
mysql效能優化之max,count優化

- 黄舟原創
- 2017-02-27 11:48:002501瀏覽
附註:在執行SQL語句前加上explain可以查看MySQL的執行計劃
資料庫:MySQL官方提供的sakila資料庫
Max最佳化:
例如:查詢最後支付時間
explain select max(payment_date) from payment \G;

查詢的類型為simple,沒有用到任何索引,掃描行數為1萬多行,用時0.02sec
最佳化方法:
在payment_date欄位建立索引
create index idx_paydate on payment(payment_date);
然後在執行此sql語句,發現:
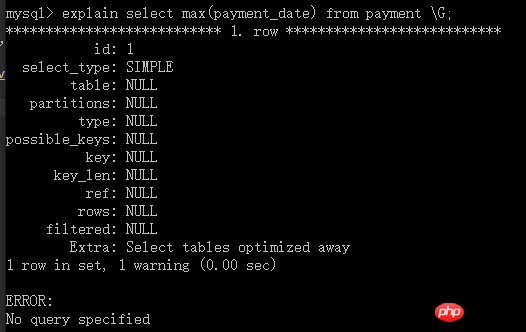
此執行結果的原因為:因為索引是順序排列的,經過索引,就可以馬上知道最後一個是什麼
Count優化
#例如:在一條SQL語句中同時查出2006年和2007年的電影數量分別是多少
錯誤方式:
select count(release_year = '2006' OR release_year = '2007') from film;
無法分開計算2006年和2007年的電影數量
select count(*) from film where release_year = '2006' and release_year = '2007'
release_year不能同時為2006和2007,因此邏輯上有誤
查詢最佳化如下:
select count(release_year='2006' or null) as '2006年的电影数量',count(release_year='2007' or null) as '2007年的电影数量' from film;
說明,在sql中,count(*)和count(某列) ,執行結果有時候會是不一樣的,因為,count(*)包含為null的,而另一個如果為null的話,則不計數在內。
利用這個特性,將為不是2006年的記為null,執行結果如下圖所示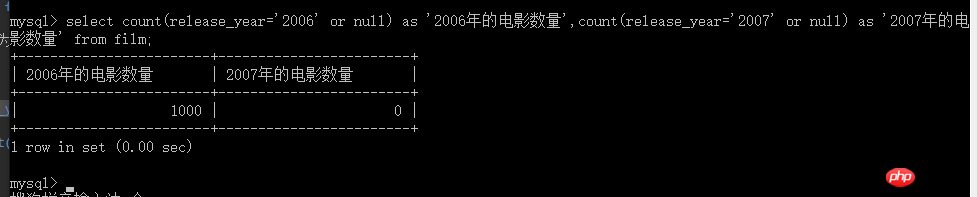
#註:在執行SQL語句前加上explain可以查看MySQL的執行計畫
資料庫:MySQL官方提供的sakila資料庫
Max優化:
例如:查詢最後付款時間
explain select max(payment_date) from payment \G;
查詢的類型為simple,沒有用到任何索引,掃描行數為1萬多行,用時0.02sec
優化方法:
在payment_date列建立索引
create index idx_paydate on payment(payment_date);
然後在執行此sql語句,發現:
此執行結果的原因為:因為索引是順序排列的,透過索引,就可以馬上知道最後一個是什麼
Count優化
例如:在一條SQL語句中同時查出2006年和2007年的電影數量分別是多少
錯誤方式:
select count(release_year = '2006' OR release_year = '2007') from film;
無法分開計算2006年和2007年的電影數量
select count(*) from film where release_year = '2006' and release_year = '2007'
release_year不能同時為2006和2007,因此邏輯上有誤
select count(release_year='2006' or null) as '2006年的电影数量',count(release_year='2007' or null) as '2007年的电影数量' from film;說明,在sql中,
count(*)和count(某一欄),執行結果有時會是不一樣的,因為,count(*)包含為null的,而另一個如果為null的話,則不計數在內。 利用這個特性,將為不是2006年的記為null,執行結果如下圖所示
#