


問題
通常當我們提起XML的使用時,最頭痛的部分便是XML的verbosity與XML的解析速度,當需要處理大XML檔案時這個問題便變得格外嚴重。我在這裡提及的,便是如何優化XML處理速度的話題。
當我們選擇處理XML檔案的時候,我們大致上有兩種選擇:
DOM,這是W3C的標準模型,它將XML的結構資訊以樹形的方式構建,提供了遍歷這顆樹的介面與方法。
SAX,一種低階的parser,逐元素的向前唯讀處理,不含有結構資訊。
以上兩種選擇都各有利弊,但是都不是特別好的解決方案,它們的優缺點如下:
DOM
優點:易用性強,因為所有的XML結構資訊都存在於記憶體中,遍歷簡單,支援XPath。
缺點:Parsing速度太慢,記憶體佔用過高(原始檔案的5x~10x),對大檔案來說幾乎不可能使用。
SAX
優點:Parsing速度快,記憶體佔用不會與XML的大小連結(可以做到XML漲記憶體不漲)。
缺點:易用性差,因為沒有結構訊息,且無法遍歷,不支援XPath。如果需要結構的話只能讀一點構造一點,這樣的可維護性特別的差。
我們可以看出,基本上DOM與SAX是正好相反的兩個極端,但是任何一個都不能很好的滿足我們的大部分要求,我們需要找出另外一種處理方法來。注意XML的效率問題並不是XML本身的問題,而是處理XML的Parser的問題,就像我們在上面看到的兩種方法有不同的效率權衡一樣。
思考
我們很喜歡類似DOM的使用方法,因為我們可以遍歷,這意味著可以支援XPath,大大增強了易用性,但DOM的效率很低。就像我們已經知道,效率問題出在處理機制。那麼,DOM到底有哪些方面影響了它的效率呢?下面讓我們來做一個全面的解剖:
在當今大多數基於虛擬機器(託管,或任何類似機制)技術的平台下,物件的建立銷毀是一個耗時的作業(這裡值得主要是Garbage Collection的耗時),DOM機制中所運用的大量的物件創建銷毀無疑是影響其效率的原因之一(會引發過多的Garbage Collection)。
每個物件都會額外有32bits用來儲存它的記憶體位址,當像DOM一樣擁有大量物件的時候這個額外開支也是不小的。
造成以上兩個問題的最主要的效率問題在於,DOM與SAX都是extractive parsing模式,這種解析模式註定了DOM與SAX都需要大量的創建(銷毀)對象,引起效率問題。所謂的extractive parsing就是說在解析XML時,DOM或SAX會提取一部分原始檔案(一般來說是一個字串),然後在記憶體中進行解析建構(輸出自然就是一個或一些物件了)。拿DOM這個例子來說,DOM會將每一個element, attribute, PRocessing-instruction, comment等等解析成物件並給與結構,這就是所謂的extractive parsing。
由extractive的問題帶來的另一個問題是更新效率,在DOM中(SAX因為不支持更新所以根本不提它),每一次需要做改動時,我們要做的就是將對象的信息再解析回XML的字串,注意這個解析是個完整的解析,也就是說,原始檔案並沒有被利用,而是直接將DOM模型重新完整解析成XML字串。換句話說,也就是DOM並不支援Incremental Update(增量更新)。
另一個很可能不被注意到的「小」問題便是XML的編碼,無論是何種解析方法都需要能夠處理XML的編碼,也就是說,在讀取的時候解碼,在寫入的時候編碼。 DOM的另一個效率問題便是當我對於一個大XML只想做很小的一塊兒修改的時候它也必須先將整個文件進行解碼,然後構建結構。無形中又是一個開銷。
讓我們來總結一下問題,簡單的講DOM的效率問題主要出在它的extractive parsing模式(SAX也是一樣,有同樣的問題),由此引發了一系列相關問題,如果可以擊破這些效率瓶頸的話那麼可以想像XML的處理效率將進一步的得到提升。如果XML的易用性與處理效率得到飛躍性的提高的話,那麼XML的應用範圍,應用模式將得到更一步的昇華,或許由此可以產生出許許多多精彩的以前連想都沒有想過的基於XML的產品來。
出路
VTD-XML便是對上述問題的思考後給出的答案,它是一個non-extractive XML parser,由於它出色的機制,很好的解決(避免)了上述所提出的各種問題,也「順便」帶來了non-extractive的其他好處,像是快速的解析與遍歷、XPath的支援、Incremental Update等等。我這裡有一組數據,取自VTD-XML的官方網站:
VTD-XML的解析速度是SAX(with NULL content handler)的1.5x~2.0x。 With NULL content handler的意思是說SAX解析中沒有插入任何額外的處理邏輯,也就是SAX的最高速度。
VTD-XML的記憶體佔用是原XML的1.3x~1.5x(其中1.0x的部分是原XML,0.3x~0.5x是VTD-XML佔用的部分),而DOM的記憶體佔用則是原XML的5x~10x。舉一個例子,如果一個XML的大小是50MB,那麼用VTD-XML讀取進來記憶體佔用會在65MB~75MB之間,而DOM的記憶體佔用則會在250M~500MB之間。基於這個資料用DOM處理大的XML檔幾乎是不可能的選擇。
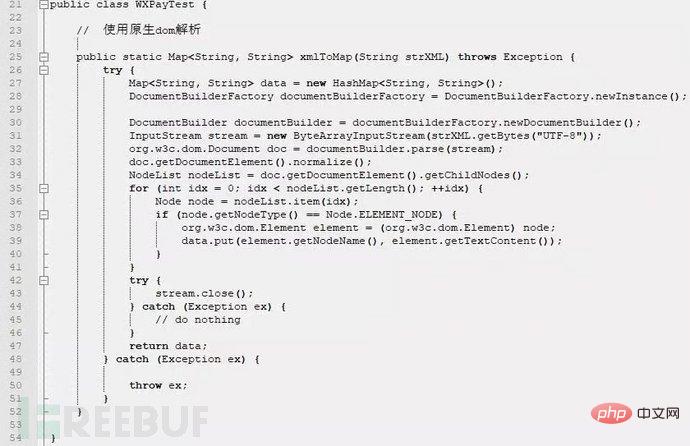
你可能會覺得不可思議,真的可以做出比DOM易用性還好,比SAX還快的XML解析器嗎?別急著下定論,還是來看看VTD-XML的原理吧!
基本原理
就像大多數好的產品一樣,VTD-XML的原理並不複雜,而是很巧妙。為了實現non-extractive這個目的,它將原XML檔案原封不動的以二進位的方式讀進內存,連解碼都不做,然後在這個byte數組上解析每個element的位置並把一些資訊記錄下來,之後的遍歷操作便在這些保存下來的record上進行,如果需要提取XML內容就利用record中的位置等資訊在原始byte數組上進行解碼並傳回字串。這一切看起來都很簡單,但是,這個簡單的過程確實有多個性能細節在裡邊,並且隱藏了若干個潛在的能力。下面我們先來描述各個效能細節:
為了避免過多的物件創建,VTD-XML決定採用原始的數值類型作為record的類型,這樣就可以不必用heap。 VTD-XML的record機制就叫做VTD(Virtual Token Descriptor),VTD將效能瓶頸在tokenization階段就解決掉了真的是很巧妙很用心的做法。 VTD是一個64bits長度的數值類型,記錄了每個element的起始位置(offset),長度(length),深度(depth)以及token的類型(type)等資訊。
注意VTD是固定長度的(官方決定用64bits),這樣做的目的就是為了提高性能,因為長度固定,在讀取,查詢等操作的時候格外的高效(O(1)),也就是可以用數組這種高效的結構來組織VTD大大減少了因為大量使用物件而產生的效能問題。
VTD的超能力(一點都不誇張地說)就在於它能夠將XML這種樹形的資料結構簡單的變換換成對一個byte數組的操作,任何你能想像到的對於byte數組的操作都可以應用在XML上了。這是因為讀取進來的XML是二進制的(byte數組),而VTD則記錄了每個element的位置等訪問用信息,當我們找到要操作的VTD的時候,只要用offset與length等信息就可以對原始byte數組進行任何操作,或者可以直接對VTD進行操作。舉例來說,我想在一個大XML中找出一個element並刪除它,那麼我只需要找到這個element的VTD(遍歷方法稍候再講),將這個VTD從VTD數組中刪除,然後再利用所有的VTD寫出到另一個byte數組就可以了,因為刪除的VTD標明了要刪除的element的位置,所以在新寫入的byte數組中就不會出現這段element了,用VTD寫入新的byte數組其實就是一個byte數組的拷貝,其效率相當的高,這就是所謂的增量更新(incremental update)。
關於VTD-XML的遍歷方式,它採用了LC (Location Cache),簡單地說就是將VTD以其深度作為標準構建的一個樹形的表結構。 LC的entry也是64bits長的數值類型,前32bits代表一個VTD的索引(index),後32bits代表了這個VTD的第一個child的索引。利用這些資訊就可以計算出任何一個你想要到達的位置了,關於具體的遍歷方法請參考官方網站的文章。基於這種遍歷方式的VTD-XML有與DOM不同的操作接口,這是可以理解的,並且,VTD-XML的這種遍歷方式可以在最少的幾步內將你帶到你所需要的地方去,遍歷的性能十分突出。
總結
就像你上面看到的,VTD-XML有著迷人的特性,而如今的1.5版本中已經加入了XPath的支援(只要可以遍歷,就可以支援XPath ,這是早晚的事:-)),它的實用性已經超越了當今我們所想的範圍了。另一個VTD-XML的超能力,就是基於它現在的處理方式,完全可以支援未來的Binary XML標準,並透過Binary化將XML的應用推向更高一層樓!這也是我目前所期待的! :-)
不過,VTD-XML仍有許多需要改進與完善的地方,這方面值得我們努力與探討。
以上就是新興XML處理方法VTD-XML介紹的內容,更多相關內容請關注PHP中文網(www.php.cn)!

 如何用PHP和XML实现网站的分页和导航Jul 28, 2023 pm 12:31 PM
如何用PHP和XML实现网站的分页和导航Jul 28, 2023 pm 12:31 PM如何用PHP和XML实现网站的分页和导航导言:在开发一个网站时,分页和导航功能是很常见的需求。本文将介绍如何使用PHP和XML来实现网站的分页和导航功能。我们会先讨论分页的实现,然后再介绍导航的实现。一、分页的实现准备工作在开始实现分页之前,需要准备一个XML文件,用来存储网站的内容。XML文件的结构如下:<articles><art
 XML外部实体注入漏洞的示例分析May 11, 2023 pm 04:55 PM
XML外部实体注入漏洞的示例分析May 11, 2023 pm 04:55 PM一、XML外部实体注入XML外部实体注入漏洞也就是我们常说的XXE漏洞。XML作为一种使用较为广泛的数据传输格式,很多应用程序都包含有处理xml数据的代码,默认情况下,许多过时的或配置不当的XML处理器都会对外部实体进行引用。如果攻击者可以上传XML文档或者在XML文档中添加恶意内容,通过易受攻击的代码、依赖项或集成,就能够攻击包含缺陷的XML处理器。XXE漏洞的出现和开发语言无关,只要是应用程序中对xml数据做了解析,而这些数据又受用户控制,那么应用程序都可能受到XXE攻击。本篇文章以java
 php如何将xml转为json格式?3种方法分享Mar 22, 2023 am 10:38 AM
php如何将xml转为json格式?3种方法分享Mar 22, 2023 am 10:38 AM当我们处理数据时经常会遇到将XML格式转换为JSON格式的需求。PHP有许多内置函数可以帮助我们执行这个操作。在本文中,我们将讨论将XML格式转换为JSON格式的不同方法。
 Python中xmltodict对xml的操作方式是什么May 04, 2023 pm 06:04 PM
Python中xmltodict对xml的操作方式是什么May 04, 2023 pm 06:04 PMPythonxmltodict对xml的操作xmltodict是另一个简易的库,它致力于将XML变得像JSON.下面是一个简单的示例XML文件:elementsmoreelementselementaswell这是第三方包,在处理前先用pip来安装pipinstallxmltodict可以像下面这样访问里面的元素,属性及值:importxmltodictwithopen("test.xml")asfd:#将XML文件装载到dict里面doc=xmltodict.parse(f
 使用nmap-converter将nmap扫描结果XML转化为XLS实战的示例分析May 17, 2023 pm 01:04 PM
使用nmap-converter将nmap扫描结果XML转化为XLS实战的示例分析May 17, 2023 pm 01:04 PM使用nmap-converter将nmap扫描结果XML转化为XLS实战1、前言作为网络安全从业人员,有时候需要使用端口扫描利器nmap进行大批量端口扫描,但Nmap的输出结果为.nmap、.xml和.gnmap三种格式,还有夹杂很多不需要的信息,处理起来十分不方便,而将输出结果转换为Excel表格,方面处理后期输出。因此,有技术大牛分享了将nmap报告转换为XLS的Python脚本。2、nmap-converter1)项目地址:https://github.com/mrschyte/nmap-
 xml中node和element的区别是什么Apr 19, 2022 pm 06:06 PM
xml中node和element的区别是什么Apr 19, 2022 pm 06:06 PMxml中node和element的区别是:Element是元素,是一个小范围的定义,是数据的组成部分之一,必须是包含完整信息的结点才是元素;而Node是节点,是相对于TREE数据结构而言的,一个结点不一定是一个元素,一个元素一定是一个结点。
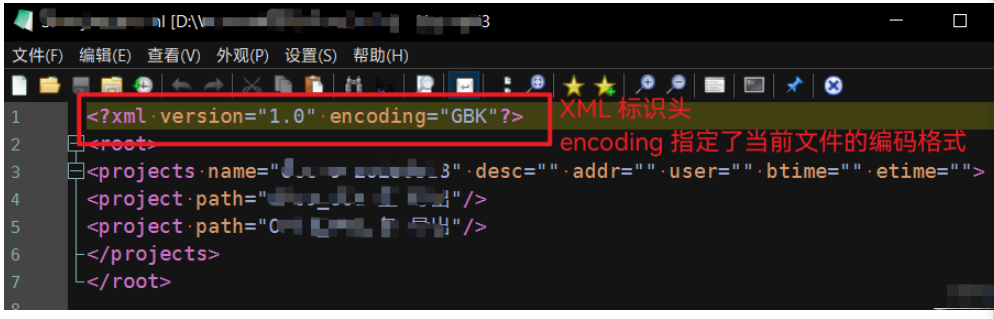 Python中怎么对XML文件的编码进行转换May 21, 2023 pm 12:22 PM
Python中怎么对XML文件的编码进行转换May 21, 2023 pm 12:22 PM1.在Python中XML文件的编码问题1.Python使用的xml.etree.ElementTree库只支持解析和生成标准的UTF-8格式的编码2.常见GBK或GB2312等中文编码的XML文件,用以在老旧系统中保证XML对中文字符的记录能力3.XML文件开头有标识头,标识头指定了程序处理XML时应该使用的编码4.要修改编码,不仅要修改文件整体的编码,还要将标识头中encoding部分的值修改2.处理PythonXML文件的思路1.读取&解码:使用二进制模式读取XML文件,将文件变为
 深度使用Scrapy:如何爬取HTML、XML、JSON数据?Jun 22, 2023 pm 05:58 PM
深度使用Scrapy:如何爬取HTML、XML、JSON数据?Jun 22, 2023 pm 05:58 PMScrapy是一款强大的Python爬虫框架,可以帮助我们快速、灵活地获取互联网上的数据。在实际爬取过程中,我们会经常遇到HTML、XML、JSON等各种数据格式。在这篇文章中,我们将介绍如何使用Scrapy分别爬取这三种数据格式的方法。一、爬取HTML数据创建Scrapy项目首先,我们需要创建一个Scrapy项目。打开命令行,输入以下命令:scrapys


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

Dreamweaver CS6
視覺化網頁開發工具

SecLists
SecLists是最終安全測試人員的伙伴。它是一個包含各種類型清單的集合,這些清單在安全評估過程中經常使用,而且都在一個地方。 SecLists透過方便地提供安全測試人員可能需要的所有列表,幫助提高安全測試的效率和生產力。清單類型包括使用者名稱、密碼、URL、模糊測試有效載荷、敏感資料模式、Web shell等等。測試人員只需將此儲存庫拉到新的測試機上,他就可以存取所需的每種類型的清單。

Safe Exam Browser
Safe Exam Browser是一個安全的瀏覽器環境,安全地進行線上考試。該軟體將任何電腦變成一個安全的工作站。它控制對任何實用工具的訪問,並防止學生使用未經授權的資源。

EditPlus 中文破解版
體積小,語法高亮,不支援程式碼提示功能

mPDF
mPDF是一個PHP庫,可以從UTF-8編碼的HTML產生PDF檔案。原作者Ian Back編寫mPDF以從他的網站上「即時」輸出PDF文件,並處理不同的語言。與原始腳本如HTML2FPDF相比,它的速度較慢,並且在使用Unicode字體時產生的檔案較大,但支援CSS樣式等,並進行了大量增強。支援幾乎所有語言,包括RTL(阿拉伯語和希伯來語)和CJK(中日韓)。支援嵌套的區塊級元素(如P、DIV),

