
java實作cassandra高階操作之分頁實例(圖)

- 黄舟原創
- 2017-04-01 10:09:391645瀏覽
這篇文章主要介紹了java實作cassandra高階操作之分頁實例(有專案具體需求),具有一定的參考價值,有興趣的小夥伴可以參考一下。
上篇部落格講到了cassandra的分頁,相信大家會有所注意:下一次的查詢依賴上一次的查詢(上一次查詢的最後一筆記錄的全部主鍵),不像mysql那麼靈活,所以只能實現上一頁、下一頁這樣的功能,不能實現第多少頁那樣的功能(硬要實現的話性能就太低了)。
我們先看看驅動官方給的分頁做法
如果一個查詢得到的記錄數太大,一次性返回回來,那麼效率非常低,並且很有可能造成記憶體溢出,使得整個應用程式都奔潰。所以了,驅動程式對結果集進行了分頁,並傳回適當的某一頁的資料。
一、設定抓取大小(Setting the fetch size)
抓取大小指的是一次從cassandra取得的記錄數,換句話說,就是每一頁的記錄數;我們能夠在建立cluster實例的時候給它的fetch size指定一個預設值,如果沒有指定,那麼預設是5000
// At initialization:
Cluster cluster = Cluster.builder()
.addContactPoint("127.0.0.1")
.withQueryOptions(new QueryOptions().setFetchSize(2000))
.build();
// Or at runtime:
cluster.getConfiguration().getQueryOptions().setFetchSize(2000);另外,statement上也能設定fetch size
Statement statement = new SimpleStatement("your query");
statement.setFetchSize(2000);如果statement上設定了fetch size,那麼statement的fetch size將會起作用,否則則是cluster上的fetch size會起作用。
注意:設定了fetch size並不意味著cassandra總是返回準確的結果集(等於fetch size),它可能會傳回比fetch size稍微多一點或少一點的結果集。
二、結果集迭代
fetch size限制了每一頁傳回的結果集的數量,如果你迭代某一頁,驅動程式會在背景自動的抓取下一頁的記錄。如下例,fetch size = 20:
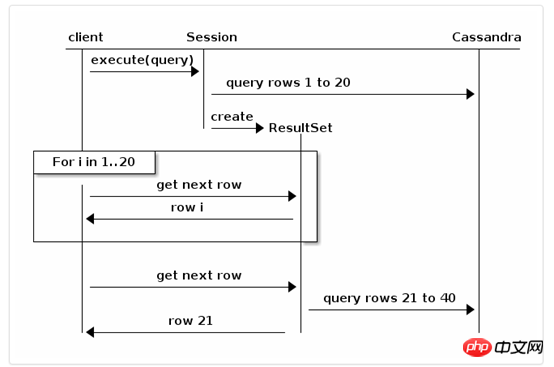
預設情況下,後台自動抓取發生在最後一刻,也就是當某一頁的記錄被迭代完的時候。如果需要更好的控制,ResultSet介面提供了以下方法:
getAvailableWithoutFetching() and isFullyFetched() to check the current state; fetchMoreResults() to force a page fetch;
以下是如何使用這些方法提前預先取下一頁,以避免在某一頁迭代完後才抓取下一頁造成的效能下降:
ResultSet rs = session.execute("your query");
for (Row row : rs) {
if (rs.getAvailableWithoutFetching() == 100 && !rs.isFullyFetched())
rs.fetchMoreResults(); // this is asynchronous
// Process the row ...
System.out.println(row);
}三、儲存並重複使用分頁狀態
有時候,將分頁狀態保存起來,對以後的恢復是非常有用的,想像一下:有一個無狀態Web服務,顯示結果列表,並顯示下一頁的鏈接,當用戶點擊這個鏈接的時候,我們需要執行與之前完全相同的查詢,除了迭代應該從上一頁停止的位置開始;相當於記住了上一頁迭代到了哪了,那麼下一頁從這裡開始即可。
為此,驅動程式會暴露一個PagingState物件,該物件表示下一頁被提取時我們在結果集中的位置。
ResultSet resultSet = session.execute("your query");
// iterate the result set...
PagingState pagingState = resultSet.getExecutionInfo().getPagingState();
// PagingState对象可以被序列化成字符串或字节数组
String string = pagingState.toString();
byte[] bytes = pagingState.toBytes();PagingState物件被序列化後的內容可以持久化儲存起來,也可用作分頁請求的參數,以備後續再次被利用,反序列化成物件即可:
PagingState.fromBytes(byte[] bytes); PagingState.fromString(String str);
請注意,分頁狀態只能使用完全相同的語句重複使用(相同的查詢,相同的參數)。而且,它是一個不透明的值,只是用來儲存一個可以被重新使用的狀態值,如果嘗試修改其內容或將其使用在不同的語句上,驅動程式會拋出錯誤。
具體我們來看下程式碼,下例是模擬頁面分頁的請求,實作遍歷teacher表中的全部記錄:
介面:
import java.util.Map;
import com.datastax.driver.core.PagingState;
public interface ICassandraPage
{
Map<String, Object> page(PagingState pagingState);
}主體程式碼:
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import com.datastax.driver.core.PagingState;
import com.datastax.driver.core.ResultSet;
import com.datastax.driver.core.Row;
import com.datastax.driver.core.Session;
import com.datastax.driver.core.SimpleStatement;
import com.datastax.driver.core.Statement;
import com.huawei.cassandra.dao.ICassandraPage;
import com.huawei.cassandra.factory.SessionRepository;
import com.huawei.cassandra.model.Teacher;
public class CassandraPageDao implements ICassandraPage
{
private static final Session session = SessionRepository.getSession();
private static final String CQL_TEACHER_PAGE = "select * from mycas.teacher;";
@Override
public Map<String, Object> page(PagingState pagingState)
{
final int RESULTS_PER_PAGE = 2;
Map<String, Object> result = new HashMap<String, Object>(2);
List<Teacher> teachers = new ArrayList<Teacher>(RESULTS_PER_PAGE);
Statement st = new SimpleStatement(CQL_TEACHER_PAGE);
st.setFetchSize(RESULTS_PER_PAGE);
// 第一页没有分页状态
if (pagingState != null)
{
st.setPagingState(pagingState);
}
ResultSet rs = session.execute(st);
result.put("pagingState", rs.getExecutionInfo().getPagingState());
//请注意,我们不依赖RESULTS_PER_PAGE,因为fetch size并不意味着cassandra总是返回准确的结果集
//它可能返回比fetch size稍微多一点或者少一点,另外,我们可能在结果集的结尾
int remaining = rs.getAvailableWithoutFetching();
for (Row row : rs)
{
Teacher teacher = this.obtainTeacherFromRow(row);
teachers.add(teacher);
if (--remaining == 0)
{
break;
}
}
result.put("teachers", teachers);
return result;
}
private Teacher obtainTeacherFromRow(Row row)
{
Teacher teacher = new Teacher();
teacher.setAddress(row.getString("address"));
teacher.setAge(row.getInt("age"));
teacher.setHeight(row.getInt("height"));
teacher.setId(row.getInt("id"));
teacher.setName(row.getString("name"));
return teacher;
}
}測試程式碼:
import java.util.Map;
import com.datastax.driver.core.PagingState;
import com.huawei.cassandra.dao.ICassandraPage;
import com.huawei.cassandra.dao.impl.CassandraPageDao;
public class PagingTest
{
public static void main(String[] args)
{
ICassandraPage cassPage = new CassandraPageDao();
Map<String, Object> result = cassPage.page(null);
PagingState pagingState = (PagingState) result.get("pagingState");
System.out.println(result.get("teachers"));
while (pagingState != null)
{
// PagingState对象可以被序列化成字符串或字节数组
System.out.println("==============================================");
result = cassPage.page(pagingState);
pagingState = (PagingState) result.get("pagingState");
System.out.println(result.get("teachers"));
}
}
}我們來看看Statement的setPagingState(pagingState)方法:
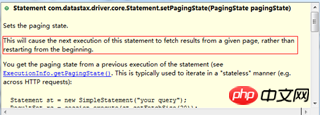
#四、偏移查詢
保存分頁狀態,能夠保證從某一頁移動到下一頁很好地運行(也可以實現上一頁),但是它不滿足隨機跳躍,例如直接跳到第10頁,因為我們不知道第10頁的前一頁的分頁狀態。像這樣需要偏移查詢的特點,並不被cassandra原生支持,理由是偏移查詢效率低下(性能與跳過的行數呈線性反比),所以cassandra官方不鼓勵使用偏移量。如果非要實作偏移查詢,我們可以在客戶端模擬實作。但是性能還是呈線性反比,也就說偏移量越大,性能越低,如果性能在我們的接受範圍內,那還是可以實現的。例如,每一頁顯示10行,最多顯示20頁,這就意味著,當顯示第20頁的時候,最多需要額外的多抓取190行,但這也不會對效能造成太大的降低,所以資料量不大的話,模擬實作偏移查詢還是可以的。
舉個例子,假設每頁顯示10筆記錄,fetch size 是50,我們請求第12頁(也就是第110行到第119行):
1、第一次執行查詢,結果集包含0到49行,我們不需要用到它,只需要分頁狀態;
2、用第一次查詢得到的分頁狀態,執行第二次查詢;
3、用第二次查詢得到的分頁狀態,執行第三次查詢。結果集包含100到149行;
4、用第三次查詢得到的結果集,先過濾掉前10筆記錄,然後讀取10筆記錄,最後丟棄剩下的記錄,讀取的10筆記錄則是第12頁需要顯示的記錄。
我們需要嘗試著找到最佳的fetch size來達到最佳平衡:太小就意味著後台更多的查詢;太大則意味著返回了更大的信息量以及更多不需要的行。
另外,cassandra本身不支援偏移量查詢。在滿足效能的前提下,客戶端模擬偏移的實作只是一種妥協。官方建議如下:
1、使用預期的查詢模式來測試程式碼,以確保假設是正確的
2、設定最高頁碼的硬限制,以防止惡意使用者觸發跳過大量行的查詢
五、總結
Cassandra對分頁的支援有限,上一頁、下一頁比較好實現。不支援偏移量的查詢,硬要實現的話,可以採用客戶端模擬的方式,但是這種場景最好不要用在cassandra上,因為cassandra一般而言是用來解決大數據問題,而偏移量查詢一旦資料量太大,效能就不敢恭維了。
在我的專案中,索引修復用到了cassandra的分頁,場景如下:cassandra的表不建二級索引,用elasticsearch實作cassandra表的二級索引,那麼就會涉及到索引的一致性修復的問題,這裡就用到了cassandra的分頁,對cassandra的某張表進行全表遍歷,逐條與elasticsearch中的數據進行匹對,若elasticsearch中不存在,則在elasticsearch中新增,若存在而又不一致,則在elasticsearch中修復。具體elasticsearch怎麼樣實作cassandra的索引功能,在我後續部落格中會專門的講解,這裡就不多說了。而在cassandra表進行全表遍歷的時候就需要用到分頁,因為表中資料量太大,億級別的資料不可能一次全部載入到記憶體中。
以上是java實作cassandra高階操作之分頁實例(圖)的詳細內容。更多資訊請關注PHP中文網其他相關文章!