


xml(可擴展標記語言)看起來可能像某種w3c標準——現在沒有什麼實際影響,即使以後能派上用場,也是很久以後的事。但實際上,它現在已經被應用了。所以,不要等到xml已經加進了你最愛的html編輯器時才開始使用它。之間的資料表示。了使用xml的許多有效方法。
#產生動態xml從資料庫產生html並不新鮮,但產生xml卻很新鮮。 #xsl(可擴充樣式表語言)是定義xml資料顯示格式的好方法,如果寫成幾個
靜態範本會更有效。 ##xml加上xsl等於html。 xml的能力來自於它的靈活性。 ,第一步工作都是建立標準的資料格式。 ##是否要使用dom(文檔物件模型)或sax(xml的簡化api)解析
確定資料:
因為沒有標準的xml格式,開發者可以自由地開發自己的格式。某個xml格式被修改,則使用它的系統可能也需要被修改,所以你應該建立盡可能完整的格式。新增標籤,而不是修改標籤。所有的頁面都使用全部數據,但我們還是由此開發出適用於所有數據的非常完整的xml數據格式。例如,我們的產品明細資訊頁面顯示的資料比產品瀏覽頁面多。然而,我們在這兩種情況下仍然使用相同的資料格式,因為每個頁面的xsl模板都只使用它所需的欄位。
是否使用dtd
在sparks.com,我們使用組織良好的xml,而不使用只是正確的xml,因為前者不需要dtd。 dtd在使用者點擊和看到頁面之間加入了一個處理層。我們發現這一層需要太多的處理。當然,以xml格式與其他公司通訊時,使用dtd還是很不錯的。因為dtd能在發送和接受時能保證資料結構正確。
選擇解析引擎
現在,可以使用的解析引擎有好幾個。選擇哪一個幾乎完全取決於你的應用需求。如果你決定使用dtd,那麼這個解析引擎必須能讓你的xml被dtd驗證。你可以將驗證另放到一個進程中,但那樣會影響效能。 sax和dom是兩個基本的解析模型。 sax是基於
事件,所以在xml被解析時,事件被傳送給引擎。接下來,事件與輸出檔案同步。 dom解析引擎為動態xml資料和xsl樣式表建立層次樹狀結構。透過隨機存取dom樹,可以提供xml數據,就像由xsl樣式表決定一樣。 sax模型上的爭論主要集中在對dom結構的記憶體降低過度和加快xsl樣式表解析時間縮短方面。
然而,我們發現使用sax的許多系統並沒有充分發揮它的能力。這些系統用它來建立dom結構並透過dom結構來發送事件。用這種方法,在任何xml處理之前必須從樣式表建立dom,所以效能會下降。
二、產生動態xml
一旦建立了xml格式,我們需要一種能夠將其從資料庫動態移植的方法。
產生xml文件相對來說比較簡單,因為它只需要一個可以處理字串的系統。我們建立了一個使用java servlet、enterprise javabean server、jdbc和rdbms(關係型資料庫管理系統)的系統。
servlet透過把產生xml文件的任務交給enterprise javabean (ejb)來處理產品資訊請求。
ejb使用jdbc從資料庫查詢所需的產品詳細資料。
ejb產生xml檔並把它傳遞給servlet。
servlet呼叫解析引擎,從xml檔案和靜態的xsl樣式表中建立html輸出。 (有關xsl應用的其他信息,請參閱用xsl作為模板語言。)
生成xml的例子
在java中創建xml文檔字符串的真正代碼可以分成幾個方法和類。
啟動xml產生過程的程式碼放在ejb方法裡。這個實例會立即建立一個stringbuffer,以便儲存產生的xml字串。
stringbuffer xml = new stringbuffer();
xml.append(xmlutils.begindocument("/browse_find/browse.xsl", "browse", request));
xml.append(product.toxml());
xml.append(xmlutils.enddocument("browse");
out.print(xml.tostring());後面的三個xml.append()變元本身就是對其他方法的呼叫。
產生檔案頭
第一個附加方法呼叫xmlutils類別來產生xml檔案頭。我們的java servlet中的程式碼如下:
public static string begindocument(string stylesheet, string page)
{
stringbuffer xml = new stringbuffer();
xml.append( "<?xml version=\"1.0\"?>\n")
.append( "<?xml-stylesheet href=\"")
.append(stylesheet).append( "\"")
.append( " type =\"text/xsl\"?>\n");
xml.append( "<").append(page).append(">\n");
return xml.tostring();
}這段程式碼產生了xml檔案頭。 標籤把本文件定義為支援1.0版本的xml檔。第二行程式碼指向使用以顯示資料的正確樣式表的位置。最後包含進去的是項目級標籤(本實例為
<?xml version="1.0"?> <?xml-stylesheet href="/browse_find/browse.xsl" type="text/xsl"?> <browse>
填入產品資訊
完成了檔案頭後,控制方法會呼叫java物件來產生它的xml。本例中呼叫的是product物件。 product物件使用兩個方法來產生它的xml表示。第一個方法toxml()透過產生
public string toxml()
{
stringbuffer xml = new stringbuffer( "<product>\n");
xml.append(internalxml());
xml.append( "</product>\n");
return xml.tostring();
}
public string internalxml()
{
stringbuffer xml = new
stringbuffer( "\t")
.append(producttype).append( "\n");
xml.append( "\t").append(idvalue.trim())
.append( "\n");
xml.append( "\t").append(idname.trim())
.append( "\n");
xml.append( "\t").append(page.trim())
.append( "\n");
厖?
xml.append( "\t").append(amount).append("\n");
xml.append( "\t").append(vendor).append("\n");
xml.append( "\t\n");
xml.append( "\t").append(pubdesc).append("\n");
xml.append( "\t").append(vendesc).append("\n";
厖?
return xml.tostring();
}關閉檔案
最後,xmlutils.enddocument()方法被呼叫。這個呼叫關閉xml標籤(本例中為),最後完成架構好的xml檔。來自控制方法的整個stringbuffer也轉換成字串,並傳回給處理最初http請求的servlet。
三、用xsl當模板語言
為了得到html輸出,我們把產生的xml檔和控制xml資料如何表示的xsl模板結合。我們的xsl模板由精心組織的xsl和html標籤組成。
開始建模板
我們的xsl模板開始部分與下面這段程式碼類似。第一行程式碼為必要程式碼,將本檔案定義為xsl樣式表。 xmlns:xsl=屬性引用本檔案所使用的xml名稱空間,而version=屬性定義名稱空間的版本號。在文件的末尾,我們關閉標籤。
由開始的第二行程式碼確定了xsl模板的模式。 match屬性是必需的,在這裡指向xml標籤
接下來,我們來看看組織良好的html。由於它將被xml解析引擎處理,所以必須符合組織良好的xml的所有規則。從本質上來講,這意味著所有的開始標籤必須有對應的結束標籤。例如,通常不被結束的
標籤,必須用
關閉。<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/xsl/transform" version="1.0"> <xsl:template match="basketpage"> <html> <head> <title>shopping bag / adjust quantity</title> </head> <body bgcolor="#cccc99" bgproperties="fixed" link="#990000" vlink="#990000"> <br> <br> </xsl:template> </xsl:stylesheet>
在模板的主體內,有許多xsl標籤被用來為資料表示提供邏輯。下面解釋兩個常用的標籤。
choose
在这个例子里,when标签会为quantity标签检查xml。如果quantity标签里含有值为真的error属性,quantity标签将会显示列在下面的表格单元。如果属性的值不为真,xsl将会显示otherwise标签间的内容。在下面的实例里,如果error属性不真,则什么都不会被显示。
<xsl:choose> <xsl:when test="quantity[@error='true']"> <td bgcolor="#ffffff"><img src="/static/imghwm/default1.png" data-src="http://img.sparks.com/images/i-catalog/sparks_images/sparks_ui/clearpixel.gif" class="lazy" style="max-width:90%" style="max-width:90%" / alt="使用XML和XSL產生動態頁面的程式碼詳解" ></td> <td valign="top" bgcolor="#ffffff" colspan="2"> <font face="verdana, arial" size="1" color="#cc3300"><b>*not enough in stock. your quantity was adjusted accordingly.</b></font></td> </xsl:when> <xsl:otherwise> </xsl:otherwise> </xsl:choose>
for-each
<xsl:for-each select="package"> <xsl:apply-templates select="product"/> </xsl:for-each>
for-each 循环在程序遇到标签时开始。这个循环将在程序遇到标签时结束。一旦这个循环运行,每次标签出现时都会应用这个模板。
四、生成html
将来的某一时刻,浏览器将会集成xml解析引擎。到那时,你可以直接向浏览器发送xml和xsl文件,而浏览器则根据样式表中列出的规则显示xml数据。不过,在此之前开发者们将不得不在他们服务器端的系统里创建解析功能。
在sparks.com,我们已经在java servlet里集成了一个xml解析器。这个解析器使用一种称为xslt (xsl transformation)的机制,按xsl标签的说明向xsl模板中添加xml数据。
当我们的java servlet处理http请求时,servlet检索动态生成的xml,然后xml被传给解析引擎。根据xml文件中的指令,解析引擎查找适当的xsl样式表。解析器通过dom结构创建html文件,然后这个文件再传送给发出http请求的用户。
如果你选择使用sax模型,解析器会通读xml源程序,为每个xml标签创建一个事件。事件与xml数据对应,并最终按xsl标签向样式表中插入数据。
以上是使用XML和XSL產生動態頁面的程式碼詳解的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 XML外部实体注入漏洞的示例分析May 11, 2023 pm 04:55 PM
XML外部实体注入漏洞的示例分析May 11, 2023 pm 04:55 PM一、XML外部实体注入XML外部实体注入漏洞也就是我们常说的XXE漏洞。XML作为一种使用较为广泛的数据传输格式,很多应用程序都包含有处理xml数据的代码,默认情况下,许多过时的或配置不当的XML处理器都会对外部实体进行引用。如果攻击者可以上传XML文档或者在XML文档中添加恶意内容,通过易受攻击的代码、依赖项或集成,就能够攻击包含缺陷的XML处理器。XXE漏洞的出现和开发语言无关,只要是应用程序中对xml数据做了解析,而这些数据又受用户控制,那么应用程序都可能受到XXE攻击。本篇文章以java
 如何用PHP和XML实现网站的分页和导航Jul 28, 2023 pm 12:31 PM
如何用PHP和XML实现网站的分页和导航Jul 28, 2023 pm 12:31 PM如何用PHP和XML实现网站的分页和导航导言:在开发一个网站时,分页和导航功能是很常见的需求。本文将介绍如何使用PHP和XML来实现网站的分页和导航功能。我们会先讨论分页的实现,然后再介绍导航的实现。一、分页的实现准备工作在开始实现分页之前,需要准备一个XML文件,用来存储网站的内容。XML文件的结构如下:<articles><art
 php如何将xml转为json格式?3种方法分享Mar 22, 2023 am 10:38 AM
php如何将xml转为json格式?3种方法分享Mar 22, 2023 am 10:38 AM当我们处理数据时经常会遇到将XML格式转换为JSON格式的需求。PHP有许多内置函数可以帮助我们执行这个操作。在本文中,我们将讨论将XML格式转换为JSON格式的不同方法。
 Python中怎么对XML文件的编码进行转换May 21, 2023 pm 12:22 PM
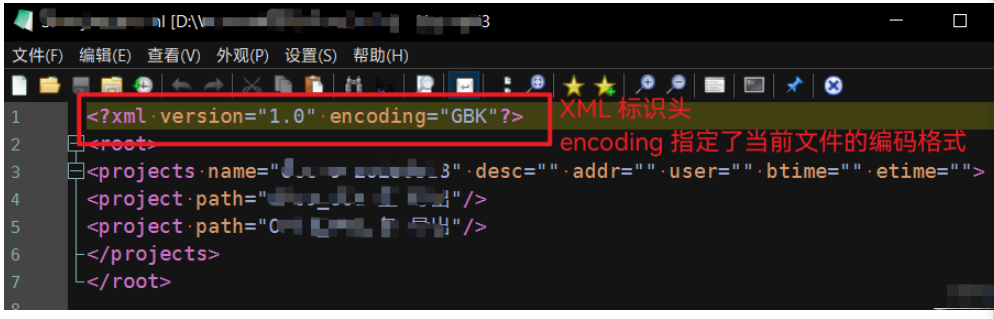
Python中怎么对XML文件的编码进行转换May 21, 2023 pm 12:22 PM1.在Python中XML文件的编码问题1.Python使用的xml.etree.ElementTree库只支持解析和生成标准的UTF-8格式的编码2.常见GBK或GB2312等中文编码的XML文件,用以在老旧系统中保证XML对中文字符的记录能力3.XML文件开头有标识头,标识头指定了程序处理XML时应该使用的编码4.要修改编码,不仅要修改文件整体的编码,还要将标识头中encoding部分的值修改2.处理PythonXML文件的思路1.读取&解码:使用二进制模式读取XML文件,将文件变为
 Python中xmltodict对xml的操作方式是什么May 04, 2023 pm 06:04 PM
Python中xmltodict对xml的操作方式是什么May 04, 2023 pm 06:04 PMPythonxmltodict对xml的操作xmltodict是另一个简易的库,它致力于将XML变得像JSON.下面是一个简单的示例XML文件:elementsmoreelementselementaswell这是第三方包,在处理前先用pip来安装pipinstallxmltodict可以像下面这样访问里面的元素,属性及值:importxmltodictwithopen("test.xml")asfd:#将XML文件装载到dict里面doc=xmltodict.parse(f
 使用nmap-converter将nmap扫描结果XML转化为XLS实战的示例分析May 17, 2023 pm 01:04 PM
使用nmap-converter将nmap扫描结果XML转化为XLS实战的示例分析May 17, 2023 pm 01:04 PM使用nmap-converter将nmap扫描结果XML转化为XLS实战1、前言作为网络安全从业人员,有时候需要使用端口扫描利器nmap进行大批量端口扫描,但Nmap的输出结果为.nmap、.xml和.gnmap三种格式,还有夹杂很多不需要的信息,处理起来十分不方便,而将输出结果转换为Excel表格,方面处理后期输出。因此,有技术大牛分享了将nmap报告转换为XLS的Python脚本。2、nmap-converter1)项目地址:https://github.com/mrschyte/nmap-
 xml中node和element的区别是什么Apr 19, 2022 pm 06:06 PM
xml中node和element的区别是什么Apr 19, 2022 pm 06:06 PMxml中node和element的区别是:Element是元素,是一个小范围的定义,是数据的组成部分之一,必须是包含完整信息的结点才是元素;而Node是节点,是相对于TREE数据结构而言的,一个结点不一定是一个元素,一个元素一定是一个结点。
 深度使用Scrapy:如何爬取HTML、XML、JSON数据?Jun 22, 2023 pm 05:58 PM
深度使用Scrapy:如何爬取HTML、XML、JSON数据?Jun 22, 2023 pm 05:58 PMScrapy是一款强大的Python爬虫框架,可以帮助我们快速、灵活地获取互联网上的数据。在实际爬取过程中,我们会经常遇到HTML、XML、JSON等各种数据格式。在这篇文章中,我们将介绍如何使用Scrapy分别爬取这三种数据格式的方法。一、爬取HTML数据创建Scrapy项目首先,我们需要创建一个Scrapy项目。打开命令行,输入以下命令:scrapys


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

ZendStudio 13.5.1 Mac
強大的PHP整合開發環境

WebStorm Mac版
好用的JavaScript開發工具

記事本++7.3.1
好用且免費的程式碼編輯器

mPDF
mPDF是一個PHP庫,可以從UTF-8編碼的HTML產生PDF檔案。原作者Ian Back編寫mPDF以從他的網站上「即時」輸出PDF文件,並處理不同的語言。與原始腳本如HTML2FPDF相比,它的速度較慢,並且在使用Unicode字體時產生的檔案較大,但支援CSS樣式等,並進行了大量增強。支援幾乎所有語言,包括RTL(阿拉伯語和希伯來語)和CJK(中日韓)。支援嵌套的區塊級元素(如P、DIV),

MinGW - Minimalist GNU for Windows
這個專案正在遷移到osdn.net/projects/mingw的過程中,你可以繼續在那裡關注我們。 MinGW:GNU編譯器集合(GCC)的本機Windows移植版本,可自由分發的導入函式庫和用於建置本機Windows應用程式的頭檔;包括對MSVC執行時間的擴展,以支援C99功能。 MinGW的所有軟體都可以在64位元Windows平台上運作。

