
詳解Redis和Memcached的區別
- 巴扎黑原創
- 2017-04-08 10:37:041222瀏覽
Redis的作者Salvatore Sanfilippo曾經對這兩種基於記憶體的資料儲存系統進行過比較:
- ## Redis支援伺服器端的資料操作:Redis比起Memcached來說,擁有更多的資料結構和並支援更豐富的資料操作,通常在Memcached裡,你需要將資料拿到客戶端來進行類似的修改再set回去。這大大增加了網路IO的次數和資料體積。在Redis中,這些複雜的操作通常和一般的GET/SET一樣有效率。所以,如果需要快取能夠支援更複雜的結構和操作,那麼Redis會是不錯的選擇。
- # 記憶體使用效率對比:使用簡單的key-value存儲的話,Memcached的內存利用率更高,而如果Redis採用詳解Redis和Memcached的區別結構來做key-value存儲,由於其組合式的壓縮,其內存利用率會高於Memcached 。
- # 效能比較:由於Redis只使用單核心,而Memcached可以使用多核心,所以平均每個核上Redis在儲存小資料時比Memcached效能更高。而在100k以上的資料中,Memcached效能要高於Redis,雖然Redis最近也在儲存大數據的效能上進行最佳化,但是比起Memcached,還是稍有遜色。
1、資料型別支援不同
# 與Memcached僅支援簡單的key-value結構的資料記錄不同,Redis支援的資料類型要豐富得多。最常使用的資料型別主要由五種:String、Hash、List、Set和Sorted Set。 Redis內部使用一個redisObject物件來表示所有的key和value。 redisObject最主要的資訊如圖所示:#
- # 常用指令:set/get/decr/incr/mget等;
- # 應用場景:String是最常用的一種資料類型,普通的key/value儲存都可以歸為此類;
- 實作方式:String在redis內部儲存預設就是一個字串,被redisObject所引用,當遇到incr、decr等操作時會轉成數值型進行計算,此時redisObject的encoding欄位為int。
- # 常用指令:hget/hset/hgetall等
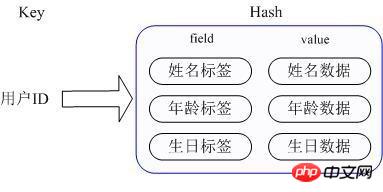
- # 應用場景:我們要儲存一個使用者資訊物件數據,其中包括使用者ID、使用者姓名、年齡和生日,透過使用者ID我們希望取得該使用者的姓名或年齡或生日;
- 實作方式:Redis的Hash實際上是內部儲存的Value為一個HashMap,並提供了直接存取這個Map成員的介面。如圖所示,Key是用戶ID, value是一個Map。這個Map的key是成員的屬性名,value是屬性值。這樣對資料的修改與存取都可以直接透過其內部Map的Key(Redis裡稱內部Map的key為field), 也就是透過 key(用戶ID) + field(屬性標籤) 就可以操作對應屬性資料。目前HashMap的實作有兩種方式:當HashMap的成員比較少時Redis為了節省記憶體會採用類似一維數組的方式來緊湊存儲,而不會採用真正的HashMap結構,這時對應的value的redisObject的encoding為zipmap,當成員數量增大時會自動轉成真正的HashMap,此時encoding為ht。
- # 常用指令:lpush/rpush/lpop/rpop/lrange等;
- 應用場景:Redis list的應用程式場景非常多,也是Redis最重要的資料結構之一,例如twitter的關注列表,粉絲列表等都可以用Redis的list結構來實現;
- ## 實作方式:Redis list的實作為一個雙向鍊錶,即可以支援反向查找和遍歷,更方便操作,不過帶來了部分額外的記憶體開銷,Redis內部的許多實現,包括發送緩衝佇列等也都是用的這個資料結構。
- 4)Set
# 常用指令:sadd/spop/smembers/sunion等;
# 應用場景:Redis set對外提供的功能與list類似是一個列表的功能,特殊之處在於set是可以自動排重的,當你需要存儲一個列表數據,又不希望出現重複數據時,set是一個很好的選擇,而set提供了判斷某個成員是否在一個set集合內的重要接口,這個也是list所不能提供的;
實作方式:set 的內部實作是一個 value永遠是null的HashMap,實際上就是透過計算詳解Redis和Memcached的區別的方式來快速排重的,這也是set能提供判斷一個成員是否在集合內的原因。
5)Sorted Set
常用指令:zadd/zrange/zrem/zcard等;
# 應用場景:Redis sorted set的使用場景與set類似,差異是set不是自動有序的,而sorted set可以透過使用者額外提供一個優先權(score)的參數來為成員排序,並且是插入有序的,即自動排序。當你需要一個有序的並且不重複的集合列表,那麼可以選擇sorted set資料結構,例如twitter 的public timeline可以以發表時間作為score來存儲,這樣獲取時就是自動按時間排好序的。
# 實作方式:Redis sorted set的內部使用HashMap和跳躍表(SkipList)來確保資料的儲存和有序,HashMap裡放的是成員到score的映射,而跳躍表裡存放的是所有的成員,排序依據是HashMap裡存的score,使用跳躍表的結構可以獲得比較高的查找效率,在實作上比較簡單。
2、記憶體管理機制不同
# 在Redis中,並不是所有的資料都一直儲存在記憶體中的。這是和Memcached相比一個最大的差異。當實體記憶體用完時,Redis可以將一些很久沒用到的value交換到磁碟。 Redis只會快取所有的key的信息,如果Redis發現記憶體的使用量超過了某一個閥值,將觸發swap的操作,Redis根據「swappability = age*log(size_in_memory)」計算出哪些key對應的value需要swap到磁碟。然後再將這些key對應的value持久化到磁碟中,同時在記憶體中清除。這種特性使得Redis可以保持超過其機器本身記憶體大小的資料。當然,機器本身的記憶體必須要能夠保持所有的key,畢竟這些資料是不會進行swap操作的。同時由於Redis將內存中的資料swap到磁碟中的時候,提供服務的主線程和進行swap操作的子線程會共享這部分內存,所以如果更新需要swap的數據,Redis將阻塞這個操作,直到子線程完成swap操作後才可以進行修改。當從Redis讀取資料的時候,如果讀取的key對應的value不在記憶體中,那麼Redis就需要從swap檔案載入對應數據,然後再傳回給請求方。 這裡就存在一個I/O線程池的問題。在預設的情況下,Redis會出現阻塞,也就是完成所有的swap檔案載入後才會對應。這種策略在客戶端的數量較小,進行大量操作的時候比較適合。但如果將Redis應用在一個大型的網站應用程式中,這顯然是無法滿足大並發的情況的。所以Redis運行我們設定I/O線程池的大小,對需要從swap檔案載入對應資料的讀取請求進行並發操作,減少阻塞的時間。
對於像Redis和Memcached這種基於記憶體的資料庫系統來說,記憶體管理的效率高低是影響系統效能的關鍵因素。傳統C語言中的malloc/free函數是最常用的分配和釋放記憶體的方法,但這種方法有很大的缺陷:首先,對於開發人員來說不匹配的malloc和free容易造成記憶體洩漏;其次頻繁調用會造成大量記憶體碎片無法回收再利用,降低記憶體利用率;最後作為系統調用,其係統開銷遠大於一般函數調用。所以,為了提高記憶體的管理效率,高效率的記憶體管理方案都不會直接使用malloc/free呼叫。 Redis和Memcached都使用了自身設計的記憶體管理機制,但是實作方法有很大的差異,以下將會對兩者的記憶體管理機制分別進行介紹。
Memcached預設使用Slab Allocation機制管理內存,其主要思想是按照預先規定的大小,將分配的內存分割成特定長度的塊以存儲相應長度的key-value數據記錄,以完全解決內存碎片問題。 Slab Allocation機制只為儲存外部資料而設計,也就是說所有的key-value資料都儲存在Slab Allocation系統裡,而Memcached的其它記憶體請求則透過普通的malloc/free來申請,因為這些請求的數量和頻率決定了它們不會對整個系統的性能造成影響Slab Allocation的原理相當簡單。 如圖所示,它首先從作業系統申請一大塊內存,並將其分割成各種尺寸的塊Chunk,並把尺寸相同的塊分成組Slab Class。其中,Chunk就是用來儲存key-value資料的最小單位。每個Slab Class的大小,可以在Memcached啟動的時候透過制定Growth Factor來控制。假設圖中Growth Factor的值為1.25,如果第一組Chunk的大小為88個位元組,第二組Chunk的大小就為112個位元組,依此類推。
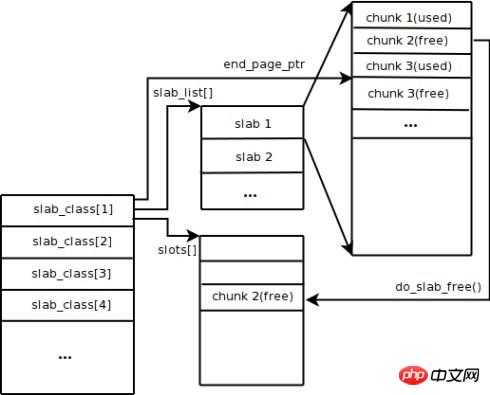
# 當Memcached接收到客戶端發送過來的數據時首先會根據收到數據的大小選擇一個最合適的Slab Class,然後通過查詢Memcached保存著的該Slab Class內空閒Chunk的列表就可以找到一個可用於存儲數據的Chunk。當一條資料庫過期或丟棄時,該記錄所佔用的Chunk就可以回收,重新加入到空閒清單中。從以上過程我們可以看出Memcached的記憶體管理制效率高,而且不會造成記憶體碎片,但是它最大的缺點就是會導致空間浪費。因為每個Chunk都分配了特定長度的記憶體空間,所以變長資料無法充分利用這些空間。如圖 所示,將100個位元組的資料快取到128個位元組的Chunk中,剩餘的28個位元組就浪費掉了。

# Redis的記憶體管理主要透過原始碼中詳解Redis和Memcached的區別.h和詳解Redis和Memcached的區別.c兩個檔案來實現的。 Redis為了方便記憶體的管理,在分配一塊記憶體之後,會將這塊記憶體的大小存入記憶體區塊的頭部。如圖所示,real_ptr是redis呼叫malloc後回傳的指標。 redis將記憶體區塊的大小size存入頭部,size所佔據的記憶體大小是已知的,為size_t類型的長度,然後回傳ret_ptr。當需要釋放記憶體的時候,ret_ptr會傳給記憶體管理程式。透過ret_ptr,程式可以很容易的算出real_ptr的值,然後將real_ptr傳給free釋放記憶體。

# Redis透過定義一個陣列來記錄所有的記憶體分配情況,這個陣列的長度為ZMALLOC_MAX_ALLOC_STAT。數組的每一個元素代表目前程式所分配的記憶體區塊的個數,且記憶體區塊的大小為該元素的下標。在原始碼中,這個陣列為詳解Redis和Memcached的區別_allocations。 詳解Redis和Memcached的區別_allocations[16]代表已指派的長度為16bytes的記憶體區塊的數量。 詳解Redis和Memcached的區別.c中有一個靜態變數used_memory用來記錄目前分配的記憶體總大小。所以,總的來看,Redis採用的是包裝的mallc/free,相較於Memcached的記憶體管理方法來說,簡單很多。
3、資料持久化支援
# Redis雖然是基於記憶體的儲存系統,但它本身是支援記憶體資料的持久化的,而且提供兩種主要的持久化策略:RDB快照和AOF日誌。而memcached是不支援資料持久化操作的。
1)RDB快照
Redis支援將目前資料的快照存成一個資料檔案的持久化機制,即RDB快照。但是一個持續寫入的資料庫如何產生快照呢? Redis借助了fork指令的copy on write機制。在產生快照時,將目前進程fork出一個子進程,然後在子進程中循環所有的數據,將資料寫成RDB檔。我們可以透過Redis的save指令來設定RDB快照產生的時機,例如設定10分鐘就產生快照,也可以配置有1000次寫入就產生快照,也可以多個規則一起實作。這些規則的定義就在Redis的設定檔中,你也可以透過Redis的CONFIG SET指令在Redis運作時設定規則,不需要重新啟動Redis。
Redis的RDB檔案不會壞掉,因為其寫入操作是在一個新進程中進行的,當產生一個新的RDB檔案時,Redis產生的子程序會先將資料寫到一個臨時檔案中,然後通過原子性rename系統呼叫將臨時文件重新命名為RDB文件,這樣在任何時候出現故障,Redis的RDB文件總是可用的。同時,Redis的RDB檔案也是Redis主從同步內部實作中的一環。 RDB有他的不足,就是一旦資料庫出現問題,那麼我們的RDB檔案中儲存的資料並不是全新的,從上次RDB檔案產生到Redis停機這段時間的資料全部丟掉了。在某些業務下,這是可以忍受的。
2)AOF日誌
AOF日誌的全名為append only file,它是一個追加寫入的日誌檔案。與一般資料庫的binlog不同的是,AOF檔是可辨識的純文本,它的內容就是一個個的Redis標準指令。只有那些會導致資料發生修改的指令才會追加到AOF檔。每一條修改資料的指令都會產生一條日誌,AOF檔會越來越大,所以Redis又提供了一個功能,叫做AOF rewrite。其功能就是重新產生一份AOF文件,新的AOF文件中一筆記錄的操作只會有一次,而不像一份老文件那樣,可能記錄了對同一個值的多次操作。其生成過程和RDB類似,也是fork一個進程,直接遍歷數據,寫入新的AOF臨時檔案。在寫入新檔案的過程中,所有的寫入操作日誌還是會寫到原來舊的AOF檔案中,同時也會記錄在記憶體緩衝區中。當重完操作完成後,會將所有緩衝區的日誌一次寫入到暫存檔案中。然後呼叫原子性的rename指令用新的AOF檔取代老的AOF檔。
AOF是一個寫檔案操作,其目的是將操作日誌寫到磁碟上,所以它也同樣會遇到我們上面說的寫入操作的流程。在Redis中對AOF呼叫write寫入後,透過appendfsync選項來控制呼叫fsync將其寫到磁碟上的時間,下面appendfsync的三個設定項,安全強度逐漸變強。
appendfsync no 當設定appendfsync為no的時候,Redis不會主動呼叫fsync去將AOF日誌內容同步到磁碟,所以這一切就完全依賴於作業系統的偵錯了。對大多數Linux作業系統,是每30秒進行一次fsync,將緩衝區中的資料寫到磁碟上。
# appendfsync everysec 當設定appendfsync為everysec的時候,Redis會預設每隔一秒進行一次fsync調用,將緩衝區中的資料寫到磁碟。但是當這次的fsync呼叫時長超過1秒時。 Redis會採取延遲fsync的策略,再等一秒鐘。也就是在兩秒後再進行fsync,這次的fsync就不管會執行多久都會進行。這時候由於在fsync時檔案描述子會被阻塞,所以目前的寫入操作就會阻塞。所以結論就是,在絕大多數情況下,Redis會每隔一秒進行一次fsync。在最壞的情況下,兩秒鐘會進行一次fsync操作。這項操作在大多數資料庫系統中稱為group commit,就是組合多次寫入操作的數據,一次將日誌寫到磁碟。
# appednfsync always 當設定appendfsync為always時,每一次寫入操作都會呼叫一次fsync,這時資料是最安全的,當然,由於每次都會執行fsync,所以其效能也會受到影響。
對於一般性的業務需求,建議使用RDB的方式進行持久化,原因是RDB的開銷並相比AOF日誌要低很多,對於那些無法忍數據丟失的應用,建議使用AOF日誌。
4、叢集管理的不同
# Memcached是全記憶體的資料緩衝系統,Redis雖然支援資料的持久化,但是全記憶體畢竟才是其高效能的本質。作為一個基於記憶體的儲存系統來說,機器物理記憶體的大小就是系統能夠容納的最大資料量。如果需要處理的資料量超過了單一機器的實體記憶體大小,就需要建立分散式叢集來擴展儲存能力。
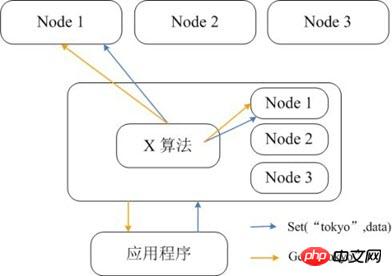
Memcached本身並不支援分散式,因此只能在客戶端透過像一致性雜湊這樣的分散式演算法來實作Memcached的分散式儲存。下圖給出了Memcached的分散式儲存實作架構。當客戶端向Memcached叢集發送資料之前,首先會透過內建的分散式演算法計算出該條資料的目標節點,然後資料會直接傳送到該節點上儲存。但客戶端查詢資料時,同樣要計算查詢資料所在的節點,然後直接向該節點發送查詢請求以取得資料。
#
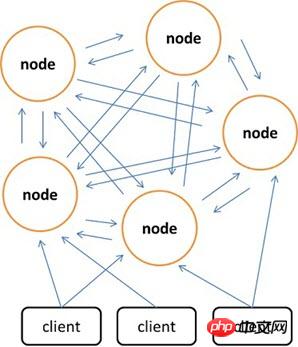
相較於Memcached只能採用客戶端實現分散式存儲,Redis更偏向於在伺服器端建構分散式儲存。最新版本的Redis已經支援了分散式儲存功能。 Redis Cluster是實現了分散式且允許單點故障的Redis高級版本,它沒有中心節點,具有線性可伸縮的功能。下圖給出Redis Cluster的分散式儲存架構,其中節點與節點之間透過二進位協定進行通信,節點與客戶端之間透過ascii協定進行通訊。在資料的放置策略上,Redis Cluster將整個key的數值域分成4096個哈希槽,每個節點上可以儲存一個或多個哈希槽,也就是說目前Redis Cluster所支援的最大節點數就是4096。 Redis Cluster所使用的分散式演算法也很簡單:crc16( key ) % HASH_SLOTS_NUMBER。
#
# 為了確保單點故障下的資料可用性,Redis Cluster引入了Master節點和Slave節點。在Redis Cluster中,每個Master節點都會有對應的兩個用於冗餘的Slave節點。這樣在整個叢集中,任兩個節點的宕機都不會導致資料的不可用。當Master節點退出後,叢集會自動選擇一個Slave節點成為新的Master節點。
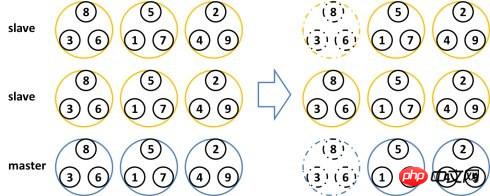
#
#
以上是詳解Redis和Memcached的區別的詳細內容。更多資訊請關注PHP中文網其他相關文章!