
詳解Java中的String類

- Y2J原創
- 2017-05-04 09:48:281971瀏覽
這篇文章主要介紹了Java String類別詳解,本文經多方資料的收集整理和歸納,最終撰寫成文,非常不錯,值得收藏,需要的的朋友參考下
引題
在Java語言的所有資料型別中,String類型是比較特殊的一種類型,同時也是面試的時候常被問到的一個知識點,本文結合Java記憶體分配深度分析關於String的許多令人困惑的問題。以下是本文將要涉及到的一些問題,如果讀者對這些問題都瞭如指掌,則可忽略此文。
1、Java記憶體具體指哪塊記憶體?這塊記憶體區域為什麼要進行劃分?是如何劃分的?劃分之後每塊區域的作用是什麼?如何設定各區域的大小?
2、String類型執行連線作業時,為什麼效率會比StringBuffer或StringBuilder更低? StringBuffer和StringBuilder有什麼關聯和區別?
3、Java中常數是指什麼? String s = "s" 和 String s = new String("s") 有什麼不一樣?
本文經多方資料的收集整理與歸納,最終撰寫成文,如果有錯誤之處,請多多指教!
Java記憶體分配
1、JVM簡介
Java虛擬機器(Java Virtual Machine 簡稱JVM)是執行所有Java程式的抽象計算機,也是Java語言的運作環境,它是Java 最具吸引力的特性之一。 Java虛擬機有自己完善的硬體架構,如處理器、堆疊、暫存器等,也有對應的指令系統。 JVM封鎖了與特定作業系統平台相關的訊息,使得Java程式只需要產生在Java虛擬機器上執行的目標碼(字節碼),就可以在多種平台上不加修改地運作。
一個運作時的Java虛擬機器實例的天職是:負責執行一個java程式。當啟動一個Java程式時,一個虛擬機器實例也就誕生了。當程式關閉退出,這個虛擬機器實例也就隨之消亡。如果在同一台電腦上同時執行三個Java程序,將會得到三個Java虛擬機器實例。每個Java程式都運行於它自己的Java虛擬機器實例中。
如下圖所示,JVM的體系架構包含幾個主要的子系統和記憶體區:
#(GarGarbage Collection
(GarGarbage Collection
#(GarGarbage Collection
(GarGarbage Collection
##)(GarGarbage Collection):負責回收堆記憶體(Heap)中沒有被使用的對象,也就是這些物件已經沒有被引用了。 
# 類別載入子系統(Classloader Sub-System):除了定位和匯入二進位class檔案外,還必須負責驗證被導入類別的正確性,為類別變數分配並初始化內存,以及幫助解析符號引用。
執行引擎
(Execution Engine):負責執行那些包含在被裝載類別的方法中的指令。
程式計數器(Program Count Register):又稱為程式暫存器。 JVM支援多個執行緒同時運行,當每一個新執行緒被建立時,它都會得到它自己的PC暫存器(程式計數器)。如果執行緒正在執行的是一個Java方法(非native),那麼PC暫存器的值將總是指向下一條將被執行的指令,如果方法是 native的,程式計數器暫存器的值不會被定義。 JVM的程式計數器暫存器的寬度足以保證可以持有一個回傳位址或native的指標。
# ##已堆疊(Stack):請呼叫堆疊。 JVM為每個新建立的執行緒都指派一個堆疊。也就是說,對一個Java程式來說,它的運作就是透過對棧的操作來完成的。堆疊以幀為單位保存執行緒的狀態。 JVM對棧只進行兩種操作:以幀為單位的壓棧和出棧操作。我們知道,某個執行緒正在執行的方法稱為此執行緒的當前方法。我們可能不知道,目前方法使用的幀稱為當前幀。當執行緒啟動一個Java方法,JVM就會在執行緒的 Java堆疊裡新壓入一個幀,這個幀自然成為了當前幀。在此方法執行期間,這個幀將用來保存參數、局部變數、中間計算過程和其他資料。從Java的這種分配機制來看,堆疊又可以這樣理解:棧(Stack)是作業系統在建立某個行程時或執行緒(在支援多執行緒的作業系統中是執行緒)為這個執行緒建立的儲存區域,該區域具有先進後出的特性。其相關設定參數:
• -Xss --設定方法堆疊的最大值本機方法堆疊(Native Stack):儲存本地方方法的呼叫狀態。

方法區(Method Area):當虛擬機器載入一個class檔案時,它會從這個class檔案所包含的二進位資料中解析型別訊息,然後把這些型別資訊(包括類別資訊、常數、靜態變數等)放到方法區中,該記憶體區域被所有執行緒共享,如下圖所示。本地方法區存在一塊特殊的記憶體區域,叫常數池(Constant Pool),這塊記憶體將與String類型的分析密切相關。

堆疊(Heap):Java堆(Java Heap)是Java虛擬機器所管理的記憶體中最大的一塊。 Java堆是被所有執行緒共享的一塊記憶體區域。在此區域的唯一目的就是存放物件實例,幾乎所有的物件實例都是在這裡分配內存,但是這個物件的參考卻是在堆疊(Stack)中分配。因此,執行String s = new String("s")時,需要從兩個地方分配記憶體:在堆中為String物件分配內存,在堆疊中為引用(這個堆物件的記憶體位址,即指標)分配內存,如下圖所示。

Java堆是垃圾收集器管理的主要區域,因此又稱為「GC 堆」(Garbage Collectioned Heap)。現在的垃圾收集器基本上都是採用的分代收集演算法,所以Java堆還可以細分為:新生代(Young Generation)和老年代(Old Generation),如下圖所示。分代收集演算法的想法:第一種說法,用較高的頻率對年輕的對象(young generation)進行掃描和回收,這種叫做minor collection,而對老對象(old generation)的檢查回收頻率要低很多,稱為major collection。這樣就不需要每次GC都將記憶體中所有物件都檢查一遍,以便讓出更多的系統資源供應用系統使用;另一種說法,在分配物件遇到記憶體不足時,先對新生代進行GC (Young GC);當新生代GC之後仍無法滿足記憶體空間分配需求時, 才會對整個堆空間以及方法區進行GC(Full GC)。

在這裡可能會有讀者表示疑問:記得還有一個什麼永久代(Permanent Generation)的啊,難道它不屬於Java堆?親,你答對了!其實傳說中的永久代就是上面所說的方法區,存放的都是jvm初始化時加載器加載的一些類型資訊(包括類別資訊、常數、靜態變數等),這些資訊的生存週期比較長,GC不會在主程式運行期對PermGen Space進行清理,所以如果你的應用中有很多CLASS的話,就很可能出現PermGen Space錯誤。其相關設定參數:
• -XX:PermSize --設定Perm區的初始大小
• -XX:MaxPermSize --設定Perm區的最大值
# 新生代(Young Generation)又分為:Eden區與Survivor區,Survivor區有分為From Space和To Space。 Eden區是物件原先被指派的地方;預設情況下,From Space和To Space的區域大小相等。 JVM進行Minor GC時,將Eden中還存活的物件拷貝到Survivor區中,也會將Survivor區中仍存活的物件拷貝到Tenured區中。在這種GC模式下,JVM為了提升GC效率, 將Survivor區分為From Space和To Space,這樣就可以將物件回收和物件晉升分離開來。新生代的大小設定有2個相關參數:
• -Xmn -- 設定新生代記憶體大小。
• -XX:SurvivorRatio -- 設定Eden與Survivor空間的大小比例
舊年代(Old Generation): 當OLD 區進行major collection ;完全垃圾收集後,若Survivor及OLD區仍無法存放從Eden複製過來的部分對象,導致JVM無法在Eden區為新對象創建內存區域,則出現"Out of memory錯誤" 。
三、String型別的深度解析
讓我們從Java資料型別開始說! Java資料型態通常(分類方法多種多樣)從整體上可以分為兩大類:基礎型別和參考型,基礎型別的變數持有原始值,引用型別的變數通常表示的是對實際物件的引用,其值通常為物件的記憶體位址。
1、String的本質
開啟String的原始碼,類別註解中有這麼多段落「Strings are constant; theirare constant; theirare constant; theirare constant; theirare constant; theirare constant; theirare constant; theirare constant; theirare constant; theirare constant; theirare constant; theirare values cannot be changed after they are created. String buffers support mutable strings.Because String objects are immutable they can be shared.」。這句話總結歸納了String的一個最重要的特點:String是值不可變(immutable)的常數,是線程安全的(can be shared)。
接下來,String類別使用了final修飾符,顯示了String類別的第二個特點:String類別是不可繼承#的。
以下是String類別的成員變數定義,從類別的實作上闡明了String值是不可變的(immutable)。
#private final char value[]; private final int count;
因此,我們來看String類別的concat方法。實現此方法第一步要做的肯定是擴大成員變數value的容量,擴容的方法重新定義一個大容量的字元陣列buf。第二步就是把原來value中的字元copy到buf中來,再把需要concat的字串值也copy到buf中來,這樣子,buf中就包含了concat之後的字串值。下面就是問題的關鍵了,如果value不是final的,直接讓value指向buf,然後回傳this,則大功告成,沒有必要傳回一個新的String物件。但是。 。 。可惜。 。 。由於value是final型的,所以無法指向新定義的大容量數組buf,那該怎麼辦呢? “return new String(0, count + otherLen, buf);”,這是String類別concat實作方法的最後一個語句,重新new一個String物件傳回。這下真相大白了吧!
總結:String實質為字元數組,兩個特徵:1、此類別不可繼承;2、不變(immutable)。
2.String的定義方法
討論String的定義方法之前,先先了解常數池的概念,前面在介紹方法區的時候已經提過了。下面稍微正式的給一個定義吧。
常數池(constant pool)指的是編譯期被確定,並被保存在已編譯的.class檔案中的一些資料。它包括了關於類別、方法、介面等中的常數,也包括字串常數。常量池也具備動態性,運行期間可以將新的常數放入池中,String類別的intern()方法是此特性的典型應用。不明白嗎?後面會介紹intern方法的。虛擬機器為每個被裝載的類型維護一個常數池,池中為該類型所用常數的一個有序集合,包括直接常數(string、integer和float常數)和對其他類型、字段和方法的符號引用(與物件引用的區別?
String的定義方法歸納總共為三種方式:
• 使用關鍵字new,如:String s1 = new String("myString" );
• 直接定義,如:String s1 = "myString";
• 串聯生成,如:String s1 = "my" + "String";這種方式比較複雜,這裡就不贅述了。
第一種方式透過關鍵字new定義過程:在程式編譯期,編譯程式先去字串常數池檢查,是否存在「myString」,如果不存在,則在常數池中開闢一個內存空間存放「myString」;如果存在的話,則不用重新開啟空間,保證常數池中只有一個「myString」常數,節省記憶體空間。然後在記憶體堆中開闢一塊空間存放new出來的String實例,在堆疊中開闢一塊空間,命名為“s1”,存放的值為堆中String實例的記憶體位址,這個過程就是將引用s1指向new出來的String實例。 各位,最模糊的地方到了!堆中new出來的實例和常數池中的「myString」是什麼關係呢?等我們分析完了第二種定義方式之後再回頭分析這個問題。
第二種方式直接定義過程:在程式編譯期,編譯程式先去字串常數池檢查,是否存在“myString”,如果不存在,則在常數池中開闢一個內存空間存放“myString”;如果存在的話,則不用重新開啟空間。然後在堆疊中開闢一塊空間,命名為“s1”,存放的值為常數池中“myString”的記憶體位址。 常數池中的字串常數與堆中的String物件有什麼差別呢?為什麼直接定義的字串同樣可以呼叫String物件的各種方法呢?
帶著諸多疑問,我和大家一起探討一下堆中String物件和常數池中String常數的關係,請大家記住,僅是探討,因為本人對這塊也比較模糊。
第一种猜想:因为直接定义的字符串也可以调用String对象的各种方法,那么可以认为其实在常量池中创建的也是一个String实例(对象)。String s1 = new String("myString");先在编译期的时候在常量池创建了一个String实例,然后clone了一个String实例存储在堆中,引用s1指向堆中的这个实例。此时,池中的实例没有被引用。当接着执行String s1 = "myString";时,因为池中已经存在“myString”的实例对象,则s1直接指向池中的实例对象;否则,在池中先创建一个实例对象,s1再指向它。如下图所示:
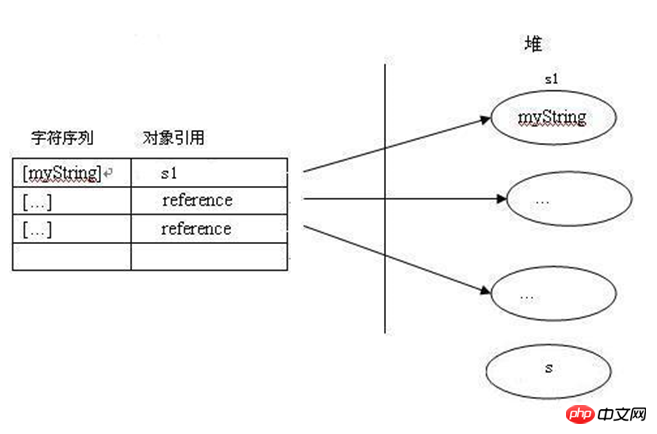
这种猜想认为:常量池中的字符串常量实质上是一个String实例,与堆中的String实例是克隆关系。
第二种猜想也是目前网上阐述的最多的,但是思路都不清晰,有些问题解释不通。下面引用《JAVA String对象和字符串常量的关系解析》一段内容。
在解析阶段,虚拟机发现字符串常量"myString",它会在一个内部字符串常量列表中查找,如果没有找到,那么会在堆里面创建一个包含字符序列[myString]的String对象s1,然后把这个字符序列和对应的String对象作为名值对( [myString], s1 )保存到内部字符串常量列表中。如下图所示:
如果虚拟机后面又发现了一个相同的字符串常量myString,它会在这个内部字符串常量列表内找到相同的字符序列,然后返回对应的String对象的引用。维护这个内部列表的关键是任何特定的字符序列在这个列表上只出现一次。
例如,String s2 = "myString",运行时s2会从内部字符串常量列表内得到s1的返回值,所以s2和s1都指向同一个String对象。
这个猜想有一个比较明显的问题,红色字体标示的地方就是问题的所在。证明方式很简单,下面这段代码的执行结果,javaer都应该知道。
String s1 = new String("myString");
String s2 = "myString";
System.out.println(s1 == s2); //按照上面的推测逻辑,那么打印的结果为true;而实际上真实的结果是false,因为s1指向的是堆中String对象,而s2指向的是常量池中的String常量。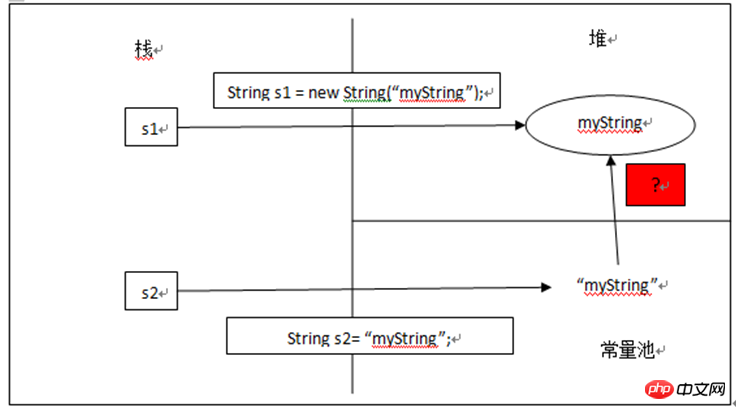
虽然这段内容不那么有说服力,但是文章提到了一个东西——字符串常量列表,它可能是解释这个问题的关键。
文中提到的三个问题,本文仅仅给出了猜想,具体请自己考证!
• 堆中new出来的实例和常量池中的“myString”是什么关系呢?
• 常量池中的字符串常量与堆中的String对象有什么区别呢?
• 为什么直接定义的字符串同样可以调用String对象的各种方法呢?
3、String、StringBuffer、StringBuilder的联系与区别
上面已经分析了String的本质了,下面简单说说StringBuffer和StringBuilder。
StringBuffer和StringBuilder都继承了抽象类AbstractStringBuilder,这个抽象类和String一样也定义了char[] value和int count,但是与String类不同的是,它们没有final修饰符。因此得出结论:String、StringBuffer和StringBuilder在本质上都是字符数组,不同的是,在进行连接操作时,String每次返回一个新的String实例,而StringBuffer和StringBuilder的append方法直接返回this,所以这就是为什么在进行大量字符串连接运算时,不推荐使用String,而推荐StringBuffer和StringBuilder。那么,哪种情况使用StringBuffe?哪种情况使用StringBuilder呢?
关于StringBuffer和StringBuilder的区别,翻开它们的源码,下面贴出append()方法的实现。

The first picture above is the implementation of the append() method in StringBuffer, and the second picture is the implementation of append() in StringBuilder. The difference should be clear at a glance. StringBuffer adds a synchronized modification before the method, which plays a synchronization role and can be used in a multi-threaded environment. The price paid for this is reduced execution efficiency. Therefore, if you can use StringBuffer for string connection operations in a multi-threaded environment, it is more efficient to use StringBuilder in a single-threaded environment.
以上是詳解Java中的String類的詳細內容。更多資訊請關注PHP中文網其他相關文章!