一階段:python解釋器啟動,此時就相當於啟動了一個文字編輯器
第二階段:python解釋器作為文字編輯器,去開啟t.py文件,從硬碟上將t.py的文件內容讀入到記憶體中
第三階段:python解釋器解釋執行剛剛載入到記憶體中t.py的程式碼
其中第二階段,t. py檔案在儲存時有一個字元編碼,在Python解釋器開啟檔案時也要指定一樣的編碼方式(Python2預設的編碼方式是ASCII,Python3預設是utf-8),如果檔案儲存的編碼格式和Python解釋器預設的編碼方式不一樣,就要在文件的開頭寫上#coding: ,來告訴python解釋器不要用自己默認的編碼方式來讀,而是要用頭文件指定的方式來讀文件,這樣才不會出錯。
第三階段:讀取已經載入到記憶體中的程式碼(預設是Unicode),然後執行,執行過程中如果碰到類似定義變數的操作,就會在記憶體中開闢一塊新的記憶體空間。此時注意,新開啟的記憶體空間不一定也是Unicode,使用者可以在定義變數的時候指定編碼方式,定義時開啟的記憶體空間,也只是一塊空間而已,可以存放任意編碼格式的程式碼。以Python3為例

四、編碼解碼
儲存檔案是把記憶體中的檔案儲存到硬碟上
讀取檔案是把硬碟中的檔案讀到記憶體
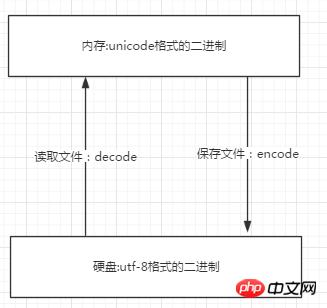
#Unicode是父編碼,utf-8,GBK這些是子編碼,如果子碼想轉換成其他編碼,必須先轉換成父編碼,再由父編碼轉換成其他子編碼
#解碼就是decode,是由子碼轉成父碼Unicode的過程
編碼就是encode,是由Unicode轉換成其他編碼的過程
之前說過,文件讀入內存中,就成了Unicode編碼(當然這是默認情況,也可以根據指令更改),從硬碟讀取檔案的過程就是把硬碟中的utf-8解碼成Unicode
檔案儲存時,就是由記憶體儲存到硬碟的過程,硬碟中是utf-8的編碼方式,需要由Unicode編碼成utf-8
五、Python2和Python3的區別
##1.Python2的預設編碼方式是ASCII,開啟utf-8保存的檔案時會報錯,應該在頭檔上加#coding : utf-8Python2中的str被辨識為Bytes,所以Python2中的str是被編碼後的結果,其實會預設做一件事,就是在str前面加一個u,先轉換成Unicode,在encode成bytesPython2中有兩種字串類型,str和Unicode,str可以透過在前面加個'u'來轉換成Unicode2.python 3 的預設編碼方式是utf-8,可以直接開啟用utf-8儲存的檔案Python3中的str被辨識成UnicodePython3中也有兩個字串型別(bytes和str),但bytes就是bytes,str是unicode六、印到終端機
首先要知道,Windows的終端的預設編碼方式是GBK
終端也是應用程序,是運行在內存中的,所以我們用print()打印的過程,是從內存中到內存中。所以對於unicode,怎麼打印都不會出錯,但是Python2中除了加上'u'的字串外,其他的字串是Bytes,此時終端中是GBK編碼,而Python2中是指定的utf-8或者默認的ascii碼時,在終端機中列印就會出錯。
###這些是我目前的理解,如果我以後意識到錯誤或有表達不清的地方,再來修改。唉,字元編碼是個坑啊###以上是詳解Python中的字元編碼的詳細內容。更多資訊請關注PHP中文網其他相關文章!