
不同情況下的MySQL 的遷移方案(建議)

- 怪我咯原創
- 2017-04-06 10:36:181406瀏覽
一、為什麼要遷移
MySQL 遷移是 DBA 日常維護中的一個工作。遷移,究其本義,無非是把實際存在的物體挪走,保證該物體的完整性以及延續性。就像柔軟的沙灘上,兩個天真無邪的小孩,把一堆沙子挪向其他地方,鑄造內心神往的城堡。
在生產環境中,有以下情況需要做遷移工作,如下:
#磁碟空間不夠。例如一些舊項目,選用的機型並不一定適用於資料庫。隨著時間的推移,硬碟很有可能出現短缺;
#業務出現瓶頸。例如專案中採用單機承擔所有的讀寫業務,業務壓力增大,不堪重負。如果 IO 壓力在可接受的範圍,會採用讀寫分離方案;
機器出現瓶頸。機器出現瓶頸主要在磁碟 IO 能力、記憶體、CPU,此時除了針對瓶頸做一些最佳化以外,選擇遷移是不錯的方案;
- ##專案改造。某些專案的資料庫存在跨機房的情況,可能會在不同機房中增加節點,或把機器從一個機房遷移到另一個機房。再例如,不同業務共用同一台伺服器,為了緩解伺服器壓力以及方便維護,也會做遷移。
- 為了保護隱私,本文中的伺服器IP 等資訊經過處理;
- 如果伺服器在同一機房,用伺服器IP 的D 段取代伺服器,具體的IP 請參考
架構圖;
##如果伺服器在不同機房,用伺服器IP 的C 段和D 段取代伺服器,具體的IP 請參考架構圖; 每個場景給出方法,但不會詳細地給出每一步執行什麼命令,因為一方面,這會導致文章過長;另一方面,我認為只要知道方法,具體的做法就會迎面撲來的,只取決於掌握知識的程度和獲取資訊的能力;
實戰過程中的注意事項請參考第五節。
3.1 場景一 一主一從結構遷移從庫
遵循從易到難的思路,我們從簡單的結構著手。 A 項目,原本是一主一從結構。 101 是主節點,102 是從節點。因業務需要,把 102 從節點遷移到 103,架構圖如圖一。 102 從節點的資料容量過大,不能使用 mysqldump 的形式備份。和研發溝通後,形成一致的方案。
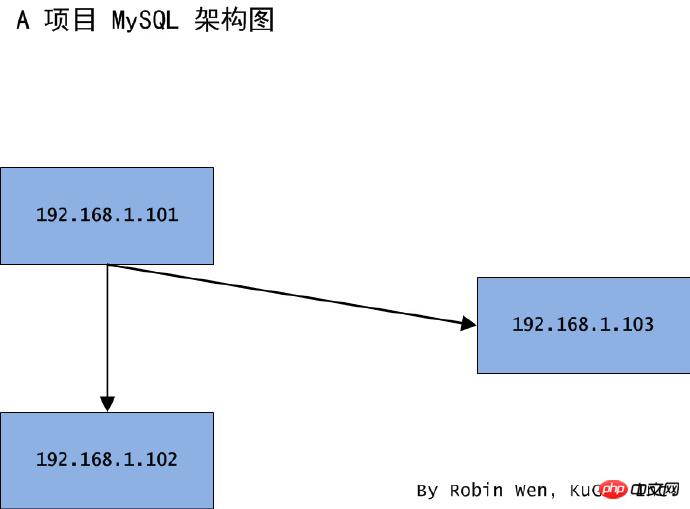
圖一一主一從結構遷移從庫架構圖
具體做法是這樣:
研發將102的讀取業務切到主函式庫;
確認102 MySQL 狀態(主要看PROCESS LIST),觀察機器流量,確認無誤後,停止102 從節點的服務;
103 新建MySQL 實例,建成以後,停止MySQL 服務,並且將整個資料目錄mv 到其他地方做備份;
將102 的整個mysql 數據目錄使用rsync 拷貝到103;
拷貝的同時,在101 授權,使103 有拉取binlog 的權限(REPLICATION SLAVE, REPLICATION CLIENT);
-
##待拷貝完成,修改103 設定檔中的server_id,注意不要和102 上的一致;
在103 啟動MySQL 實例,注意設定檔中的資料檔案路徑以及資料目錄的權限;
進入103 MySQL 實例,使用SHOW SLAVE STATUS 檢查從函式庫狀態,可以看到Seconds_Behind_Master 在遞減;
Seconds_Behind_Master 變成0 後,表示同步完成,此時可以用pt-table-checksum 檢查101 和103 的資料一致,但比較耗時,而且對主節點有影響,可以和開發一起進行資料一致性的驗證;
-
和研發溝通,除了做資料一致性驗證外,還需要驗證帳號權限,以防業務遷回後存取出錯;
完成上述步驟,可以和研發協調,把101 的部分讀業務切到103,觀察業務狀態;
如果業務沒有問題,證明遷移成功。
3.2 場景二一主一從結構遷移指定庫
我們知道一主一從只遷移從庫怎麼做之後,接下來看看怎樣同時遷移主從節點。因不同業務同時存取同一台伺服器,導致單一庫壓力過大,還不便管理。於是,打算將主節點 101 和從節點 102 同時遷移至新的機器 103 和 104,103 充當主節點,104 充當從節點,架構圖如圖二。此次遷移只需要遷移指定庫,這些庫容量不是太大,並且可以保證資料不是即時的。
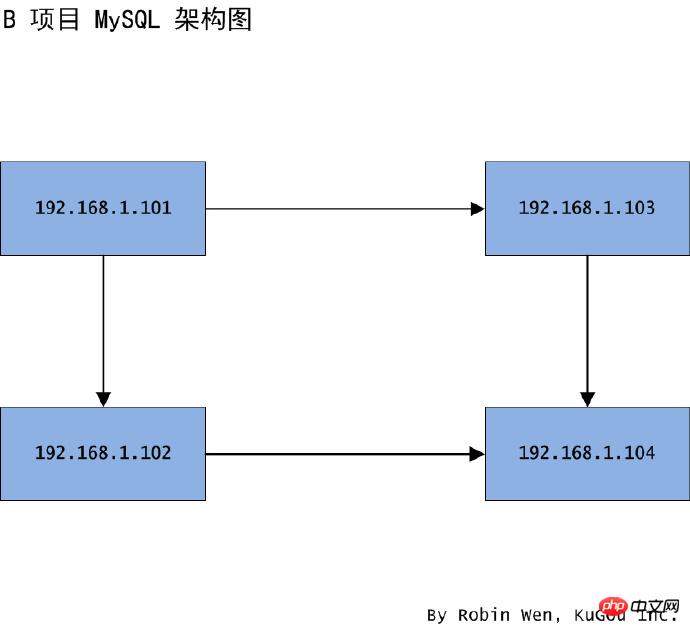
圖二一主一從結構遷移指定庫架構圖
具體的做法如下:
103 和104新建實例,搭建主從關係,此時的主節點和從節點處於空載;
#102 導出數據,正確的做法是配置定時任務,在業務低峰值做導出操作,此處選擇的是mysqldump;
102 收集指定庫需要的帳號以及權限;
- ##102 匯出資料完畢,使用rsync傳輸到103,必要時做壓縮操作;
- 103 導入數據,此時數據會自動同步到104,監控伺服器狀態以及MySQL 狀態;
- #103 導入完成,104 同步完成,103 根據102 收集的帳號授權,完成後,通知研發檢查資料以及帳戶權限; ##上述完成後,可研發協作,將101 和102 的業務遷移到103 和104,觀察業務狀態;
- ##如果業務沒有問題,證明遷移成功。
3.3 場景三 一主一從結構雙邊遷移指定函式庫
接下來看看一主一從結構雙邊遷移指定函式庫怎麼做。同樣是因為業務共用,導致伺服器壓力大,管理混亂。於是,打算將主節點101 和從節點102 同時遷移至新的機器103、104、105、106,103 充當104 的主節點,104 的從節點,105 充當106 的主節點,106 充當105 的從節點,架構圖如圖三。此次遷移只需要遷移指定庫,這些庫容量不是太大,並且可以保證資料不是即時的。我們可以看到,這次遷移和場景二很類似,無非做了兩次遷移。
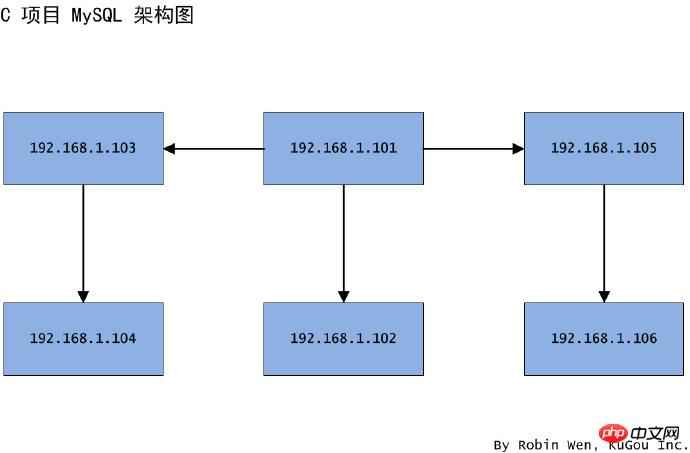
圖三一主一從結構雙邊遷移指定函式庫架構圖
#具體的做法如下:
103 和104 新建實例,搭建主從關係,此時的主節點和從節點處於空載;
102 導出103 需要的指定庫數據,正確的做法是配置定時任務,在業務低峰值做導出操作,此處選擇的是mysqldump;
102 收集103 需要的指定庫需要的帳號以及權限;
#102 匯出103 所需的指定庫資料完畢,使用rsync 傳輸到103,必要時做壓縮操作;
103 匯入數據,此時資料會自動同步到104,監控伺服器狀態以及MySQL 狀態;
103 匯入完成,104 同步完成,103 依據102 收集的帳號授權,完成後,通知研發檢查資料以及帳號權限;
上述完成後,和研發協作,將101 和102 的業務遷移到103 和104,觀察業務狀態;
105 和106 新建實例,搭建主從關係,此時的主節點和從節點處於空載;
102 導出105 需要的指定庫數據,正確的做法是配置定時任務,在業務低峰值做匯出操作,此處選擇的是mysqldump;
102 收集105 需要的指定庫需要的帳號以及權限;
102 匯出105需要的指定庫資料完畢,使用rsync 傳輸到105,必要時做壓縮操作;
105 導入數據,此時資料會自動同步到106,監控伺服器狀態以及MySQL 狀態;
105 導入完成,106 同步完成,105 根據102 收集的帳號授權,完成後,通知研發檢查資料以及帳戶權限;
上述完成後,和研發協作,將101 和102 的業務遷移到105 和106,觀察業務狀態;
如果所有業務沒有問題,證明遷移成功。
3.4 場景四一主一從結構完整遷移主從
接下來看看一主一從結構完整遷移主從怎麼做。和場景二類似,不過此處是遷移所有函式庫。因 101 主節點 IO 出現瓶頸,打算將主節點 101 和從節點 102 同時遷移至新的機器 103 和 104,103 充當主節點,104 充當從節點。遷移完成後,以前的主節點和從節點廢棄,架構圖如圖四。此次遷移是全庫遷移,容量大,需要確保即時。這次的遷移比較特殊,因為採取的策略是先取代新的從函式庫,再取代新的主庫。所以做法稍微複雜一點。

圖四一主一從結構完整遷移主從架構圖
具體的做法是這樣:
研發將102 的讀取業務切到主庫;
確認102 MySQL 狀態(主要看PROCESS LIST,MASTER STATUS),觀察機器流量,確認無誤後,停止102 從節點的服務;
104 新建MySQL 實例,建成以後,停止MySQL 服務,並且將整個資料目錄mv 到其他地方做備份,注意,此處操作的是104,也就是未來的從函式庫;
將102 的整個mysql 資料目錄使用rsync 拷貝到104;
- ##拷貝的同時,在101 授權,使104有拉取binlog 的權限(REPLICATION SLAVE, REPLICATION CLIENT);
待拷貝完成,修改104 設定檔中的server_id,注意不要和102 上的一致;
在104 啟動MySQL 實例,注意設定檔中的資料檔案路徑以及資料目錄的權限;
進入104 MySQL 實例,使用SHOW SLAVE STATUS 檢查從庫狀態,可以看到Seconds_Behind_Master 在遞減;
#Seconds_Behind_Master 變成0 後,表示同步完成,此時可以用pt-table-checksum 檢查101 和104 的資料一致,但比較耗時,而且對主節點有影響,可以和開發一起進行資料一致性的驗證;
除了做資料一致性驗證外,還需要驗證帳號權限,以防業務遷走後存取出錯;
#和研發協作,將先前102 從節點的讀取業務切到104;
利用102 的數據,將103 變為101 的從節點,方法同上;
接下來到了關鍵的地方了,我們需要把104 變成103 的從函式庫;
104 STOP SLAVE ;
103 STOP SLAVE IO_THREAD;
103 STOP SLAVE SQL_THREAD,記住MASTER_LOG_FILE 和MASTER_LOG_POS;
-
104 START SLAVE UNTIL 到上述MASTER_LOG_FILE 和MASTER_LOG_POS;
104 再次STOP SLAVE;
#104 RESET SLAVE ALL 清除從庫配置資訊;
103 SHOW MASTER STATUS,記住MASTER_LOG_FILE 和MASTER_LOG_POS;
103 授權給104 存取binlog 的權限;
#104 CHANGE MASTER TO 103;
104 重啟MySQL,因為RESET SLAVE ALL 後,查看SLAVE STATUS,Master_Server_Id 仍然為101,而不是103;
104 MySQL 重啟後,SLAVE 回自動重啟,此時查看IO_THREAD 和SQL_THREAD 是否為YES;
-
103 START SLAVE;
此時查看103 和104 的狀態,可以發現,以前104 是101 的從節點,如今變成103 的從節點了。
業務遷移之前,斷掉103 和101 的同步關係;
做完上述步驟,可以和研發協調,把101 的讀寫業務切回102,讀業務切到104。需要注意的是,此時 101 和 103 均可以寫,需要保證 101 在沒有寫入的情況下切到 103,可以使用 FLUSH TABLES WITH READ LOCK 鎖住 101,然後業務切到 103。注意,一定要業務低峰值執行,切記;
#切換完成後,觀察業務狀態;
如果業務沒有問題,證明遷移成功。
3.5 場景五 雙主結構跨機房遷移
接下來看看雙主結構跨機房遷移怎麼做。某項目出於容災考慮,使用了跨機房,採用了雙主結構,雙邊皆可寫。因為磁碟空間問題,需要對 A 地的機器進行替換。打算將主節點 1.101 和從節點 1.102 同時遷移至新的機器 1.103 和 1.104,1.103 充當主節點,1.104 充當從節點。 B 地的 2.101 和 2.102 不變,但遷移完成後,1.103 和 2.101 互為雙主。架構圖如圖五。因為是雙主結構,兩邊同時寫,如果要替換主節點,單方必須有節點停止服務。
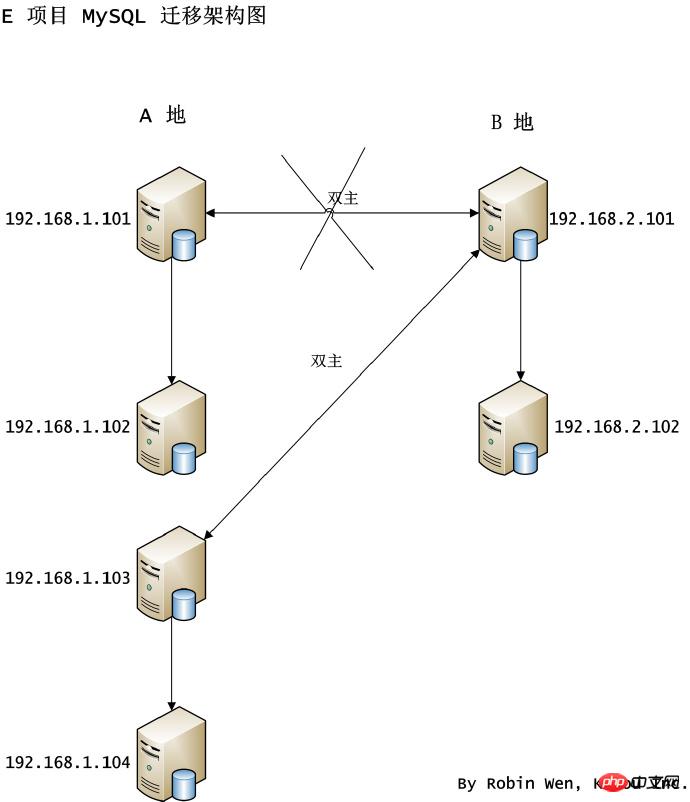
圖五雙主結構跨機房遷移架構圖
具體的做法如下:
1.103 和1.104 新實例,搭建主從關係,此時的主節點和從節點處於空載;
確認1.102 MySQL 狀態(主要看PROCESS LIST),注意觀察MASTER STATUS 不再變化。觀察機器流量,確認無誤後,停止1.102 從節點的服務;
1.103 新建MySQL 實例,建成以後,停止MySQL 服務,並且將整個資料目錄mv 到其他地方做備份;
將1.102 的整個mysql 資料目錄使用rsync 拷貝到1.103;
拷貝的同時,在1.101 授權,使1.103 有拉取binlog 的權限(REPLICATION SLAVE, REPLICATION CLIENT);
待拷貝完成,修改1.103 設定檔中的server_id,注意不要和1.102 上的一致;
- #################################################################### ######在1.103 啟動MySQL 實例,注意設定檔中的資料檔案路徑以及資料目錄的權限;###
進入1.103 MySQL 實例,使用SHOW SLAVE STATUS 檢查從庫狀態,可以看到Seconds_Behind_Master 在遞減;
Seconds_Behind_Master 變成0 後,表示同步完成,此時可以用pt-table-checksum 檢查1.101 和1.103 的資料一致,但比較耗時,而且對主節點有影響,可以和開發一起進行資料一致性的驗證;
我們使用相同的辦法,使1.104 變成1.103 的從庫;
和研發溝通,除了做資料一致性驗證外,還需要驗證帳號權限,以防業務遷走後訪問出錯;
此時,我們要做的就是將1.103 變成2.101 的從庫,具體的做法可以參考場景四;
要注意的是,1.103 的單雙號配置需要和1.101 一致;
做完上述步驟,可以和研發協調,把1.101 的讀寫業務切到1.103,把1.102 的讀業務切到1.104。觀察業務狀態;
如果業務沒有問題,證明遷移成功。
3.6 場景六 多實例跨機房遷移
#接下來我們看看多實例跨機房遷移證明做。每台機器的實例關係,我們可以參考圖六。此次遷移的目的是為了做資料修復。在 2.117 上建立 7938 和 7939 實例,取代先前資料異常的實例。因為業務的原因,某些函式庫只在 A 寫,某些函式庫只在 B 地寫,所以有同步過濾的情況。
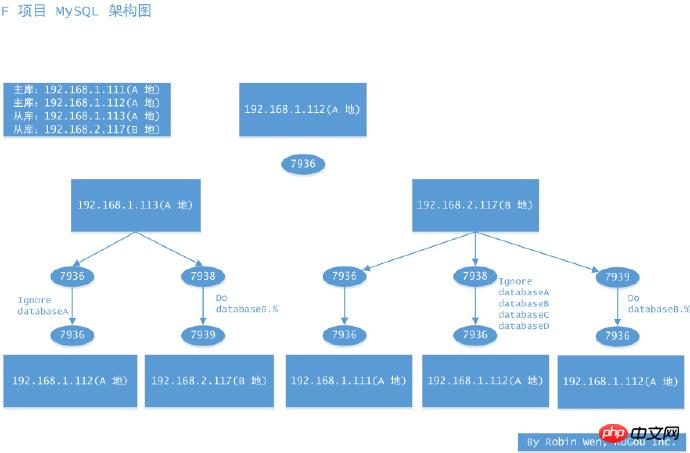
圖六多實例跨機房遷移架構圖
具體的做法如下:
1.113 針對7936 實例使用innobackupex做資料備份,注意需要指定資料庫,並且加上slave-info 參數;
備份完成後,將壓縮檔案拷貝到2.117;
2.117 建立資料目錄以及設定檔涉及的相關目錄;
2.117 使用innobackupex 復原日誌;
2.117 使用innobackupex 拷貝資料;
2.117 修改設定文件,注意以下參數:replicate-ignore-db、innodb_file_per_table = 1、read_only = 1、server_id;
2.117更改資料目錄權限;
1.112 授權,使2.117 有拉取binlog 的權限(REPLICATION SLAVE, REPLICATION CLIENT);
2.117 CHANGE MASTE TO 1.112,LOG FILE 和LOG POS 參考xtrabackup_slave_info;
2.117 START SLAVE,查看從庫狀態;
2.117 上建立7939 的建立7939 的建立7939 的建立7939。方法類似,不過設定檔需要指定replicate-wild-do-table;
#和開發一起進行資料一致性的驗證和驗證帳號權限,以防業務遷走後存取出錯;
做完上述步驟,可以和研發協調,把對應業務遷移到2.117 的7938 實例和7939 實例。觀察業務狀態;
如果業務沒有問題,證明遷移成功。
四注意事項
介紹完不同場景的遷移方案,需要注意以下幾點:
資料庫遷移,如果涉及事件,請記住主節點開啟event_scheduler 參數;
#不管什麼場景下的遷移,請隨時注意伺服器狀態,例如磁碟空間,網路抖動;另外,對業務的持續監控也是必不可少的;
CHANGE MASTER TO 的LOG FILE 和LOG POS 切記不要找錯,如果指定錯了,帶來的後果就是資料不一致或建構主從關係失敗;
執行腳本不要在$HOME 目錄,記住在資料目錄中;
遷移工作可以使用腳本做到自動化,但不要弄巧成拙,任何腳本都要經過測試;
每執行一條指令都要三思和後行,每個指令的參數意義都要搞明白;
多實例環境下,關閉MySQL 採用mysqladmin 的形式,不要把正在使用的實例關閉了;
從函式庫記得把read_only = 1 加上,這會避免很多問題;
每台機器的server_id 必須保證不一致,否則會出現同步異常的情況;
-
正確配置replicate-ignore-db 和replicate-wild-do-table;
新建的實例記得把innodb_file_per_table 設定為1,上述中的部分場景,因為之前的實例此參數為0,導致ibdata1 過大,備份和傳輸都消耗了很多時間;
使用gzip 壓縮資料時,注意壓縮完成後,gzip 會把來源檔案刪除;
所有的操作務必在從節點或備節點操作,如果在主節點操作,主節點很可能會當機;
xtrabackup 備份不會鎖定InnoDB 表,但會鎖定MyISAM 表。所以,操作之前記得檢查下當前資料庫的表是否有使用 MyISAM 儲存引擎的,如果有,要么單獨處理,要么更改表的 Engine。
五技巧
在MySQL 遷移實戰中,有以下技巧可以使用:
任何遷移LOG FILE 以relay_master_log_file (正在同步master 上的binlog 日誌名稱)為準,LOG POS 以exec_master_log_pos(正在同步當前binlog 日誌的POS 點)為準;
使用rsync 拷貝數據,可以結合expect 、nohup 使用,絕對是絕妙組合;
在使用innobackupex 備份資料的同時可以使用gzip 進行壓縮;
在使用innobackupex 備份數據,可以加上–slave-info 參數,方便做從庫;
在使用innobackupex 備份數據,可以加上–throttle 參數,限制IO,減少對業務的影響。還可以加上–parallel=n 參數,加快備份,但要注意的是,使用tar 流壓縮,–parallel 參數無效;
做資料的備份與恢復,可以把待辦事項列個清單,畫個流程,然後把需要執行的指令提前準備好;
#本地快速拷貝資料夾,有個不錯的方法,使用rsync,加上如下參數:-avhW –no-compress –progress;
不同分區之間快速拷貝數據,可以使用dd。或者用一個更可靠的方法,備份到硬碟,然後放到伺服器上。異地還有更絕的,直接快遞硬碟。
六總結
本文從為什麼要遷移講起,接下來講了遷移方案,然後講解了不同場景下的遷移實戰,最後給出了注意事項以及實戰技巧。歸納起來,也就以下幾點:
第一,遷移的目的是讓業務平穩持續地運作;
第二,遷移的核心是怎麼延續主從同步,我們需要在不同伺服器與不同業務之間找到方案;
第三,業務切換需要考慮不同MySQL 伺服器之間的權限問題;需要考慮不同機器讀寫分離的順序以及主從關係;需要考慮跨機房呼叫對業務的影響。
讀者在實作遷移的過程中,可以參考此文所提供的想法。但怎麼確保每個操作正確無誤地運行,還需要三思而後行。
說句題外話,「證明自己有能力最重要的一點就是讓一切都在自己的掌控之中。」
以上是不同情況下的MySQL 的遷移方案(建議)的詳細內容。更多資訊請關注PHP中文網其他相關文章!